使用局部二進制模式進行聲學情境辨識的方法和設備與流程
本發明的各方面總體上涉及聲音處理。具體來說,本發明提出利用局部二進制模式進行音頻場景辨識以識別音頻中的模式的方案,音頻中的模式可能與例如不同來源、語音、音樂、背景噪聲和特定事件相關聯。
背景技術:
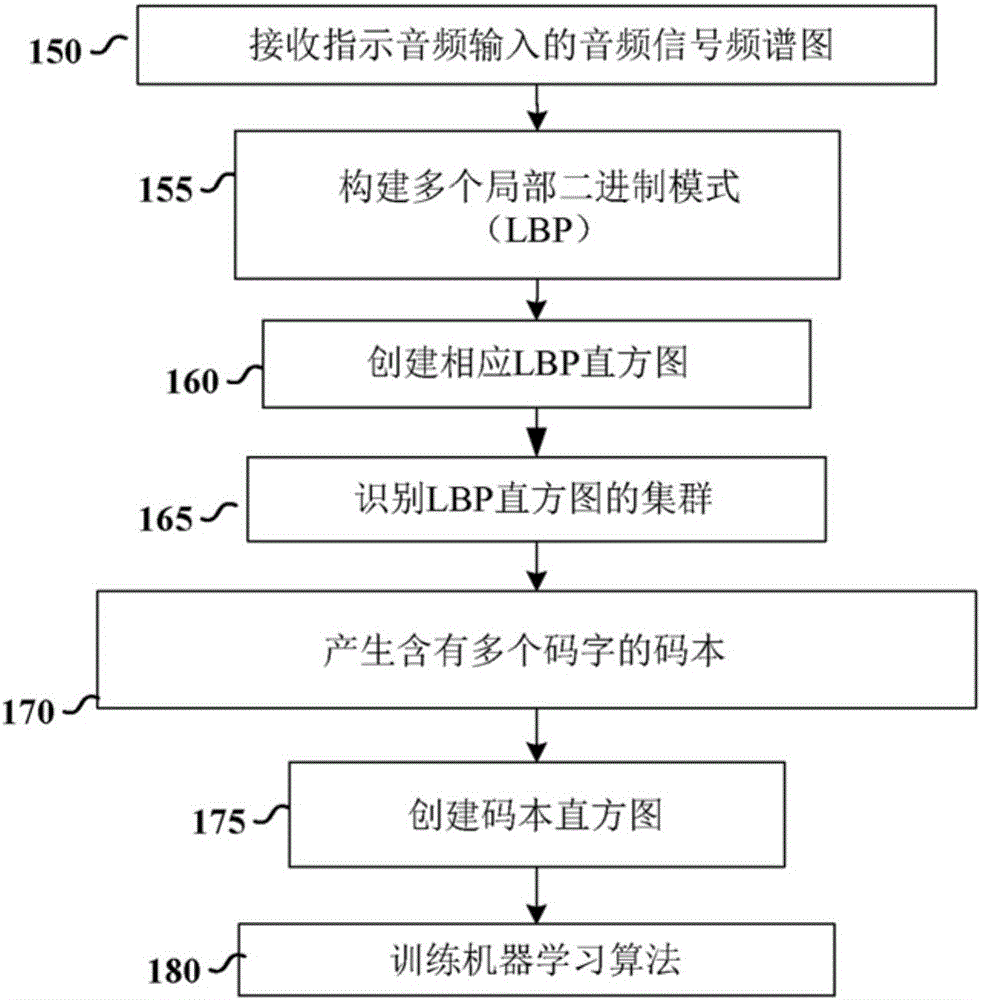
:在計算機電子器件(例如,蜂窩電話)的許多應用中,客戶需要高度個性化,包括呈現給用戶的數據的高度個性化。本發明的實施例是針對通過對在使用經由麥克風接收的音頻時裝置的使用環境進行情境分析,提供這樣的個性化。在這些實施例中,裝置能夠隔離和識別環境的情境,且向用戶呈現至少部分與環境相關聯的信息。聲音環境的情境可包括各種音頻源,所述音頻源包括通常與例如辦公室、公共汽車或街道等位置相關聯的聲音。相比其它方法,使用音頻場景辨識能提供幾種益處,至少包括俘獲時間事件的能力,和區分環境中若干同時出現的情境的能力。各種實施例可利用存在于電子裝置中的硬件,例如麥克風和足夠的處理電路。根據本發明已發現,能夠俘獲時間事件會大大增加裝置正確地識別情境的概率。在本發明的其它更特定實施例中,裝置可進一步降低裝置的音頻處理要求,由此在裝置為移動裝置的情況下增加電池壽命,且改進裝置的總體性能,因為需要分配給后臺功能的處理能力更少。本發明的各方面通過將音頻變換成音頻頻譜圖(在一或多個時間段的音頻的視覺表示),并分析來自同一個音頻源的一系列頻譜圖以識別音頻模式,借此將圖像處理技術應用于音頻頻譜,所述音頻模式指示接收音頻的裝置所處的環境情境(例如,辦公室、公共汽車、街道等)。本發明能夠使用與這一系列頻譜圖相關聯的直方圖隨時間推移映射這些音頻 模式,這大大提高了聲學辨識性能。在本發明的許多實施例中,聲學辨識方法可利用預定義碼本,其中將所識別的音頻模式與已知環境情境進行比較。在比較時,如果所識別的音頻模式在碼本中的已知音頻模式中的一或多個音頻模式的相似性閾值內,那么所識別的音頻模式將與已知音頻模式的環境情境相關聯。在這些實施例中,所識別的音頻模式可被加入碼本,且在碼本中與適當環境情境相關聯。在另外的其它實施例中,該方法可包括學習階段,其允許裝置的用戶利用聲學辨識方法來識別音頻模式(聲學辨識方法可能無法識別),且將音頻模式加入碼本。技術實現要素:本發明的各種實施例是針對識別音頻場景的情境。根據一個此類示例性實施例,公開包括以下步驟的方法。接收指示音頻輸入的音頻信號頻譜圖,且基于頻譜圖的鄰近像素的比較,構建多個局部二進制模式(LBP)。對于頻譜圖的多個塊中的每一塊,創建基于不同LBP在多個塊中的對應塊中出現的次數的相應LBP直方圖。基于LBP直方圖與多個碼字之間的對應,創建碼本直方圖。最后,使用機器學習模型,對碼本直方圖進行分類以識別所接收的音頻信號的情境。在本發明的另外的其它更特定實施例中,該方法可進一步包括從相應LBP直方圖中識別具有k均值算法的LBP直方圖的集群,且基于集群產生碼字,所述碼字為所識別的集群的質心。在某些實施例中,分類和情境識別可實時或近實時進行。本發明的其它實施例是針對用于識別音頻場景的情境的離線學習階段(這些所識別的情境可稍后用于實時應用以識別所接收的音頻輸入的情境)。根據一個此類示例性實施例,公開包括以下步驟的方法。