音頻信號處理系統和音頻信號處理方法與流程
本發明涉及信號處理技術領域,尤其涉及一種音頻信號處理系統和音頻信號處理方法。
背景技術:
語音交互,已經遍及我們生活的各個領域,如手機、電視、車載、空調等等領域。能夠進行正常語音交互的前提是準確識別語音信號。以手機終端為例,由于環境噪聲的存在,手機終端的麥克風在采集用戶的有效聲源信號的同時,也會采集到環境噪聲信號,這些環境噪聲信號會對有效聲源信號的準確識別造成干擾。
為了提高語音識別的準確性,一種方式是采用麥克風陣列以抑制噪聲的干擾,從而提升語音識別效果,其中一種簡單而常用的是雙麥克風陣列結構。以手機終端為例,雙麥克風陣列由主麥克風和輔麥克風組成,分別設置在手機終端的不同位置,一般地,靠近用戶說話的位置處設置主麥克風,遠離用戶說話的位置設置輔麥克風。其中,主麥克風用于采集語音信號和環境噪聲,輔麥克風采集環境噪聲,兩者信號進行相減運算可以抑制環境噪聲對語音信號的干擾。
目前,在諸如手機終端等場景中,用戶在使用手機終端時,聲音源方位相對固定,從而雙麥克風位置固定,即哪個作為主麥克風哪個作為輔麥克風已經固定設置。但是,隨著各種智能交互產品的不斷問世,語音交互的場景發生了很大改變,聲音源相對智能交互產品的方位不再固定不變,此時,固定設置某個麥克風作為主麥克風、另一麥克風作為輔麥克風已經不能靈活適應智能語音交互場景的需求,很可能導致聲源信號的識別準確性大大降低。
技術實現要素:
有鑒于此,本發明實施例提供一種音頻信號處理系統和音頻信號處理方法,能夠自適應語音交互場景,有助于提高語音識別結果的準確性。
本發明實施例提供一種音頻信號處理系統,包括:
由N個麥克風組成的麥克風陣列,控制器,連接組件,以及降噪組件,N為大于2的整數;其中,
所述N個麥克風呈圓環狀分布;所述降噪組件的輸入端包括N-1個主麥克接口和1個輔麥克接口;
所述N個麥克風分別與所述控制器連接,用于將采集的N路音頻信號輸入所述控制器;
所述控制器通過所述連接組件與所述降噪組件的輸入端連接,用于對所述N路音頻信號進行信號強度比較,根據比較結果控制所述連接組件的輸出端與所述降噪組件的輸入端之間的連接關系。
本發明實施例提供一種音頻信號處理方法,包括:
獲取N路音頻信號,所述N路音頻信號是由N個呈圓環狀分布的麥克風分別采集的,N為大于2的整數;
對所述N路音頻信號進行信號強度比較;
根據信號強度比較結果,確定所述N路音頻信號中的N-1路主音頻信號和1路輔音頻信號;
以所述1路輔音頻信號對所述N-1路主音頻信號進行降噪處理。
本發明實施例提供的音頻信號處理系統和音頻信號處理方法,該系統中包括由N個麥克風組成的圓環形麥克風陣列,控制器,連接組件,以及降噪組件,其中,控制器通過連接組件與降噪組件的N個輸入端連接。當N個麥克風分別采集到音頻信號時,將采集到的N路音頻信號輸入控制器,控制器對N路音頻信號進行信號強度比較,根據比較結果自適應地進行N路音頻信號的主、輔角色定位。具體地,控制器根據N路音頻信號的信號強度比較結果控制連接組件的輸出端與降噪組件的主、輔麥克接口之間的連接關系,從而實現了根據音頻信號強度自適應地切換主、輔麥克接口的輸入信號,以自適應當前的智能語音交互場景,也保證了降噪組件實現更佳的降噪效果,有助于提高語音識別結果的準確性。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作一簡單地介紹,顯而易見地,下面描述中的附圖是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例提供的音頻信號處理系統實施例一的結構示意圖;
