一種多媒體數據處理方法及其裝置與流程
本發明涉及多媒體技術領域,尤其涉及一種多媒體數據處理方法及其裝置。
背景技術:
歌曲一般由一定結構性的段落如前奏,兩段主歌,一段副歌,過門音樂,重復一次的副歌和主歌,以及結尾音樂順序地連接而成的。副歌,通常是我們口頭所說的音樂的高潮部分,作為一首歌曲的標志,常常可應用于音樂試聽、手機彩鈴等等。在一些歌曲處理過程中,也經常需要對副歌進行分析和處理,比如確定歌曲基調,音樂搜索,樂曲識別等等。
由于歌曲中信號的復雜性和不同歌曲之間的差異性,為副歌定位帶來了很多困難。現有的副歌檢測方法主要包括以下方式:歌詞或樂譜檢測法,通過對歌詞的相似性進行檢測或根據樂譜特征進行檢測,該方法對歌詞或樂譜依賴性較高且準確度不高;音頻特征檢測法,例如通過重復片段或節拍等規律來檢測副歌的位置,只能適用于特征規律的歌曲,難以滿足較為復雜性的歌曲的副歌定位。因此,如何準確地對歌曲的副歌進行定位,成為當前亟需解決的關鍵問題。
技術實現要素:
本發明實施例提供一種多媒體數據處理方法及其裝置,可以完成對副歌的準確定位。
本發明實施例第一方面提供了一種多媒體數據處理方法,可包括:
獲取多媒體數據對應的多個音頻文件樣本,并生成各音頻文件樣本分別對應的目標音頻能量矩陣;各音頻文件樣本中的幀數相同;每個目標音頻能量矩陣中的各元素分別為所述目標音頻文件樣本中各幀的音頻能量值;
對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,所述目標均值化矩陣中的各元素為各幀的音頻能量平均值;
將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻。
本發明實施例第二方面提供了一種多媒體數據處理裝置,可包括:
樣本獲取單元,用于獲取多媒體數據對應的多個音頻文件樣本;
矩陣生成單元,生成各音頻文件樣本分別對應的目標音頻能量矩陣;各音頻文件樣本中的幀數相同;每個目標音頻能量矩陣中的各元素分別為所述目標音頻文件樣本中各幀的音頻能量值;
均值化處理單元,用于對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,所述目標均值化矩陣中的各元素為各幀的音頻能量平均值;
幀確定單元,用于將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀;
副歌起始單元,用于根據所述目標幀確定所述多媒體數據的副歌起始時刻。
在本發明實施例中,可通過獲取多媒體數據對應的多個音頻文件樣本,并生成各音頻文件樣本分別對應的目標音頻能量矩陣,然后對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,并將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻,完成對多媒體數據的副歌的準確定位。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明實施例提供的一種多媒體數據處理方法的流程示意圖;
圖2是本發明實施例提供的另一種多媒體數據處理方法的流程示意圖;
圖3是本發明實施例提供的一種多媒體數據處理裝置的結構示意圖;
圖4是本發明實施例提供的另一種多媒體數據處理裝置的結構示意圖;
圖5是本發明實施例提供的矩陣生成單元的結構示意圖;
圖6是本發明實施例提供的副歌起始單元的結構示意圖;
圖7是本發明實施例提供的又一種多媒體數據處理裝置的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
下面將結合附圖1-附圖2,對本發明實施例提供的多媒體數據處理方法進行詳細介紹。
請參見圖1,為本發明實施例提供的一種多媒體數據處理方法的流程示意圖。如圖1所示,本發明實施例的所述方法可以包括以下步驟S101-步驟S103。
S101,獲取多媒體數據對應的多個音頻文件樣本,并生成各音頻文件樣本分別對應的目標音頻能量矩陣。
具體的,由于當前一些歌曲類應用軟件較為普及,用戶可以通過這些軟件演唱歌曲并進行存儲或處理,因此這些應用的應用數據庫中,會存儲有大量的用戶演唱數據。本發明實施例可以基于上述數據進行副歌定位。如通過在數據庫中獲取任意選取一首歌曲(多媒體數據)中的多個用戶演唱的音頻文件,或者是任意一首歌曲的某個用戶演唱的多個音頻文件,作為該多媒體數據對應的多個音頻文件樣本。
本發明實施例中,第n個音頻文件樣本可采用Sn(n=1,2,3.....N)來表示,假設音頻數據長度為L(標準長度,可以以原唱歌曲長度為準),設定幀長為FL,確定音頻數據幀個數M(M=L/FL,當樣本Sn的實際數據長度L’≠L時,可以統一補零或截斷,以使L’=L),各音頻文件樣本中的幀數相同,且每個目標音頻能量矩陣中的各元素分別為所述目標音頻文件樣本中各幀的音頻能量值,即樣本Sn(n=1,2,3.....N)對應的目標音頻能量矩陣En為:
S1:E1={E1(1),E1(2),E1(3),......,E1(M)};
S2:E2={E2(1),E2(2),E2(3),......,E2(M)};
S3:E3={E3(1),E3(2),E3(3),......,E3(M)};
.......