接收指示音頻輸入的音頻信號頻譜圖,且基于頻譜圖的鄰近像素的比較,構建多個局部二進制模式(LBP)。對于頻譜圖的多個塊中的每一塊,創建基于不同LBP在多個塊中的對應塊中出現的次數的相應LBP直方圖。基于用于頻譜圖的多個塊中的每一塊的相應LBP直方圖,識別LBP直 方圖的集群,且基于集群產生用于機器學習模型的碼字。本發明的許多實施例是針對設備。本發明的設備包括音頻LBP直方圖模塊、碼本創建模塊、直方圖映射模塊和支持向量機。音頻LBP直方圖模塊接收指示音頻輸入的音頻信號頻譜圖。基于頻譜圖的鄰近像素的比較,音頻LBP直方圖模塊建構多個局部二進制模式(LBP)。對于頻譜圖的多個塊中的每一塊,音頻LBP直方圖創建相應LBP直方圖,所述LBP直方圖基于不同LBP在多個塊中的對應塊中出現的次數。以通信方式耦合到音頻LBP直方圖模塊的碼本創建模塊從相應LBP直方圖中使用k均值算法識別LBP直方圖的集群。以通信方式耦合到碼本創建模塊和音頻LBP直方圖模塊的直方圖映射模塊基于集群產生碼字,所述碼字為所識別的集群的質心。基于LBP直方圖與多個碼字之間的對應,直方圖映射模塊創建碼本直方圖。最后,以通信方式耦合到直方圖映射模塊的支持向量機模塊使用機器學習模型對碼本直方圖進行分類以識別用于所接收的音頻信號的情境。以上論述/概述并不意欲描述本發明的每一實施例或每一實施方案。下面的圖和詳細描述也舉例說明各種實施例。附圖說明結合附圖考慮以下詳細描述,可以更全面地理解各種示例性實施例,其中:圖1A到圖1B示出與本發明的各種方面一致的功能框圖;圖2示出與本發明的各種方面一致的系統級框圖;圖3為示出與本發明的各種方面一致的從音頻信號創建LBP的圖;以及圖4示出與本發明的各種方面一致的功能框圖。雖然本文中所論述的各種實施例能夠接受各種修改及替代形式,但圖式中還是舉例示出了各種實施例的各方面并將進行詳細描述。然而,應理解,不意圖將本發明限于所描述的特定實施例。相反,意圖涵蓋落入包括權利要求書中限定的各方面的本發明的范圍內的所有修改、等效 物和替代方案。另外,本申請案通篇中所使用的“例子”這個術語只是用做例示而不是用做限制。具體實施方式本發明的各方面總體上涉及聲音處理。具體來說,本發明提出用于經由新穎方法進行音頻場景辨識的方案,所述新穎方法利用局部二進制模式來識別音頻中的模式,音頻中的模式可能與情境(例如,不同來源、語音、音樂、背景噪聲和特定事件)相關聯。在計算機電子器件(例如,蜂窩電話)的許多應用中,客戶需要呈現給用戶的數據中的高度個性化。本發明的實施例總體上是針對通過對在利用經由內置麥克風(在電子器件上機載的)接收的音頻時的裝置使用環境進行情境分析,實現這種個性化。在各種實施例中,裝置能夠隔離和識別環境的情境,且至少部分基于環境調適所呈現的信息。舉例來說,裝置可被配置成基于所接收的音頻信號中的聲音的分類(和其它因素,例如當日時間、位置和其它裝置可辯別的信息)確定例如用戶在下班回家路上的街上。裝置接著可顯示指示當前交通模式、最佳回家路線、天氣狀況和該區域當前提供優惠時間特價菜的當地餐館的信息。由裝置識別的情境可包括音響環境的各種可辨別的方面,例如辦公室里熒光燈的嗡嗡聲、市內公共汽車的排氣噪聲或城市街道的各種環境噪聲(例如汽車喇叭聲)等。