圖2為本發明實施例提供的音頻信號處理系統實施例二的結構示意圖;
圖3為本發明實施例提供的音頻信號處理方法實施例一的流程圖。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
在本發明實施例中使用的術語是僅僅出于描述特定實施例的目的,而非旨在限制本發明。在本發明實施例和所附權利要求書中所使用的單數形式的“一種”、“所述”和“該”也旨在包括多數形式,除非上下文清楚地表示其他含義,“多種”一般包含至少兩種,但是不排除包含至少一種的情況。
應當理解,本文中使用的術語“和/或”僅僅是一種描述關聯對象的關聯關系,表示可以存在三種關系,例如,A和/或B,可以表示:單獨存在A,同時存在A和B,單獨存在B這三種情況。另外,本文中字符“/”,一般表示前后關聯對象是一種“或”的關系。
應當理解,盡管在本發明實施例中可能采用術語第一、第二、第三等來描述XXX,但這些XXX不應限于這些術語。這些術語僅用來將XXX彼此區分開。例如,在不脫離本發明實施例范圍的情況下,第一XXX也可以被稱為第二XXX,類似地,第二XXX也可以被稱為第一XXX。
取決于語境,如在此所使用的詞語“如果”、“若”可以被解釋成為“在……時”或“當……時”或“響應于確定”或“響應于檢測”。類似地,取決于語境,短語“如果確定”或“如果檢測(陳述的條件或事件)”可以被解釋成為“當確定時”或“響應于確定”或“當檢測(陳述的條件或事件)時”或“響應于檢測(陳述的條件或事件)”。
還需要說明的是,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的商品或者系統不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種商品或者系統所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括所述要素的商品或者系統中還存在另外的相同要素。
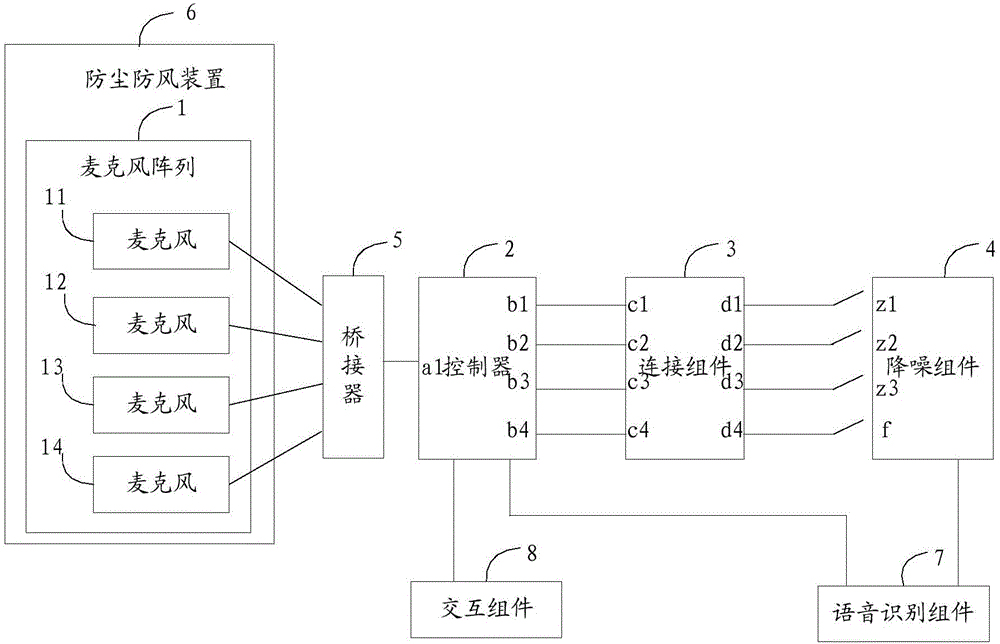
圖1為本發明實施例提供的音頻信號處理系統實施例一的結構示意圖,如圖1所示,該系統包括:
由N個麥克風組成的麥克風陣列1,控制器2,連接組件3,以及降噪組件4,N為大于2的整數。
其中,如圖1所示,該N個麥克風呈圓環狀分布,圖中示意出了該麥克風陣列包括11、12、13、14四個麥克風。
在本實施例中,該圓環形狀的麥克風陣列為全向麥克風陣列,即通過該圓環形狀的麥克風陣列可以接收全方位的音頻信號。
在實際應用中,這N個麥克風可以是均勻分布的,也可以根據實際應用情況非均勻分布,比如結合實際應用場景,如果用戶在某些方位說話的可能性更大,則在該方位上,可以布設比較多的麥克風,在不易說話的方位,布設少量麥克風。
本實施例中提供的上述音頻信號處理系統可以適用于多種智能交互產品中,本實施例中,以應用在智能移動機器人中為例,此時,麥克風陣列1可以被水平設置在機器人機身上的適當位置,比如麥克風陣列1設置在機器人頭部。
當該機器人被啟動語音交互功能后,麥克風陣列1用于采集用戶交互語音。
如圖1所示,N個麥克風分別與控制器2連接,用于將采集的N路音頻信號輸入控制器2。在一種可選連接方式中,N個麥克風可以直接與控制器2連接,此時,如圖1所示,在包含11、12、13、14四個麥克風的舉例中,這四個麥克風分別連接到控制器2的a1、a2、a3、a4四個輸入端。