SN:EN={EN(1),EN(2),EN(3),......,EN(M)}。
其中,En(K)表示樣本Sn中的第K幀的音頻能量值,K=1,2,3.....M。
S102,對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣。
具體的,對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,所述目標均值化矩陣中的各元素為各幀的音頻能量平均值。本發明實施例中,生成各音頻文件樣本分別對應的目標音頻能量矩陣之后,可以對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,均值化處理具體過程包括:將E1~EN中的各元素分別按幀進行疊加,并除以幀個數N,即
Er(1)=(E1(1)+E2(1)+E3(1)+......+EN(1))/N;
Er(2)=(E1(2)+E2(2)+E3(2)+......+EN(2))/N;
......
Er(M)=(E1(M)+E2(M)+E3(M)+......+EN(M))/N;
其中,目標均值化矩陣用Er表示,Er={Er(1),Er(2),Er(3),......,Er(M)}。
S103,將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻。
具體的,將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻。本發明實施例中,假設Er(3)為最大音頻能量平均值,則將Er(3)對應的幀確定為目標幀,即第三幀確定為目標幀。根據目標幀確定所述多媒體數據的副歌起始時刻的計算公式(1)為:
TK=K*FL/fs (1)
其中,TK表示多媒體數據的副歌起始時刻,K表示第幾幀,fs為音頻文件的采樣率。
在本發明實施例中,可通過獲取多媒體數據對應的多個音頻文件樣本,并生成各音頻文件樣本分別對應的目標音頻能量矩陣,然后對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,并將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻,完成對多媒體數據的副歌的準確定位。
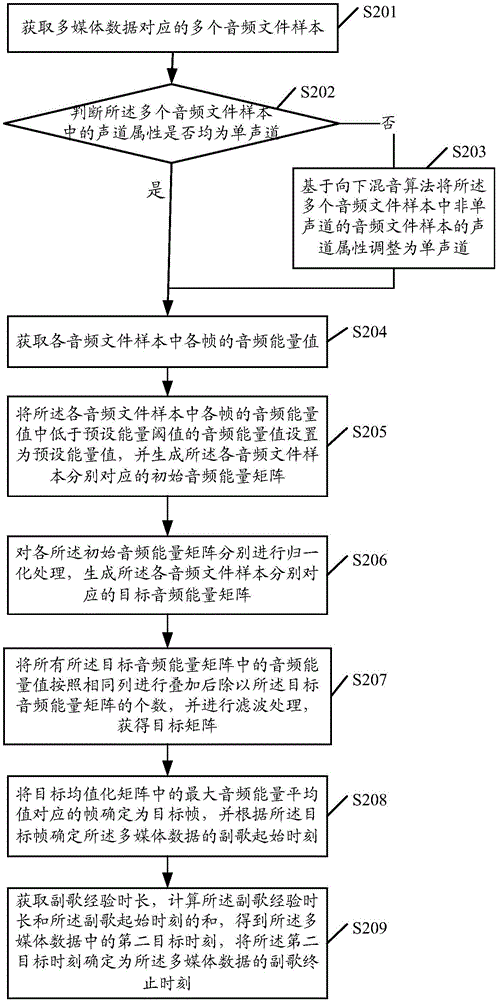
請參見圖2,為本發明實施例提供的另一種多媒體數據處理方法的流程示意圖。如圖2所示,所述方法可以包括以下步驟S201-步驟S209。
S201,獲取多媒體數據對應的多個音頻文件樣本。
具體的,由于當前一些歌曲類應用軟件較為普及,用戶可以通過這些軟件演唱歌曲并進行存儲或處理,因此這些應用的應用數據庫中,會存儲有大量的用戶演唱數據。本發明實施例可以基于上述數據進行副歌定位。如通過在數據庫中獲取任意選取一首歌曲(多媒體數據)中的多個用戶演唱的音頻文件,或者是任意一首歌曲的某個用戶演唱的多個音頻文件,作為該多媒體數據對應的多個音頻文件樣本。
S202,判斷所述多個音頻文件樣本中的聲道屬性是否均為單聲道。