相比其它方法,使用音頻場景辨識提供幾種益處,至少包括俘獲時間事件的能力,和區分環境中若干同時出現的情境的能力。已發現,能夠使在某一時間段中的單個音頻事件相關會大大增加肯定地識別音頻事件(或情境)的能力。而且,各種實施例的方面特別能用于限制額外硬件,因為許多電子裝置已經包括麥克風和足夠的處理電路。本發明的各方面也是針對降低所接收的音頻的處理要求。在許多情況下,理想地將這些實施例嵌入到移動裝置中,移動裝置的電量是有限的。在本發明的其它更特定實施例中,音頻處理方法可進一步降低裝置 的音頻處理要求,由此在裝置為移動裝置的情況下增加電池壽命,且改進裝置的總體性能,因為需要分配給后臺功能(包括音頻處理)的處理能力更少。本實施例通過如下方式實現了電力使用量的此下降:通過例如將相對于彼此定位的各種碼本直方圖聚類到單個質心中(這也會減少音頻處理方法的內存占用率),借此最小化與所接收的音頻信號相關聯的直方圖與碼本直方圖之間所需要的比較操作。本發明的各方面通過將音頻變換成音頻頻譜圖(在一或多個時間段的音頻的視覺表示),并分析來自同一個音頻源的一系列頻譜圖以分類和識別音頻模式,借此將圖像處理技術應用于音頻頻譜,所述音頻模式指示接收音頻的裝置所處的環境情境(例如,辦公室、公共汽車、街道等)。能夠隨時間推移映射這些音頻模式能大大提高聲學辨識性能。在本發明的實施例中,聲學辨識方法可利用預定義碼本,所述預定義碼本可用以分類和識別與已知環境情境相關的音頻模式。在比較時,如果所識別的音頻模式在碼本中的已知音頻模式中的一或多種音頻模式的相似性閾值內,那么所識別的音頻模式將與已知音頻模式的環境情境相關聯。在另外的其它實施例中,該方法可包括學習階段,其允許用戶利用聲學辨識方法來識別音頻模式(聲學辨識方法原本當前可能無法根據其現有碼本識別音頻模式),且將這些情境加入碼本。本發明的各種示例性實施例是針對解決與聲學情境辨識和其實施方案有關的難題的方法、電路和系統。還應理解,在包括語音辨識的音頻辨識的其它區域中也可利用本發明的各方面。本發明的實施例是針對用于識別音頻場景的情境的學習階段。所識別的情境稍后可用于(實時)應用中,以識別所接收的音頻輸入的情境。根據示例性實施例,處理裝置(例如,一或多個計算機處理器單元或電路)接收指示音頻輸入的頻譜圖形式的音頻信號。處理裝置接著可比較頻譜圖的鄰近像素,以構建多個局部二進制模式(LBP)。對于頻譜圖的多個子塊中的每一子塊(例如,對應于不同音頻范圍的子塊),基于不同LBP出現的次數而創建相應LBP直方圖。處理裝置接著可使用頻譜圖的多個塊中的每一塊的相應LBP直方圖來識別LBP直方圖的集群。接著 由集群創建碼字(例如,基于集群中的每一集群的平均值或質心的碼字)。接著可根據機器學習算法或模型對處理裝置碼字進行分類。本發明的各種實施例是針對用于識別音頻場景的情境的方法。根據示例性實施例,基于LBP直方圖的聚類而創建的碼本可被用作特征列表。本文中更詳細描述了關于此碼本的創建的特定細節。使用此碼本可能特別有用,因為其提供對音頻內容進行分類的緊湊并且有鑒別性的特征集。根據實施例,處理裝置可接收指示音頻輸入的音頻信號頻譜圖。處理裝置接著可基于頻譜圖的鄰近像素的比較構建多個LBP。