一種基于基音周期和MFCC的融合特征參數提取方法與流程
本發明提出了一種利用基音周期特征參數來增加Mel倒譜參數維度進而提高聲紋識別效率的方法。使用此方法提取的語音特征更具動態性,同時此特征參數結合了人體的發聲結構及聽覺結構,可以提高聲紋識別的效率。
背景技術:
近年來人們對隱私安全越來越重視,單一的字符型密碼已經無法滿足人們的需求,從而致使聲紋、指紋、虹膜等生物特征識別快速發展。而聲紋因為其易獲取,低成本的特性獲得了很大的重視,市場需求極其廣泛。但是聲紋識別同時也有一些缺點,比如同一個人的聲音具有易變性,易受身體狀況、年齡、情緒等的影響;比如不同的麥克風和信道對識別性能有影響;比如環境噪音對識別有干擾;又比如混合說話人的情形下人的聲紋特征不易提取等等。因此尋找更有效的語音特征成為了聲紋識別的首要任務。本方法結合了較為常用的兩個語音特征基音周期和MFCC(Mel Frequency Cepstral Coefficents梅爾頻率倒譜系數)。基音周期是根據人體發聲器官提取的特征,獲取容易,但是人體在情緒發生變化或者生病的時候聲道會發怔變化,因此基音周期是不穩定的。所以我們又引入了相對更加穩定的Mel頻率倒譜參數(MFCC)。Mel頻率是基于人耳聽覺特性而提出來的,它與Hz頻率成非線性對應關系。Mel頻率倒譜系數(MFCC)則是利用它們之間的這種關系,計算得到的Hz頻譜特征,代表根據人體聲音的接收器官提取出的特征。而Mel頻率倒譜參數(MFCC)是由每一幀的語音信號得到的,僅代表了該幀的特征,不具動態性,所以一般會在提取出Mel頻率倒譜參數(MFCC)的基礎上,再次提取其一階差分,二階差分,將所得的三種特征結合起來作為新的MFCC特征,使之具有動態特性。大體流程如圖1所示。本方法結合語音的發聲結構和聽覺結構,可以獲得更好的識別效果。
技術實現要素:
本發明最終目的是基于兩種聲紋特征融合Mel倒譜參數及其一階偏導,二階偏導以及基音周期從而生成一個3L+1維度的矢量,結合語音的發聲結構和聽覺結構,從而獲得更好的識別效果。
為實現上述目的,本發明的實施方案如下:
1)獲得單人語音數據;
2)對語音數據進行預處理,包括預加重,分幀加窗等;
3)提取第一幀語音數據,并用自相關法獲得其基音周期參數P;
4)計算獲得第一幀語音數據的MFCC特征參數M;
5)判斷如果不是最后一幀的話則計算下一幀的基音周期和MFCC參數;
6)遍歷到最后一幀,獲得每一幀的基音周期和MFCC參數;
7)根據每一幀的MFCC特征參數計算其一階偏導F;
8)根據上一步獲得的MFCC特征參數的一階偏導,計算其二階偏導S;
9)將每一幀的MFCC參數及其一階偏導,二階偏導和對應基音周期結合成3X+1維的矢量作為該幀的混合特征參數;
10)后續處理,如訓練和識別;
附圖說明
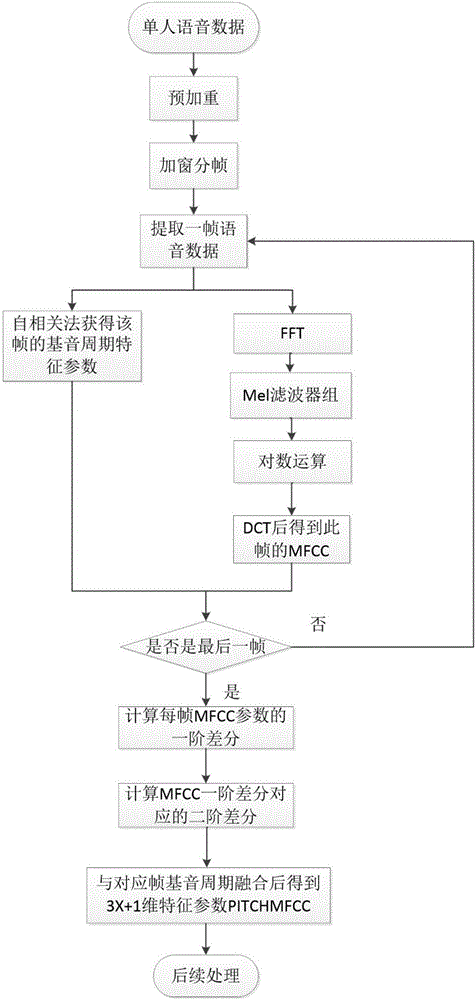
圖1是本發明所述的基于基音周期和MFCC的融合特征參數獲取流程示意圖。圖2是獲取本發明所述基于基音周期和MFCC的融合特征參數的具體流程圖。
具體實施步驟
下面結合說明書附圖中的圖1和圖2及具體實施方式對本發明做進一步詳細說明。需要注意的是,實施步驟中會省略部分已知的功能和描述,而著重突出對本發明的描述。
圖2是本發明基于基音周期和MFCC的融合特征參數的具體處理過程。首先對語音數據進行預加重處理去除低頻,從而突出語音的高頻特性。然后進行分幀加窗處理,根據語音的短時平穩性取10‐30ms一幀,幀間重疊1/2幀長或1/3幀長,再乘上每幀的窗函數來增加語音幀之間的連續性。
然后對預處理后的語音進行處理分別提取基音周期和MFCC參數,具體步驟如下:
1)提取一幀語音數據
2)根據自相關函數計算各幀的基音周期,其中Sn(m)是加窗后的語音信號,k是采樣點間隔個數,m是采樣點數。
3)對分幀加窗后的各幀信號進行FFT變換得到各幀的頻譜,并對語音頻譜平方得到語音信號功率譜。
4)定義一個有M(22‐26)個帶通三角濾波器的濾波器組,將功率譜通過該濾波器組從而將頻譜平滑化。
5)計算每個濾波器組輸出的對數能量,然后將上述對數能量帶入離散余弦變換(DCT),DCT公式如下:求出L階的MFCC參數。此時得到了每一幀的MFCC和基音周期參數。
標準的倒譜參數MFCC只反映了語音參數的靜態特性,語音的動態特性可以用這些靜態特征的差分譜來描述。因此再求的MFCC的一階差分以及二階差分參數。最后將一幀的基音周期,MFCC,一階差分及其二階差分組合起來就得到了3L+1維的融合特征矢量PITCHMFCC。而一段語音有X幀,則可以得到X*(3L+1)維的一個矩陣。并可用于后續的訓練和識別過程。
上述描述了本發明PITCHMFCC具體實施步驟,以便本領域技術研究所人員理解本發明,但應清楚本發明不局限于具體實施方式的范圍,對于各種利用本發明構思的發明均在保護之列。
- 還沒有人留言評論。精彩留言會獲得點贊!