具體的,聲道是指聲音在錄制或播放時在不同空間位置采集或回放的相互獨立的音頻信號,由于錄制時存在音源數量不同,多個音頻文件樣本中可能會出現一個或多個為非單聲道的樣本,這時,需要執行步驟S203,若多個音頻文件樣本的聲道屬性均為單聲道,則可以執行步驟S204。
S203,若否,基于向下混音算法將所述多個音頻文件樣本中非單聲道的音頻文件樣本的聲道屬性調整為單聲道。
具體的,若所述多個音頻文件樣本中存在聲道屬性為非單聲道的音頻文件樣本,例如存在一個或多個雙聲道的音頻文件,則可以基于向下混音算法將聲道屬性為非單聲道的音頻文件樣本的聲道屬性調整為單聲道。
S204,獲取各音頻文件樣本中各幀的音頻能量值。
具體的,本發明實施例中,第n個音頻文件樣本可采用Sn(n=1,2,3.....N)來表示,假設音頻數據長度為L(標準長度,可以以原唱歌曲長度為準),設定幀長為FL,將確定音頻數據幀個數M(M=L/FL,當樣本Sn的實際數據長度L’≠L時,可以統一補零或截斷,以使L’=L),各音頻文件樣本中的幀數相同,可獲取各音頻文件樣本中各幀的音頻能量值,能量值計算公式(2)為:
其中,x(i)(i=0,1,2......N’)為每幀中的各個數據點的能量值,En(K)表示樣本Sn中的第K幀的音頻能量值,K=1,2,3.....M。
具體獲取方式可以是:將各幀分別按照正常幀長FL分為多個數據點,獲取每幀中的各個數據點的能量值x(i),然后按計算公式獲取各幀的能量值En(K)。
S205,將所述各音頻文件樣本中各幀的音頻能量值中低于預設能量閾值的音頻能量值設置為預設能量值,并生成所述各音頻文件樣本分別對應的初始音頻能量矩陣。
具體的,本發明實施例中,預設能量閾值可以用Te表示,將所有En(K)與Te進行比較,小于該Te的將其設置為預設能量值(例如0),假設E1(1),E1(2),E1(3)均小于Te,則生成的各音頻文件樣本分別對應的初始音頻能量矩陣En’為:
S1:E1’={0,0,0,......,E1(M)};
S2:E2’={E2(1),E2(2),E2(3),......,E2(M)};
S3:E3’={E3(1),E3(2),E3(3),......,E3(M)};
.......
SN:EN’={EN(1),EN(2),EN(3),......,EN(M)}。
S206,對各所述初始音頻能量矩陣分別進行歸一化處理,生成所述各音頻文件樣本分別對應的目標音頻能量矩陣。
具體的,本發明實施例中,對各所述初始音頻能量矩陣分別進行歸一化處理,歸一化公式為:
E’N(M)=EN(M)/ENmax (3)
其中,E’N(M)為歸一化后的各幀的能量值,E’N(M)∈[0,1]。
S207,將所有所述目標音頻能量矩陣中的音頻能量值按照相同列進行疊加后除以所述目標音頻能量矩陣的個數,并進行濾波處理,獲得目標矩陣。
具體的,將所有所述目標音頻能量矩陣中的音頻能量值按照相同列(例如,E’1(1),E’2(1)......和E’N(1)為相同列上的音頻能量值)進行疊加后除以所述目標音頻能量矩陣的個數(假設為N),并進行濾波處理,獲得目標矩陣,所述目標音頻能量矩陣中的每列上的元素為每幀對應的音頻能量值,即
E’r(1)=(E’1(1)+E’2(1)+E’3(1)+......+E’N(1))/N;
E’r(2)=(E’1(2)+E’2(2)+E’3(2)+......+E’N(2)/N;
......