對于頻譜圖的多個子塊中的每一子塊,創建基于不同LBP在多個塊中的對應塊中出現的次數的相應LBP直方圖。多個LBP指示頻譜圖的多個塊中的每一塊中的像素值、閾值轉變和相應像素位置。頻譜圖的多個塊中的每一塊的相應LBP直方圖指示在某一時間段中音頻輸入的聲學情境。在更特定實施例中,每一相應LBP直方圖將頻譜圖的多個塊中的每一塊映射到多個均勻配置和不均勻配置中。基于LBP直方圖與多個碼字之間的對應,創建碼本直方圖。在其它實施例中,碼本直方圖的創建進一步包括使用LBP直方圖與碼字之間的余弦距離確定LBP直方圖與碼字之間的余弦距離,且基于余弦距離將LBP直方圖指派給碼本直方圖中的碼字。最后,使用利用碼本訓練的機器學習模型,對碼本直方圖進行分類,以識別所接收的音頻信號的情境。在各種實施例中,機器學習模型在支持向量機內。在本發明的另外的其它更特定實施例中,可使用k均值聚類算法識別LBP直方圖的集群。k均值聚類算法是機器學習技術,其將n個觀測結果分割成k個集群,其中每一觀測結果屬于均值最接近的集群。在給定觀測結果集(x1,x2,...,xn)的情況下(其中每一觀測結果為d維實向量),k均值聚類旨在將n個觀測結果分割成k(≤n)個集合S={S1,S2,...,Sk},以便最小化集群內平方和(WCSS)。k均值聚類等式為:argminSΣi=1kΣx∈Si||x-μi||2]]>其中μi為Si中的點的均值。該算法最終找到具有相當的空間范圍的 集群。處理裝置接著可產生碼字,所述碼字是基于集群的質心。本發明的許多實施例進一步包括對于LBP直方圖中的每一LBP直方圖,使用在LBP直方圖中的每一LBP直方圖的相應塊之外的像素值進行內插。本發明的許多實施例是針對設備。本發明的一個設備包括音頻LBP直方圖模塊、碼本創建模塊、直方圖映射模塊和支持向量機。音頻LBP直方圖模塊接收指示音頻輸入的音頻信號頻譜圖。基于頻譜圖的鄰近像素的比較,音頻LBP直方圖模塊建構多個局部二進制模式(LBP)。對于頻譜圖的多個塊中的每一塊,音頻LBP直方圖創建相應LBP直方圖,所述LBP直方圖基于不同LBP在多個塊中的對應塊中出現的次數。以通信方式耦合到音頻LBP直方圖模塊的碼本創建模塊從相應LBP直方圖中用k均值算法識別LBP直方圖的集群。以通信方式耦合到碼本創建模塊和音頻LBP直方圖模塊的直方圖映射模塊基于集群產生碼字,所述碼字為所識別的集群的質心。基于LBP直方圖與多個碼字之間的對應,直方圖映射模塊創建碼本直方圖。最后,以通信方式耦合到直方圖映射模塊的支持向量機模塊使用機器學習模型對碼本直方圖進行分類以識別用于所接收的音頻信號的情境。現在參看各圖,圖中借助于說明呈現了本發明的各種實施例。圖1A示出與本發明的各種方面一致的用于辨識音頻信號的聲學情境的功能圖。首先,接收105指示音頻輸入的音頻信號頻譜圖。接著基于所接收的頻譜圖的鄰近像素的比較構建110多個局部二進制模式(LBP)。對于頻譜圖的多個塊中的每一塊,基于不同LBP在多個塊中的對應塊中出現的次數創建115相應LBP直方圖。從相應LBP直方圖中的每一LBP直方圖識別120LBP直方圖的集群。對于集群中的每一集群,產生125表示對應集群的碼字。接著將LBP直方圖與表示集群的碼字進行比較以創建碼本直方圖130。