本實施例中,控制器2進一步通過連接組件3與降噪組件4的輸入端連接,其中,降噪組件4的輸入端包括N-1個主麥克接口和1個輔麥克接口。具體地,如圖1中示意的,控制器2的四個輸出端b1、b2、b3、b4分別與連接組件3的四個輸入端c1、c2、c3、c4對應固定連接,連接組件3的四個輸出端d1、d2、d3、d4則可以切換與降噪組件4的N-1個主麥克接口和1個輔麥克接口之間的連接關系,圖1中,以z1、z2、z3示意主麥克接口,以f示意輔麥克接口。
可選地,該連接組件3可以實現為N個開關。
在實際應用中,當某個用戶開始說話時,觸發N個麥克風采集音頻信號,將采集的N路音頻信號通過控制器2的輸入端輸入給控制器2,進而,控制器2對N路音頻信號進行信號強度比較,根據比較結果控制連接組件3的輸出端與降噪組件4的輸入端之間的連接關系,以將根據信號強度比較結果確定的主音頻信號輸入至降噪組件4的主麥克接口,輔音頻信號輸入至降噪組件4的輔麥克接口。
具體地,控制器2確定信號強度最低的一路音頻信號為輔音頻信號,其他N-1路音頻信號為主音頻信號,從而,控制連接組件3將信號強度最低的一路音頻信號輸入至1個輔麥克接口,將其他的N-1路音頻信號分別輸入至N-1個主麥克接口。
其中,主麥克接口和輔麥克接口可以被視為是對音頻信號的信號屬性的表征。具體來說,可以將從主麥克接口輸入的音頻信號視為聲音源信號,即含有有效語音成分更多的信號,將從輔麥克接口輸入的音頻信號視為噪聲信號,從而觸發降噪組件4根據輔麥克接口輸入的音頻信號對從主麥克接口輸入的音頻信號的降噪處理。
具體地,控制器2在接收到N路音頻信號后,可以通過對這N路音頻信號分別進行一定的信號處理,比如放大、濾波等處理,求取這N路音頻信號的信號強度,進行比較。
本實施例中,可選地,控制器2可以使用各種應用專用集成電路(ASIC)、數字信號處理器(DSP)、數字信號處理設備(DSPD)、可編程邏輯器件(PLD)、現場可編程門陣列(FPGA)、微中控元件、微處理器或其他電子元件實現。
本實施例提供的音頻信號處理系統中包括由N個麥克風組成的圓環形麥克風陣列,控制器,連接組件,以及降噪組件,其中,控制器通過連接組件與降噪組件的N個輸入端連接。當N個麥克風分別采集到音頻信號時,將采集到的N路音頻信號輸入控制器,控制器對N路音頻信號進行信號強度比較,根據比較結果自適應地進行N路音頻信號的主、輔角色定位。具體地,控制器根據N路音頻信號的信號強度比較結果控制連接組件的輸出端與降噪組件的主、輔麥克接口之間的連接關系,從而實現了根據音頻信號強度自適應地切換主、輔麥克接口的輸入信號,以自適應當前的智能語音交互場景,也保證了降噪組件實現更佳的降噪效果,有助于提高語音識別結果的準確性。
圖2為本發明實施例提供的音頻信號處理系統實施例二的結構示意圖,如圖2所示,在圖1所示實施例基礎上,可選地,該系統還包括:
分別與N個麥克風和控制器2連接的橋接器5,其中:
橋接器5,用于將N路音頻信號轉換為一路音頻信號傳輸給控制器2;
控制器2還用于:將一路音頻信號還原為N路音頻信號。
由于支持多路音頻信號輸入的控制器成本較貴,且接口數量很有限,為了降低成本以及避免控制器接口數量的限制,本實施例中提供了上述橋接器5。
如圖2所示,由于橋接器5具有N個音頻信號輸入端口和一個音頻信號輸出端口,其分別接收N路音頻信號,將N路音頻信號轉換為一路后,輸入給控制器2,控制器2為了接收N路音頻信號只需要設置一個輸入接口a1即可,實現方便、成本低廉。而橋接器可以選擇一個CPLD或者FPGA就可以方便實現。
可選地,該系統還包括:防塵防風裝置6。其中,麥克風陣列1安裝在防塵防風裝置6內。