E’r(M)=(E’1(M)+E’2(M)+E’3(M)+......+E’N(M)/N;
其中,目標均值化矩陣用E’r表示,E’r={E’r(1),E’r(2),E’r(3),......,E’r(M)}。進一步地,可以對E’r進行均值濾波或者中值濾波,濾波器階數為I,I的取值可以為7(具體可根據經驗選用)。
S208,將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻。
具體的,本發明實施例中,假設E’r(3)為最大音頻能量平均值,則將E’r(3)對應的幀確定為目標幀,即第三幀確定為目標幀。通過獲取預設幀長、預設采樣率和目標幀的位置信息,計算所述多媒體數據的第一目標時刻,將所述第一目標時刻確定為所述多媒體數據的副歌起始時刻。根據目標幀確定所述多媒體數據的副歌起始時刻的計算公式(1)為:
TK=K*FL/fs (1)
其中,TK表示多媒體數據的副歌起始時刻,K表示第幾幀,fs為音頻文件的采樣率。
S209,獲取副歌經驗時長,計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻,將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻。
具體的,獲取副歌經驗時長,計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻,將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻。多媒體數據的副歌終止時刻(即第二目標時刻)Tover的計算公式(4)為:
Tover=TK+Toffset (4)
其中,Toffset為副歌經驗時長,TK為多媒體數據的副歌起始時刻。
在本發明實施例中,可以通過獲取多媒體數據對應的多個音頻文件樣本,并判斷所述多個音頻文件樣本中的聲道屬性是否均為單聲道,若否,基于向下混音算法將所述多個音頻文件樣本中非單聲道的音頻文件樣本的聲道屬性調整為單聲道,然后獲取各音頻文件樣本中各幀的音頻能量值,將所述各音頻文件樣本中各幀的音頻能量值中低于預設能量閾值的音頻能量值設置為預設能量值,并生成所述各音頻文件樣本分別對應的初始音頻能量矩陣,對各所述初始音頻能量矩陣分別進行歸一化處理,生成所述各音頻文件樣本分別對應的目標音頻能量矩陣,將所有所述目標音頻能量矩陣中的音頻能量值按照相同列進行疊加后除以所述目標音頻能量矩陣的個數,并進行濾波處理,獲得目標矩陣,將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻,進一步可獲取副歌經驗時長,計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻,將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻,完成對多媒體數據的副歌的起始時刻和終止時刻進行定位。
下面將結合附圖3-附圖7,對本發明實施例提供的多媒體數據處理裝置進行詳細接收。需要說明的是,附圖3-附圖7所示的多媒體數據處理裝置,用于執行本發明圖1-圖2所示實施例的方法,為了便于說明,僅示出了與本發明實施例相關的部分,具體技術細節未揭示的,請參照本發明圖1-圖2所示的實施例。
請參見圖3,為本發明實施例提供的一種多媒體數據處理裝置的結構示意圖。如圖3所示,本發明實施例的所述多媒體數據處理裝置1可以包括:樣本獲取單元11、矩陣生成單元12、均值化處理單元13、幀確定單元14和副歌起始單元15。
樣本獲取單元11,用于獲取多媒體數據對應的多個音頻文件樣本。
具體的,由于當前一些歌曲類應用軟件較為普及,用戶可以通過這些軟件演唱歌曲并進行存儲或處理,因此這些應用的應用數據庫中,會存儲有大量的用戶演唱數據。本發明實施例可以基于上述數據進行副歌定位。如樣本獲取單元11可通過在數據庫中獲取任意選取一首歌曲(多媒體數據)中的多個用戶演唱的音頻文件,或者是任意一首歌曲的某個用戶演唱的多個音頻文件,作為該多媒體數據對應的多個音頻文件樣本。
矩陣生成單元12,生成各音頻文件樣本分別對應的目標音頻能量矩陣,各音頻文件樣本中的幀數相同,每個目標音頻能量矩陣中的各元素分別為所述目標音頻文件樣本中各幀的音頻能量值。
具體的,第n個音頻文件樣本可采用Sn(n=1,2,3.....N)來表示,假設音頻數據長度為L(標準長度,可以以原唱歌曲長度為準),設定幀長為FL,矩陣生成單元12確定音頻數據幀個數M(M=L/FL,當樣本Sn的實際數據長度L’≠L時,可以統一補零或截斷,以使L’=L),各音頻文件樣本中的幀數相同,且每個目標音頻能量矩陣中的各元素分別為所述目標音頻文件樣本中各幀的音頻能量值,即樣本Sn(n=1,2,3.....N)對應的目標音頻能量矩陣En為:
S1:E1={E1(1),E1(2),E1(3),......,E1(M)};
S2:E2={E2(1),E2(2),E2(3),......,E2(M)};
S3:E3={E3(1),E3(2),E3(3),......,E3(M)};
.......