最后,使用機器學習模型,對碼本直方圖進行分類135以識別所接收的音頻信號的情境。圖1B示出與本發明的各種方面一致的用于辨識音頻信號的聲學情境的另一功能圖。首先,接收150指示音頻輸入的音頻信號頻譜圖。接 著基于所接收的頻譜圖的鄰近像素的比較構建155多個局部二進制模式(LBP)。對于頻譜圖的多個塊中的每一塊,基于不同LBP在多個塊中的對應塊中出現的次數創建160相應LBP直方圖。從相應LBP直方圖中的每一LBP直方圖識別165LBP直方圖的集群。基于LBP直方圖的集群,產生170含有多個碼字的碼本,接著將LBP直方圖映射到碼本的碼字以創建碼本直方圖175。最后,使用LBP直方圖作為特征來訓練180機器學習算法。圖2示出與本發明的各種方面一致的系統級框圖。系統200包括學習裝置201,所述學習裝置創建(支持向量機“SVM”)模型,所述模型通過使用直方圖的碼本作為用于分類的特征對已知情境進行分類。裝置211從學習裝置201接收(SVM)模型,且使用模型對情境未知的所接收的聲音進行分類(實時使用)。在本發明的各種實施例中,可利用有線或無線通信裝置將模型傳遞到裝置211。此外,在一些實施例中,可有規律地更新模型以包括新分類的音頻情境。參考學習裝置201,含有具有已知情境的音頻數據的存儲器模塊202將音頻數據提供到特征提取模塊205。特征提取模塊205在音頻數據的時間長度內以時間方式構建音頻信號頻譜圖。接著將頻譜圖劃分成子塊,且將每一子塊乘以音頻經過調適的局部二進制模式(“LBP”)。對于每一子塊,提取LBP的直方圖,每一直方圖包括環境的音頻頻譜。特征提取模塊205接著利用聚類算法來創建聲學模式的碼本。這些聲學模式表示共同特性(或特征),所述共同特性可用以識別對于給定應用來說可能相關的情境(或噪聲)。與本發明的實施例一致,LBP的聚類會減少或壓縮特征以進行分析。對于減少裝置處理和存儲器資源的使用,這一點可能特別有用。在特定實施例中,在提取了所有直方圖的情況下,可以使用k均值聚類算法(基于余弦相似性)將類似直方圖塊分組,且獲得具有數據集的相關模式的最終碼本。將集群的質心寫成碼本的元素。受監督的訓練模塊210創建(SVM)模型,所述模型通過使用直方圖的碼本作為用于分類的特征來分類已知情境。輸出為(SVM)模型,所述模型可用以對情境未知 的未來聲音進行分類(實時使用)。參考系統200的裝置211,學習裝置201的模型被配置于裝置211的特征提取模塊206中。模型包括碼本,所述碼本表示期望在給定應用中檢測到的類型的情境的共同特性或特征。由音頻信號接收模塊220(例如,麥克風或其它音頻接收機構)接收音頻信號。在許多實施例中,音頻信號(至少部分)指示音頻信號接收模塊220所處的環境。舉例來說,如果包括圖2的各種模塊的例如手機等裝置是在體育事件中,那么可根據本發明的方面處理聲學情境(包括例如語音、音樂、背景噪聲和其它特定聲學事件),以指示手機的情境環境為體育事件。這可包括根據與體育事件一致的學習到的特性對各種音頻特征進行分類。在這些實施例(并且可能結合其它所收集的數據,例如位置數據、用戶輸入等)中,手機可被配置成定制用戶接口以顯示體育事件的相關信息,例如最新運動選手統計數據、新聞、即時重播和其它聯賽相關新聞。