一種語音識別系統的制作方法
本發明涉及語音識別技術領域,尤其涉及一種可以進行在線領域擴展的語音識別系統。
背景技術:
漢語不是拼讀語言,如果沒有上下文信息難以直接從音斷定對應的漢字。傳統的語音識別使用預先生成的靜態解碼網絡進行解碼,并且該解碼網絡通常是從音素直接映射為詞語。該解碼網絡融合了要識別的音頻內容的詞語的概率分布信息。這樣導致識別器從一個領域切換到另外一個領域時,性能會急劇下降,另外一些術語和新詞可能總是無法正確識別。為了支持多個領域的識別,通常用一個模型來同時建模多個領域的詞語的概率分布信息。這導致該模型概率分布比較平均(這意味著識別性能通常也比較平均),并且模型比較龐大。為了支持新詞或者術語的識別,必須重新訓練模型和構造識別器。這是非常耗費時間和資源的。
有鑒于上述的缺陷,本設計人,積極加以研究創新,以期創設一種可以進行在線領域擴展的語音識別系統,使其更具有產業上的利用價值。
技術實現要素:
為解決上述技術問題,本發明的目的是提供一種可以進行在線領域擴展,從而可快速提高特定領域的識別性能的語音識別系統。
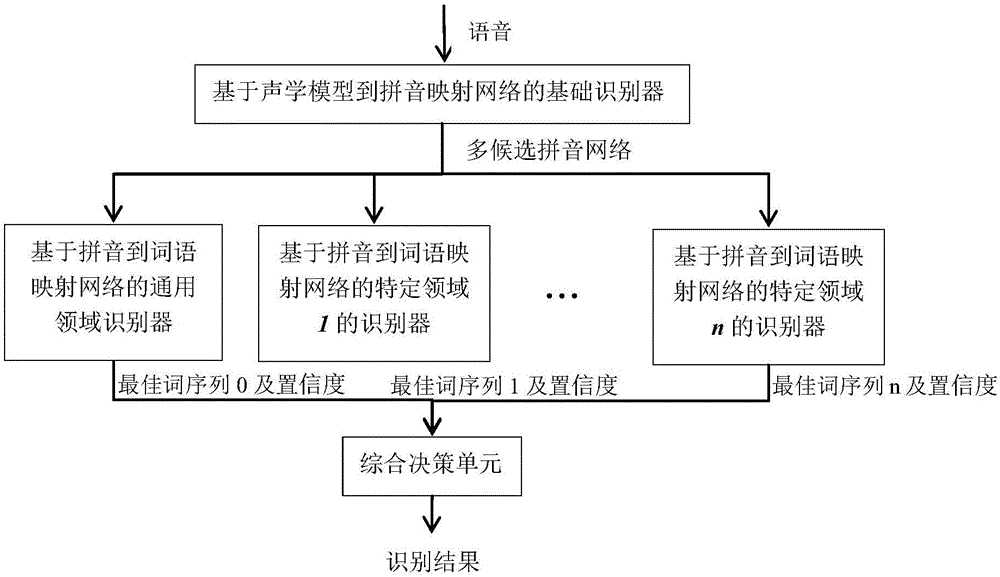
本發明的語音識別系統,包括
-基于聲學模型到拼音映射網絡的基礎識別器,用于將語音映射為由多個候選拼音序列組織成的網絡;
-多個并列的針對不同應用領域的基于拼音到詞語映射網絡的特定識別器,用于分別與由多個候選拼音序列組織成的網絡進行組合,得到多個最佳詞序列及置信度;
-綜合決策單元,用于接收多個最佳詞序列及置信度,然后根據置信度再加上預先給定的先驗知識和規則以及附加知識,進行決策,選擇最佳的詞序列輸出。
進一步的,通過調整拼音到詞語映射網絡,添加新的識別內容到已有領域的基于拼音到詞語映射網絡的特定識別器中,更新已有領域的識別內容;通過離線構造對應的基于拼音到詞語映射網絡的特定識別器,然后將擴展內容在線添加到基于拼音到詞語映射網絡的特定識別器中,創建新的應用領域的識別內容。
進一步的,所述基于聲學模型到拼音映射網絡的基礎識別器根據輸入的音頻特征動態計算聲學得分,并在其網絡上保存有拼音序列的語言模型得分,采用動態規劃算法結合聲學得分和語言模型得分,搜索得分最高的若干拼音序列輸出。
進一步的,所述拼音序列的語言模型采用基于長短時記憶單元的遞歸神經網絡進行建模。
進一步的,所述綜合決策單元通過融合識別置信度、先驗知識和預設規則以及附加信息來選擇最佳候選詞序列。
進一步的,所述先驗知識至少包括所述語音識別系統之外輸入的關于領域的標識信息,或者根據識別結果歷史信息得到的領域標識信息。
進一步的,所述領域標識信息為離散的0/1置,或連續的概率值。
進一步的,所述預設規則至少包括根據音頻長度預估的詞數范圍。
進一步的,所述附加信息包括根據超級語言模型得到的關于識別結果詞串符合語法規范的程度度量。
進一步的,所述綜合決策單元將所述附加信息和預設規則通過分層加權的方式和置信度評分一起作為決策準則來選擇候選詞序列作為最終識別結果輸出。
借由上述方案,本發明可以在線動態地將針對不同領域的基于拼音到詞語映射網絡的特定識別器添加到識別系統中去,可快速提高特定領域的識別性能;可快速定制擴展領域、添加熱詞/新詞、定制領域識別內容;同時支持多個領域的識別,并保證其識別性能不下降。
上述說明僅是本發明技術方案的概述,為了能夠更清楚了解本發明的技術手段,并可依照說明書的內容予以實施,以下以本發明的較佳實施例并配合附圖詳細說明如后。
附圖說明
圖1是本發明的語音識別系統框架圖。
具體實施方式
下面結合附圖和實施例,對本發明的具體實施方式作進一步詳細描述。以下實施例用于說明本發明,但不用來限制本發明的范圍。