SN:EN={EN(1),EN(2),EN(3),......,EN(M)}。
其中,En(K)表示樣本Sn中的第K幀的音頻能量值,K=1,2,3.....M。
均值化處理單元13,用于對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,所述目標均值化矩陣中的各元素為各幀的音頻能量平均值。
具體的,均值化處理單元13對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,所述目標均值化矩陣中的各元素為各幀的音頻能量平均值。本發明實施例中,均值化處理單元13生成各音頻文件樣本分別對應的目標音頻能量矩陣之后,可以對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,均值化處理具體過程包括:將E1~EN中的各元素分別按幀進行疊加,并除以幀個數N,即
Er(1)=(E1(1)+E2(1)+E3(1)+......+EN(1))/N;
Er(2)=(E1(2)+E2(2)+E3(2)+......+EN(2)/N;
......
Er(M)=(E1(M)+E2(M)+E3(M)+......+EN(M)/N;
其中,目標均值化矩陣用Er表示,Er={Er(1),Er(2),Er(3),......,Er(M)}。
幀確定單元14,用于將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀。
具體的,幀確定單元14將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻。本發明實施例中,假設Er(3)為最大音頻能量平均值,則將Er(3)對應的幀確定為目標幀,即第三幀確定為目標幀。
副歌起始單元15,用于根據所述目標幀確定所述多媒體數據的副歌起始時刻。
具體的,副歌起始單元15根據所述目標幀確定所述多媒體數據的副歌起始時刻。副歌起始單元15根據目標幀確定所述多媒體數據的副歌起始時刻的計算公式(1)為:
TK=K*FL/fs (1)
其中,TK表示多媒體數據的副歌起始時刻,K表示第幾幀,fs為音頻文件的采樣率。
在本發明實施例中,可通過獲取多媒體數據對應的多個音頻文件樣本,并生成各音頻文件樣本分別對應的目標音頻能量矩陣,然后對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,并將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻,完成對多媒體數據的副歌的準確定位。
請參見圖4,為本發明實施例提供的另一種多媒體數據處理裝置的結構示意圖。如圖4所示,本發明實施例的所述多媒體數據處理裝置1除包括圖4所述的單元外,還可以包括:時長獲取單元16、和計算單元17、副歌終止單元18、判斷單元19和調整單元20。
樣本獲取單元11,用于獲取多媒體數據對應的多個音頻文件樣本。
所述樣本獲取單元11所執行的動作的詳細解釋請參考圖3對應的實施例中的相應單元,在此不再贅述。
判斷單元19,用于判斷所述多個音頻文件樣本中的聲道屬性是否均為單聲道。
具體的,聲道是指聲音在錄制或播放時在不同空間位置采集或回放的相互獨立的音頻信號,由于錄制時存在音源數量不同,多個音頻文件樣本中可能會出現一個或多個為非單聲道的樣本,若判斷單元19判斷所述多個音頻文件樣本中的聲道屬性不均為單聲道,即多個音頻文件樣本中存在非單聲道的音頻文件樣本,則調用調整單元20進行調整,若多個音頻文件樣本的聲道屬性均為單聲道,則調用矩陣生成單元12。