音頻信號接收模塊220可在將所接收的音頻信號傳輸到特征提取模塊206之前對音頻信號執行幾種輔助功能,例如降噪、放大等。特征提取模塊206首先構建指示音頻信號接收模塊220接收到的音頻輸出的音頻信號頻譜圖。特征提取模塊206接著基于頻譜圖的鄰近像素的比較生成多個局部二進制模式(LBP)。基于頻譜圖的多個塊中的每一塊,創建相應LBP直方圖,所述相應LBP直方圖基于不同LBP在多個塊中的對應塊中出現的次數。基于LBP直方圖與多個碼字之間的對應,創建碼本直方圖。最后,辨識SVM225使用機器學習模型對碼本直方圖進行分類,以識別所接收的音頻信號的情境。被提供為辨識SVM225的輸出的辨識結果230可指示所接收的音頻的情境。應理解,除支持向量機以外,在本發明中也可利用用于受監督學習的其它分類器,例如人工神經網絡和高斯混合模型。圖3示出了圖,所述圖示出了與本發明的各種方面一致的從音頻信號創建LBP的過程。在各種實施例中,處理裝置300可包括特征提取模塊,所述特征提取模塊可用以從音頻信號的頻譜圖330產生LBP。用于頻譜圖330的可能格式為曲線圖,其中一根軸(例如,橫軸)表示時間, 另一根軸(例如,縱軸)表示頻率。振幅或音量可由圖像像素的強度或顏色指示。特征提取模塊可將頻譜圖330分解成包括塊331的數個子塊。在某些實施例中,頻譜圖330可為線性頻譜圖。由于子塊的局部性質,每一子塊可表示音頻信號的特定時間和頻率范圍。已發現,頻譜圖的線性表示含有較少噪聲,且可主要受稀疏高能元素支配(增加圖案辨識的可能性)。如332中所示,對于圖像的每一像素,圍繞中心像素建構塊。如333中所示,可將每一像素的值與周圍像素相比較(使用閾值),如果值較低,那么將其映射為0;如果較大,那么將其映射為1。在特定實施例中,周圍像素的值可與整個塊331上的均值相比較,但用于確定比較閾值的其它變化是可能的。在這些實施例中,此均值方法可使算法對噪聲的穩定性更強,且對像素間的大幅變化的穩定性更強。從塊332的左上角開始,變換二進制值(例如參見二進制:11010011)。在某些實施例中,塊332的二進制結果可通過內插這些值而被建模為指示340中所描繪的59個可能的位組合圓圈中的一個位組合圓圈。具體來說,前58個位組合表示均勻位組合,其中1與0之間的二進制轉變的數目不大于2。可將不均勻LBP映射到第59位組合。因此,所得直方圖350的尺寸可能限于算法中的59個可能的模式中的一個模式(每一模式將所得塊333的可能朝向考慮在內)。與各種實施例一致,其它直方圖也是可能的,包括位組合的更詳盡列表或更少的位組合。舉例來說,在某些應用中,一或多個不均勻位組合可能特別有辨識性。因此,直方圖尺寸可擴展以包括這些位組合。或者或另外,對于某些應用,可移除一或多個均勻位組合。每當在塊中發現模式(59個可能模式中的一個模式),在所得直方圖350中累積所述模式。所得直方圖350將每第i個模式的出現考慮在內,且直接表示圖像的模式分布。圖4示出與本發明的各種方面一致的用于辨識音頻信號的聲學情境的功能框圖。圖4的方案利用LBP、利用音頻信號頻譜圖表示的圖像處理技術、直方圖來辨識聲學情境。LBP可被用作有效紋理算子,所述有 效紋理算子通過設定相鄰像素的閾值和將結果計算為二進制數(如本文中更詳細所論述)來標記頻譜圖圖像的像素。