本實施例中,為了物理上盡量保證環境因素對語音識別結果的不利影響,在麥克風陣列的組裝工藝上提供了防塵防風裝置6,以盡量降低環境因素對語音識別結果的不利影響。
其中,防塵防風裝置6中比如包括防風棉、防塵網等結構,以降低風聲、粉塵對麥克風陣列的影響。
可選地,該系統還包括:語音識別組件7和交互組件8。
其中,語音識別組件7分別與降噪組件4的輸出端和控制器2連接,用于對降噪后的音頻信號進行語音識別,將語音識別結果輸入給控制器2。
控制器2還用于根據語音識別結果控制交互組件8進行相應的交互反饋。
本發明實施例提供的音頻信號處理系統一般適用于智能語音交互的產品中,為了實現智能語音交互功能,在通過降噪組件4對輸入的N路音頻信號進行了降噪處理后,降噪后的音頻信號輸入給語音識別組件7,以完成用戶輸入語音的語音識別處理。同時,為了實現基于語音的智能交互,以機器人為例,需要基于語音識別結果向用戶進行相應的反饋。本實施例中,以機器人為例,該交互組件8比如可以是語音播放器,控制器2可以基于語音識別結果通過語音播放器向用戶反饋應答語音;再比如可以是顯示屏,控制器2可以基于語音識別結果通過顯示屏向用戶反饋某種業務操作界面;再比如還可以是運動部件,控制器2可以基于語音識別結果通過控制運動部件使機器人執行相應的反饋動作,等等。
圖3為本發明實施例提供的音頻信號處理方法實施例一的流程圖,本實施例提供的該音頻信號處理方法可以由一音頻信號處理系統來執行,該音頻信號處理系統可以實現為硬件,或者實現為軟件和硬件的組合,該音頻信號處理系統可以集成設置比如移動機器人等語音交互設備中,比如可以是圖1、圖2所示的系統結構。如圖3所示,該方法包括如下步驟:
步驟101、獲取N路音頻信號,N路音頻信號是由N個呈圓環狀分布的麥克風分別采集的。
其中,N為大于2的整數。
步驟102、對N路音頻信號進行信號強度比較。
步驟103、根據信號強度比較結果,確定N路音頻信號中的N-1路主音頻信號和1路輔音頻信號。
步驟104、以該1路輔音頻信號對N-1路主音頻信號進行降噪處理。
具體地,根據信號強度比較結果,確定N路音頻信號中的N-1路主音頻信號和1路輔音頻信號,包括:
根據信號強度的比較結果,確定信號強度最低的一路音頻信號為輔音頻信號,其他N-1路音頻信號為主音頻信號。
本實施例提供的音頻信號處理方法的具體適用場景和詳細過程,可以參見前述系統實施例中的說明,在此不贅述。
以上所描述的系統實施例僅僅是示意性的,其中所述作為分離部件說明的單元(諸如各種組件、裝置等)可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部模塊來實現本實施例方案的目的。本領域普通技術人員在不付出創造性的勞動的情況下,即可以理解并實施。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到各實施方式可借助加必需的通用硬件平臺的方式來實現,當然也可以通過硬件。基于這樣的理解,上述技術方案本質上或者說對現有技術做出貢獻的部分可以以產品的形式體現出來,該計算機產品可以存儲在計算機可讀存儲介質中,如ROM/RAM、磁碟、光盤等,包括若干指令用以使得一臺計算機裝置(可以是個人計算機,服務器,或者網絡裝置等)執行各個實施例或者實施例的某些部分所述的方法。
最后應說明的是:以上實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的精神和范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!