調整單元20,用于若所述多個音頻文件樣本中存在聲道屬性為非單聲道的音頻文件樣本,基于向下混音算法將所述多個音頻文件樣本中非單聲道的音頻文件樣本的聲道屬性調整為單聲道。
具體的,若所述多個音頻文件樣本中存在聲道屬性為非單聲道的音頻文件樣本,例如存在一個或多個雙聲道的音頻文件,則調整單元20可以基于向下混音算法將聲道屬性為非單聲道的音頻文件樣本的聲道屬性調整為單聲道。
矩陣生成單元12,用于生成各音頻文件樣本分別對應的目標音頻能量矩陣;各音頻文件樣本中的幀數相同。
具體的,請參見圖5,,圖5為本發明實施例提供的矩陣生成單元的結構示意圖,所述矩陣生成單元12具體包括:能量值獲取子單元121、設置子單元122、生成子單元123和歸一化處理子單元124。
能量值獲取子單元121,用于獲取各音頻文件樣本中各幀的音頻能量值。
具體的,本發明實施例中,第n個音頻文件樣本可采用Sn(n=1,2,3.....N)來表示,假設音頻數據長度為L(標準長度,可以以原唱歌曲長度為準),設定幀長為FL,將確定音頻數據幀個數M(M=L/FL,當樣本Sn的實際數據長度L’≠L時,可以統一補零或截斷,以使L’=L),各音頻文件樣本中的幀數相同,能量值獲取子單元121可獲取各音頻文件樣本中各幀的音頻能量值,能量值計算公式(2)為:
其中,x(i)(i=0,1,2......N’)為每幀中的各個數據點的能量值,En(K)表示樣本Sn中的第K幀的音頻能量值,K=1,2,3.....M。
具體獲取方式可以是:將各幀分別按照正常幀長FL分為多個數據點,能量值獲取子單元121獲取每幀中的各個數據點的能量值x(i),然后按計算公式獲取各幀的能量值En(K)。
設置子單元122,用于將所述各音頻文件樣本中各幀的音頻能量值中低于預設能量閾值的音頻能量值設置為預設能量值。
生成子單元123,用于生成所述各音頻文件樣本分別對應的初始音頻能量矩陣。
具體的,本發明實施例中,預設能量閾值可以用Te表示,設置子單元122將所有En(K)與Te進行比較,小于該Te的將其設置為預設能量值(例如0),假設E1(1),E1(2),E1(3)均小于Te,則生成子單元123生成的各音頻文件樣本分別對應的初始音頻能量矩陣En’為:
S1:E1’={0,0,0,......,E1(M)};
S2:E2’={E2(1),E2(2),E2(3),......,E2(M)};
S3:E3’={E3(1),E3(2),E3(3),......,E3(M)};
.......
SN:EN’={EN(1),EN(2),EN(3),......,EN(M)}。
歸一化處理子單元124,用于對各所述初始音頻能量矩陣分別進行歸一化處理,生成所述各音頻文件樣本分別對應的目標音頻能量矩陣。
具體的,本發明實施例中,歸一化處理子單元124對各所述初始音頻能量矩陣分別進行歸一化處理,歸一化公式為:
E’N(M)=EN(M)/ENmax (3)
其中,E’N(M)為歸一化后的各幀的能量值,E’N(M)∈[0,1]。
均值化處理單元13,用于將所有所述目標音頻能量矩陣中的音頻能量值按照相同列進行疊加后除以所述目標音頻能量矩陣的個數,并進行濾波處理,獲得目標矩陣。
具體的,均值化處理單元13將所有所述目標音頻能量矩陣中的音頻能量值按照相同列(例如,E’1(1),E’2(1)......和E’N(1)為相同列上的音頻能量值)進行疊加后除以所述目標音頻能量矩陣的個數(假設為N),并進行濾波處理,獲得目標矩陣,所述目標音頻能量矩陣中的每列上的元素為每幀對應的音頻能量值,即
E’r(1)=(E’1(1)+E’2(1)+E’3(1)+......+E’N(1))/N;
E’r(2)=(E’1(2)+E’2(2)+E’3(2)+......+E’N(2)/N;
......