LBP特別適合于各種音頻應用,因為它的算法甚至對于頻譜圖中的相鄰像素之間的巨大波動(這在音頻頻譜圖中是常見的)也很穩定。LBP也受益于建構更可辨別的特征的能力,所述特征利用頻譜的時頻信息。已發現,俘獲和關聯在某一時間段中的情境事件可顯著提高情境事件的辨識性能。參看圖4詳細地描述使用基于LBP的算法辨識聲學情境的示例性電路。根據本發明的實施例,將電路分割成五個塊/模塊:音頻LBP直方圖模塊1、碼本創建模塊2、直方圖映射模塊3、SVM訓練模塊4和SVM測試模塊5。音頻LBP直方圖模塊1接收音頻信號401,且將音頻信號轉換成頻譜圖402。接著將頻譜圖劃分成塊403(例如,對應于不同音頻范圍的塊),且利用LBP算法通過比較每一像素的值與其相應相鄰像素,借此從輸入圖像(頻譜圖)中找出反復出現的模式。接著針對頻譜圖402的塊403中的每一塊建構LBP直方圖404,并且計算模式在整個圖像中被發現多少次。輸入圖像可為音頻信號401的頻譜圖402,且必須對其進行修改,以更好地與LBP算法擬合。在使用已知音頻序列的系統的受監督訓練期間,碼本創建模塊可用以識別特征,所述特征接著可用以訓練機器學習模塊,例如SVM。一旦已提取來自整個數據集的LBP直方圖,碼本創建模塊2便可使用聚類技術405將頻繁使用的直方圖分組在一起。集群值接著可用以形成碼本406。直方圖映射模塊3接著利用余弦相似性407找出碼本406中的哪些碼本直方圖408是類似的。接著可將LBP直方圖404映射到來自碼本的碼字中的一個碼字上。在這些步驟之后,碼本直方圖408的特征的冗余度變低,且尺寸比單獨的LBP直方圖404更小。這對于嵌入式裝置來說可能特別有用,因為嵌入式裝置可能有存儲空間和計算方面的局限性。來自直方圖映射模塊3的碼本直方圖408變為SVM訓練模塊4和SVM測試模塊5的輸入特征。在本發明的各種實施例中,將對SVM訓 練模塊4進行訓練409以對三個子帶的59尺寸的直方圖進行分類,或對映射到詞典中的可能模式中的一個模式中的特征進行分類。結果,創建SVM模型410,所述SVM模型410可由SVM測試模塊5使用來預測411和輸出412指示所接收的音頻信號的情境。在許多實施例中,SVM模塊4和5將數據投影到較高維空間中,在此新空間中,有可能使用具有分類的最大裕度和最小誤差的超平面來應用線性分離。另外,更密集表示能夠最大化不同情境之間的距離,且改進SVM的可辨別能力。在本發明的某些實驗實施例中,公開LBP算法,所述LBP算法比較周圍像素與整個塊上的均值:LBPP,R=Σi=0P-1f(gi-μ)2P,f(x)=1,x≥μ0,x<μ]]>其中gi為第i個相鄰像素的值,μ為整個塊之上的均值,P為所涉及的像素的數目。R為鄰域的半徑:gi的坐標為Rcos(2πi/P)、sin(2πi/P)。不在塊中的像素值可由雙線性內插法估計。像素接著可使用3*3塊中的x及y坐標兩者以及內插權重wi進行內插:z=w0+W1X+w2y+a3xy在各種示例性實施例中,頻譜圖中的像素值受巨大波動影響,所述巨大波動可能會損害LBP表示(導致直方圖的可能無限多的潛在尺寸)。為了減少直方圖的潛在尺寸,考慮LBP碼中的0與1之間的轉變:如果轉變的數目小于或等于2,那么LBP二進制字符串被視為均勻的,且將其映射到58個配置中的一個配置中,類似圖2中的情況(因此,第59配置是用于不均勻的LBP二進制字符串)。