參見圖1,本發明一較佳實施例所述的一種語音識別系統,由基本的基于聲學模型到拼音映射網絡的基礎識別器和任意多個針對不同應用領域的基于拼音到詞語映射網絡的特定識別器以及一個綜合決策單元共同組成,其中基于聲學模型到拼音映射網絡的基礎識別器用于將語音映射為由多個候選拼音序列組織成的網絡;各基于拼音到詞語映射網絡的特定識別器用于分別與由多個候選拼音序列組織成的網絡進行組合,得到多個最佳詞序列及置信度;綜合決策單元用于接收多個最佳詞序列及置信度,然后根據置信度再加上預先給定的先驗知識和規則以及附加知識,進行決策,選擇最佳的詞序列輸出。
本發明的針對不同領域的基于拼音到詞語映射網絡的特定識別器可以在線動態添加到識別系統中去,從而可快速提高特定領域的識別性能。本發明中,各基于拼音到詞語映射網絡的特定識別器是并列的,可以快速擴展。具體的,通過調整拼音到詞語映射網絡,添加新的識別內容到已有領域的基于拼音到詞語映射網絡的特定識別器中,更新已有領域的識別內容;通過離線構造對應的基于拼音到詞語映射網絡的特定識別器,然后將擴展內容在線添加到基于拼音到詞語映射網絡的特定識別器中,創建新的應用領域的識別內容。具體應用時,對已有領域的識別內容進行更新,比如新詞/熱詞的添加,只需要調整拼音到詞語映射網絡,無需涉及聲學模型和基本識別器的調整;新的應用領域識別內容的添加,比如:家居控制,車載導航等,只需要離線構造對應的拼音到詞語映射網絡,然后可以在線添加到識別系統中,從而不影響已有領域的識別進程。
本發明中基于聲學模型到拼音映射網絡的基礎識別器根據輸入的音頻特征動態計算聲學得分,并在其網絡上保存有拼音序列的語言模型得分,采用動態規劃算法結合聲學得分和語言模型得分,搜索得分最高的若干拼音序列輸出,且拼音序列的語言模型采用基于長短時記憶單元的遞歸神經網絡進行建模。
本發明中的上述各網絡在系統中具體表現為一個加權有限狀態自動機(WFST,Weighted Finite State Transducers)。通過該自動機可以把輸入的序列映射為另外的序列。在基于聲學模型到拼音映射網絡的基礎識別器中,該網絡上保存了拼音序列的語言模型得分,在解碼過程中,根據輸入的音頻特征動態計算聲學得分,采用動態規劃算法在該WFST網絡中結合聲學得分和語言模型得分,搜索得分最高的若干拼音序列作為多候選結果輸出。
具體實施時,拼音語言模型可以采用基于長短時記憶(LSTM,Long-short Term Memory)單元的遞歸神經網絡(RNN,Recurrent Neural Network)進行建模,這樣加強了拼音上下文的關聯,提高了拼音多候選識別結果的準確性。
本發明中,基于拼音到詞語映射網絡的特定識別器其輸入是表示多候選拼音序列的網絡和拼音到詞語的映射網絡,輸出是最佳詞序列及其之置信度指標。多候選拼音序列網絡可以表示為一個拼音到拼音映射的WFST,而拼音到詞語的映射網絡也表示成一個WFST,其路徑權重為拼音序列到詞序列的映射代價。識別過程首先是對兩個WFST進行組合生成一個新的WFST,然后從該WFST中搜索得分最高的序列,輸出其詞序列和得分。
在本發明中,綜合決策單元接收來自多個基于拼音到詞語映射網絡的特定識別器的輸出,即詞序列及其置信度,然后根據其置信度再加上預先給定的先驗知識和規則以及附加知識,進行決策,選擇最佳的詞序列輸出。特定的,所謂的先驗知識至少包括:識別系統之外輸入的關于領域的標識信息,或者根據識別結果歷史信息得到的領域標識信息。所謂領域標識信息可以是離散的0/1置,也可以是連續的概率值。特定的,所謂的規則至少包括:根據音頻長度預估的詞數范圍。根據詞數范圍,可以排除那些超長或者超短的識別結果。特定的,所謂附加信息可以包括根據超級語言模型得到的關于識別結果詞串符合語法規范的程度度量。上述信息和規則通過分層加權的方式和置信度評分一起作為決策準則來選擇候選詞串作為最終識別結果輸出。
以上所述僅是本發明的優選實施方式,并不用于限制本發明,應當指出,對于本技術領域的普通技術人員來說,在不脫離本發明技術原理的前提下,還可以做出若干改進和變型,這些改進和變型也應視為本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!