E’r(M)=(E’1(M)+E’2(M)+E’3(M)+......+E’N(M)/N;
其中,目標均值化矩陣用E’r表示,E’r={E’r(1),E’r(2),E’r(3),......,E’r(M)}。進一步地,可以對E’r進行均值濾波或者中值濾波,濾波器階數為I,I的取值可以為7(具體可根據經驗選用)。
幀確定單元14,用于將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,
所述幀確定單元14所執行的動作的詳細解釋請參考圖3對應的實施例中的相應單元,在此不再贅述。
副歌起始單元15,用于根據所述目標幀確定所述多媒體數據的副歌起始時刻。
如圖6所示,圖6為本發明實施例提供的副歌起始單元的結構示意圖,所述副歌起始單元15包括信息獲取子單元151、計算子單元152和確定子單元153。
信息獲取子單元151,用于獲取預設幀長、預設采樣率和目標幀的位置信息。
計算子單元152,用于根據所述預設幀長、所述預設采樣率和所述目標幀的位置信息計算所述多媒體數據的第一目標時刻。
確定子單元153,用于將所述第一目標時刻確定為所述多媒體數據的副歌起始時刻。
具體的,根據目標幀確定所述多媒體數據的副歌起始時刻的計算公式(1)為:
TK=K*FL/fs (1)
其中,TK表示多媒體數據的副歌起始時刻,K表示第幾幀,fs為音頻文件的采樣率。
時長獲取單元16,用于獲取副歌經驗時長。
和計算單元17,用于計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻。
副歌終止單元18,用于將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻。
具體的,獲取副歌經驗時長,計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻,將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻。多媒體數據的副歌終止時刻(即第二目標時刻)Tover的計算公式(3)為:
Tover=TK+Toffset (3)
其中,Toffset為副歌經驗時長,TK為多媒體數據的副歌起始時刻。
在本發明實施例中,可以通過獲取多媒體數據對應的多個音頻文件樣本,并判斷所述多個音頻文件樣本中的聲道屬性是否均為單聲道,若否,基于向下混音算法將所述多個音頻文件樣本中非單聲道的音頻文件樣本的聲道屬性調整為單聲道,然后獲取各音頻文件樣本中各幀的音頻能量值,將所述各音頻文件樣本中各幀的音頻能量值中低于預設能量閾值的音頻能量值設置為預設能量值,并生成所述各音頻文件樣本分別對應的初始音頻能量矩陣,對各所述初始音頻能量矩陣分別進行歸一化處理,生成所述各音頻文件樣本分別對應的目標音頻能量矩陣,將所有所述目標音頻能量矩陣中的音頻能量值按照相同列進行疊加后除以所述目標音頻能量矩陣的個數,并進行濾波處理,獲得目標矩陣,將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻,進一步可獲取副歌經驗時長,計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻,將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻,完成對多媒體數據的副歌的起始時刻和終止時刻進行定位。
請參見圖7,為本發明實施例提供的又一種多媒體數據處理裝置的結構示意圖。如圖7所示,本發明實施例的所述多媒體數據處理裝置1000可以包括:至少一個處理器1001,例如CPU,至少一個輸入裝置1002,至少一個輸出裝置1003,存儲器1004,至少一個通信總線1005。其中,通信總線1005用于實現這些組件之間的連接通信。存儲器1003可以是高速RAM存儲器,也可以是非不穩定的存儲器(non-volatile memory),例如至少一個磁盤存儲器。存儲器1003可選的還可以是至少一個位于遠離前述處理器1001的存儲裝置。
在圖7所示的多媒體數據處理裝置1000中,處理器1001可以用于調用存儲器1005中存儲的代碼,并具體執行以下步驟:
