一種對帶噪語音進行語音活動檢測的方法與流程
本發明涉及語音信號處理技術領域,具體涉及一種對帶噪語音進行語音活動檢測的方法。
背景技術:
語音質量在一些語音應用中很重要,比如手機、助聽器以及語音編碼系統等等,提升語音質量的一個關鍵就是消除信號中的噪音。而分析和處理語音需要解決的一個首要問題是檢測出語音信號中的語音和非語音,即語音活動檢測(Voice activity detection,VAD)。
基于G.729標準的VAD方法計算信號的能量,然后設定門限對信號的每一幀進行簡單的分類,同時還用平滑和自適應的校正來提高分類的準確性。然而,這種方法在噪音存在的情況下無法取得令人滿意的效果。所以,很多學者開始嘗試利用數學建模實現VAD,但是這種方法無法在不同的噪聲環境中均取得良好的效果,為解決這一問題,研究者們進一步提出了聲學事件檢測(AED)技術,轉換卡爾曼濾波器(SKF),聚類算法(如譜聚類)和稀疏編碼(Sparse Coding)等等。然而,這些方法有的需要很大的計算量,有的需要純凈語音作為參考,有很大的局限性。
語音是由人的聲帶產生的,某一個人的聲帶通常可以認為是不變的,所以一段信號中的不同的語音部分常常有一些共同的相像的特征,這些特征取決于說話者的聲帶,是非語音部分不具有的。
技術實現要素:
為了解決現有的VAD方法存在的不足,本發明提出一種對帶噪語音進行語音活動檢測的方法,可以在不同的噪音環境中計算出語音信號中的語音存在的概率。具體技術方案如下:
一種對帶噪語音進行語音活動檢測的方法,包括如下步驟:
a.采集語音信號;
b.輸入步驟a采集的語音信號;
c.對輸入的帶噪語音進行分幀處理;
d.計算相鄰幀快速傅立葉變換模的互相關值;
e.基于步驟d所得互相關值計算出每一幀的語音存在概率。
進一步地,步驟c中,對輸入的帶噪語音信號data分幀得到x(i),幀長len1設置為40ms,幀移len2設置為20ms,其中i為幀號。
進一步地,步驟d中包括:
(d-1)對分幀后的帶噪語音做快速傅立葉變換后取模;
(d-2)求相鄰幀的模的互相關值;
(d-3)求相鄰幀的模的互相關值后,取其四次方根;
(d-4)互相關值四次方根需要減去所有互相關值四次方根幅度分布最大值對應的橫坐標,并且小于零的數值歸零。
進一步地,步驟e中包括:
(e-1)歸一化處理;
(e-2)平滑處理;
(e-3)得到語音概率。
進一步地,步驟b中輸入手機、助聽器以及語音編碼系統等,其內置可運行本方法的檢測芯片。
進一步地,步驟(d-1)中,對各幀做快速傅立葉變換(FFT)并取模,加漢明窗平滑,得到xfft(i)=abs(FFT(x(i)))*hamming(L),其中abs表示取模運算,*表示卷積運算,hamming(L)表示窗長為L的漢明窗,L可根據具體應用調整。
進一步地,步驟(d-2)中,對相鄰兩幀的xfft做互相關運算,得到xcorr(i)=∑xfft(i)·xfft(i+1)。
進一步地,步驟(d-3)中,對xcorr(i)取四次方根,得到xdata(i)=(xcorr(i))1/4。
進一步地,步驟(d-4)中,計算xdata(i)的幅度分布,得到幅度分布最大值對應的橫坐標m=abscissa(max(H(xdata))),max(*)表示*的最大值,H(*)表示*的幅度分布,abscissa(*)表示*的橫坐標;計算xdata2(i)=max(0,xdata(i)-m)。
進一步地,步驟(e-1)中,對xdata2(i)做歸一化處理,得xdata3(i)=xdata2(i)/max(xdata2);步驟(e-2)中,對xdata3(i)做平滑處理,得xsp(i)=xdata3*hamming(len2);步驟(e-3)中,得到xsp(i)即表示第i幀包含語音的概率。
與目前現有技術相比,本發明對輸入的帶噪語音進行分幀,然后計算相鄰幀快速傅立葉變換模的互相關值,基于此互相關值計算出每一幀的語音存在概率。本發明提出的語音活動檢測方法魯棒性強,可以在不同的噪音環境中計算出帶噪語音信號中的語音存在的概率。
附圖說明
圖1為本發明的算法流程圖;