均勻模式確保存在相關紋理元素,例如邊緣、角或均勻分區,且其將舍棄不均勻的分區(轉給第59配置),所述不均勻的分區更有可能已經受到噪聲的影響。在實驗測試中,已表明此直方圖減少的效果良好。參看本發明的各種實施例中的頻譜圖分析,頻譜圖中的像素表達特定時頻坐標中的能量信息。本發明的許多實施例利用線性頻譜頻譜儀到對數頻譜頻譜儀,其較少地受噪聲支配。線性頻譜圖主要由稀疏高能元 素形成,而剩余元素不會干擾模式辨識。在這些實施例中,將頻段分離成三個不同頻段(小于900Hz,從900Hz到2kHz和從2kHz直到8kHz為止),以表示在16kHz取樣的信號中含有的完整信息。特定頻率范圍可基于特定取樣速率和其它考慮因素(例如,所分析的情境的類型)進行調整。LBP算法使用這三個副頻段來執行聲學模式辨識,且提取頻譜圖的對應塊中的每一塊的直方圖(類似圖2中的情況)。在本發明的特定實施例中,用于創建碼本中的代碼的算法在進行分類之前包括另一步驟,以使特征更緊湊。這個另一步驟發現數據集中的最具代表性的模式,且使用不受監督的分類自動提取所述最具代表性的模式。最具代表性的直方圖的碼本的創建為算法的基本部分,因為其允許未知聲學情境的分類。可以使用k均值聚類算法(或其它聚類算法)將類似塊分組,且獲得具有數據集的最相關模式的最終碼本。余弦距離可被用作許多特征描述符(尤其是直方圖特征)的良好度量。最后,集群的質心變為碼本的元素,如上文所更詳細描述。可以實施各種塊、模塊或其它電路以執行本文中描述和/或圖中所示出的操作和活動中的一或多個操作和活動。在這些情境中,“塊”(有時也稱為“邏輯電路”或“模塊”)為進行這些或相關操作/活動中的一或多個操作/活動的電路(例如,第一模塊、第二模塊和存儲器模塊)。舉例來說,在以上論述的實施例中的某些實施例中,一或多個模塊為被配置且被布置成用于實施這些操作/活動的離散邏輯電路或可編程邏輯電路,如圖1中所示出。在某些實施例中,此類可編程電路為一或多個計算機電路,其被編程為執行指令(和/或配置數據)的集合(或若干集合)。指令(和/或配置數據)可采用存儲在存儲器(電路)中且可從存儲器(電路)中存取的固件或軟件的形式。舉例來說,第一和第二模塊包括基于CPU硬件的電路和采用固件形式的指令集的組合,其中第一模塊包括第一CPU硬件電路與一個指令集,第二模塊包括第二CPU硬件電路與另一指令集。某些實施例涉及一種計算機程序產品(例如,非易失性存儲器裝置),所述計算機程序產品包括機器或計算機可讀媒體,在所述機器或計 算機可讀媒體上存儲有可以由計算機(或其它電子裝置)執行以實施這些操作/活動的指令。基于以上論述和說明,本領域的技術人員將易于認識到,可以對各種實施例作出各種修改和改變,而無需嚴格遵循本文中示出和描述的示例性實施例和應用。舉例來說,如本文中所揭示,聲學情境辨識可用于語音辨識環境和/或將受益于本發明的各種優點的其它基于計算機的音頻辨識應用中。此類修改不脫離本發明的各個方面的真實精神和范圍,包括在權利要求書中闡述的方面。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1