獲取多媒體數據對應的多個音頻文件樣本,并生成各音頻文件樣本分別對應的目標音頻能量矩陣;各音頻文件樣本中的幀數相同;每個目標音頻能量矩陣中的各元素分別為所述目標音頻文件樣本中各幀的音頻能量值;
對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標均值化矩陣,所述目標均值化矩陣中的各元素為各幀的音頻能量平均值;
將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻。
在一個實施例中,所述處理器1001在執行生成各音頻文件樣本分別對應的目標音頻能量矩陣步驟時,具體執行以下步驟:
獲取各音頻文件樣本中各幀的音頻能量值;
將所述各音頻文件樣本中各幀的音頻能量值中低于預設能量閾值的音頻能量值設置為預設能量值,并生成所述各音頻文件樣本分別對應的初始音頻能量矩陣;
對各所述初始音頻能量矩陣分別進行歸一化處理,生成所述各音頻文件樣本分別對應的目標音頻能量矩陣。
在一個實施例中,所述處理器1001在執行對所有所述目標音頻能量矩陣中各幀的音頻能量值進行均值化處理,獲得目標矩陣步驟時,具體執行以下步驟:
將所有所述目標音頻能量矩陣中每幀對應的所有音頻能量值進行疊加后除以所述目標音頻能量矩陣的個數,并進行濾波處理,獲得目標矩陣。
在一個實施例中,所述處理器1001在執行根據所述目標幀確定所述多媒體數據的副歌起始時刻步驟時,具體執行以下步驟:
獲取預設幀長、預設采樣率和目標幀的位置信息;
根據所述預設幀長、所述預設采樣率和所述目標幀的位置信息計算所述多媒體數據的第一目標時刻;
將所述第一目標時刻確定為所述多媒體數據的副歌起始時刻。
在一個實施例中,所述處理器1001在執行根據所述目標幀確定所述多媒體數據的副歌起始時刻步驟之后,還執行以下步驟:
獲取副歌經驗時長;
計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻;
將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻。
在一個實施例中,所述處理器1001在執行獲取多媒體數據對應的多個音頻文件樣本步驟之后,還執行以下步驟:
判斷所述多個音頻文件樣本中的聲道屬性是否均為單聲道;
若否,基于向下混音算法將所述多個音頻文件樣本中非單聲道的音頻文件樣本的聲道屬性調整為單聲道。
在本發明實施例中,可以通過獲取多媒體數據對應的多個音頻文件樣本,并判斷所述多個音頻文件樣本中的聲道屬性是否均為單聲道,若否,基于向下混音算法將所述多個音頻文件樣本中非單聲道的音頻文件樣本的聲道屬性調整為單聲道,然后獲取各音頻文件樣本中各幀的音頻能量值,將所述各音頻文件樣本中各幀的音頻能量值中低于預設能量閾值的音頻能量值設置為預設能量值,并生成所述各音頻文件樣本分別對應的初始音頻能量矩陣,對各所述初始音頻能量矩陣分別進行歸一化處理,生成所述各音頻文件樣本分別對應的目標音頻能量矩陣,將所有所述目標音頻能量矩陣中每幀對應的所有音頻能量值進行疊加后除以所述目標音頻能量矩陣的個數,并進行濾波處理,獲得目標矩陣,將所述目標均值化矩陣中的最大音頻能量平均值對應的幀確定為目標幀,并根據所述目標幀確定所述多媒體數據的副歌起始時刻,進一步可獲取副歌經驗時長,計算所述副歌經驗時長和所述副歌起始時刻的和,得到所述多媒體數據中的第二目標時刻,將所述第二目標時刻確定為所述多媒體數據的副歌終止時刻,完成對多媒體數據的副歌的起始時刻和終止時刻進行定位。
本領域普通技術人員可以理解實現上述實施例方法中的全部或部分流程,是可以通過計算機程序來指令相關的硬件來完成,所述的程序可存儲于一計算機可讀取存儲介質中,該程序在執行時,可包括如上述各方法的實施例的流程。其中,所述的存儲介質可為磁碟、光盤、只讀存儲記憶體(Read-Only Memory,ROM)或隨機存儲記憶體(Random Access Memory,RAM)等。
以上所揭露的僅為本發明較佳實施例而已,當然不能以此來限定本發明之權利范圍,因此依本發明權利要求所作的等同變化,仍屬本發明所涵蓋的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!