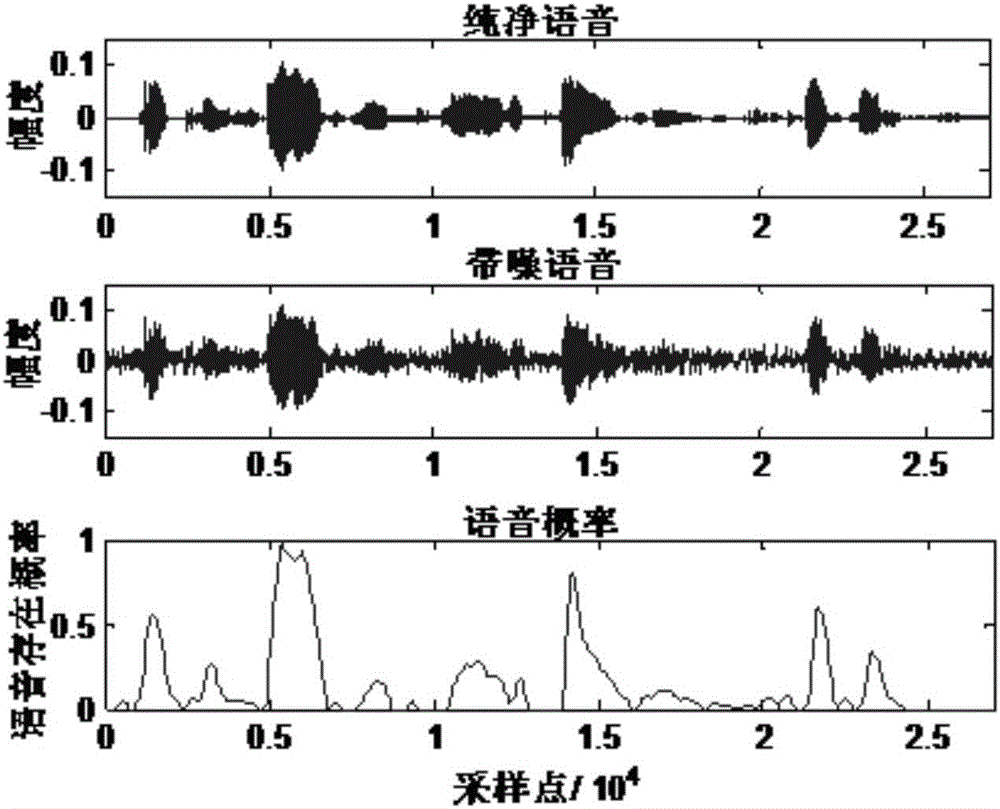
圖2為采用本發明提出的方法對一段帶噪語音計算得到的語音存在概率示意圖;
具體實施方式
下面根據附圖對本發明進行詳細描述,其為本發明多種實施方式中的一種優選實施例。
在一個優選實施例中,技術方案包含以下步驟:
步驟1、對輸入的帶噪語音信號data分幀得到x(i),幀長len1設置為40ms,幀移len2設置為20ms,其中i為幀號;
步驟2、對各幀做快速傅立葉變換(FFT)并取模,加漢明窗平滑,得到xfft(i)=abs(FFT(x(i)))*hamming(L),其中abs表示取模運算,*表示卷積運算,hamming(L)表示窗長為L的漢明窗,L可根據具體應用調整;
步驟3、對相鄰兩幀的xfft做互相關運算,得到xcorr(i)=∑xfft(i)·xfft(i+1);
步驟4、對xcorr(i)取四次方根,得到xdata(i)=(xcorr(i))1/4;
步驟5、計算xdata(i)的幅度分布,得到幅度分布最大值對應的橫坐標m=abscissa(max(H(xdata))),max(*)表示*的最大值,H(*)表示*的幅度分布,abscissa(*)表示*的橫坐標;
步驟6、計算xdata2(i)=max(0,xdata(i)-m);
步驟7、對xdata2(i)做歸一化處理,得xdata3(i)=xdata2(i)/max(xdata2),對xdata3(i)做平滑處理,得xsp(i)=xdata3*hamming(len2),則xsp(i)即表示第i幀包含語音的概率。
在另一個優選實施例中,可以采用如下方案:如圖1所示,一種對帶噪語音進行語音活動檢測的方法,可以在不同的噪音環境中檢測出帶噪語音信號中的語音和非語音部分,其具體步驟為:步驟1、對輸入的帶噪語音信號data分幀得到x(i),幀長len1設置為40ms,幀移len2設置為20ms,其中i為幀號;步驟2、對各幀做快速傅立葉變換(FFT)并取模,加漢明窗平滑,得到xfft(i)=abs(FFT(x(i)))*hamming(L),其中abs表示取模運算,*表示卷積運算,hamming(L)表示窗長為L的漢明窗,L可根據具體應用調整;步驟3、對相鄰兩幀的xfft做互相關運算,得到xcorr(i)=∑xfft(i)·xfft(i+1);步驟4、對xcorr(i)取四次方根,得到xdata(i)=(xcorr(i))1/4;步驟5、計算xdata(i)的幅度分布,得到幅度分布最大值對應的橫坐標m=abscissa(max(H(xdata))),max(*)表示*的最大值,H(*)表示*的幅度分布,abscissa(*)表示*的橫坐標;步驟6、計算xdata2(i)=max(0,xdata(i)-m);步驟7、對xdata2(i)做歸一化處理,得xdata3(i)=xdata2(i)/max(xdata2),對xdata3(i)做平滑處理,得xsp(i)=xdata3*hamming(len2),則xsp(i)即表示第i幀包含語音的概率。
如圖2所示,該帶噪語音為夾雜工廠噪音的語音,信噪比為3分貝,對輸入的帶噪語音進行分幀,然后計算相鄰幀快速傅立葉變換模的互相關值,基于此互相關值計算出每一幀的語音存在概率。本發明提出的語音活動檢測方法魯棒性強,可以在不同的噪音環境中計算出帶噪語音信號中的語音存在的概率。其原理為:對分幀后的帶噪語音做快速傅立葉變換后取模。求相鄰幀的模的互相關值后,取其四次方根。互相關值四次方根需要減去所有互相關值四次方根幅度分布最大值對應的橫坐標,并且小于零的數值歸零。互相關值四次方根減去所有互相關值四次方根幅度分布最大值對應的橫坐標,并且小于零的數值歸零后,需要進行歸一化和平滑處理。
上面結合附圖對本發明進行了示例性描述,顯然本發明具體實現并不受上述方式的限制,只要采用了本發明的方法構思和技術方案進行的各種改進,或未經改進直接應用于其它場合的,均在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!