用于執行說話人識別的方法和設備與流程
相關申請
本申請是2014年9月18日提交的美國第14/489996號申請的繼續,且要求該申請的優先權。此處以引證的方式將上述申請的整個示教并入。
背景技術:
語音處理和媒體技術中實現的發展,已經引起自動化用戶機器交互跨不同應用和服務的廣泛使用。使用自動化用戶機器交互方法,企業可以以較便宜的成本提供客戶服務和其他服務。一些這種服務可以采用說話人識別,即說話人的標識和核實(identificationandverification)。
技術實現要素:
本發明的實施方式提供用于說話人識別的方法和系統。根據本發明的實施方式,一種執行說話人識別的方法包括以下步驟:提示用戶說出包括個人標識符和共用短語成分(phrasecomponent)的短語;分解所接收的所說短語,該分解包括定位所說短語內的個人標識符;以及最后基于分解的結果來標識并核實用戶。根據這種實施方式,標識用戶包括:將個人標識符與之前存儲的標識信息進行比較。仍然更進一步地,根據實施方式,分解所接收的所說短語包括:定位共用短語成分,其中,共用短語成分是在所有用戶的至少一個子組內的用戶之間共用的、所說短語的成分。
根據方法的實施方式,核實用戶包括:將共用短語成分與和所有用戶的至少一個子組關聯的一個或更多個之前存儲的聲紋進行比較。在本發明的另選實施方式中,所說短語的共用短語成分包括兩個或更多個短語,并且在這種實施方式中,核實用戶包括:計算共用短語成分的各短語的各自得分。根據這種實施方式,各自得分指示兩個或更多個短語與一個或更多個已存儲的聲紋之間的對應級別。實施方式使用各自得分來核實用戶。在又一個實施方式中,算出各自得分的平均數,然后為了核實用戶,可以將該平均數與預定閾值進行比較。
進一步地,這種原理可以被采用于共用短語成分僅包括一個成分的實施方式中。在這種實施方式中,確定指示所接收所說短語與一個或更多個存儲的聲紋之間的對應級別的得分;當得分大于預定閾值時,核實用戶。根據實施方式,使用關鍵字定位(keywordspotting)來執行分解。在另一個實施方式中,通過首先確定與個人標識符關聯的多個候選用戶,且然后采用語音生物統計標識多個候選用戶中的用戶,來標識用戶。在這種實施方式中,采用語音生物統計包括:針對各候選用戶,將所說短語或所接收所說短語的共用短語成分與對應的之前存儲的聲紋進行比較。
本發明的又一個實施方式致力于用于執行說話人識別的計算機系統。在這種實施方式中,計算機系統包括處理器和上面存儲有計算機代碼指令的存儲器。處理器和存儲器與計算機代碼指令一起被配置為使得計算機系統進行如下操作:提示用戶說出包括個人標識符和共用短語成分的短語;分解所接收的所說短語,該分解包括定位所說短語內的個人標識符;并且基于分解的結果標識并核實用戶。
在計算機系統的實施方式中,標識用戶可以包括將個人標識符與之前存儲的標識信息進行比較。在計算機系統的又一個實施方式中,在分解所接收所說短語時,處理器和存儲器與計算機代碼指令一起被配置為使得系統定位共用短語成分,其中,共用短語成分是在所有用戶的至少一個子組內的用戶之中共用的、所說短語的成分。
在又一個實施方式中,計算機系統被配置為,使得在核實用戶時,計算機系統被配置為將共用短語成分與和所有用戶的至少一個子組關聯的一個或更多個之前存儲的聲紋進行比較。在計算機系統的另選實施方式中,所說短語的共用短語成分包括兩個或更多個短語,并且在核實用戶時,處理器和存儲器與計算機代碼指令一起被配置為使得系統計算共用短語的各短語的各自得分,其中,各自得分指示兩個或更多個短語與一個或更多個所存儲的聲紋之間的對應級別。在這種實施方式中,使用各自得分(例如,通過將得分與閾值進行比較)核實用戶。
類似于上述方法的實施方式,核實用戶可以包括確定指示所接收所說短語與一個或更多個存儲的聲紋之間的對應級別的得分,以及當得分大于預定閾值時核實用戶。計算機系統的實施方式被配置為采用關鍵字定位來分解所接收所說短語。
根據計算機系統的另選實施方式中,在標識用戶時,處理器和存儲器與計算機代碼指令一起還被配置為使得系統進行如下操作:確定與個人標識符關聯的多個候選用戶;并且采用語音生物統計來標識多個候選用戶中的用戶。在計算機系統的又一個實施方式中,在采用語音生物統計時,處理器和存儲器與計算機代碼指令一起還被配置為使得系統進行如下操作:針對各候選用戶,將所說短語或所接收所說短語的共用短語成分與對應的之前存儲的聲紋進行比較。
所要求保護發明的又一個實施方式致力于用于執行說話人識別的計算機程序產品。在這種實施方式中,計算機程序程序產品包括:一個或更多個計算機可讀有形存儲裝置,和存儲在所述一個或更多個存儲裝置中的至少一個上的程序指令,其中,在被處理器加載并執行時,程序指令使得與處理器關聯的設備進行如下操作:提示用戶說出包括個人標識符和共用短語成分的短語;分解所接收的所說短語,包括定位所說短語內的個人標識符;并且基于分解的結果來標識并核實用戶。
附圖說明
如附圖中例示的,根據本發明的示例實施方式的以下更具體的描述,前述內容將變得清楚,在附圖中,同樣的附圖標記貫穿不同的圖涉及相同的零件。附圖不必須為等比例的,而是把重點放在例示本發明的實施方式上。
圖1是可以實施本發明的實施方式的示例環境。
圖2例示了可以用于本發明的實施方式中的、分解所說短語的簡化圖。
圖3是例示了根據本發明的原理的說話人識別的流程圖。
圖4是根據本發明的實施方式的、分解短語并標識并核實用戶的方法的簡化圖。
圖5是可以被配置為實施本發明的實施方式的計算機系統的簡化圖。
圖6是可以實施本發明的實施方式的計算機網絡環境的簡化圖。
具體實施方式
下面是本發明的示例實施方式的描述。
本發明的實施方式解決了在不需要用于提供所要求身份的單獨操作的情況下,使用共用密碼短語說話人核實(commonpassphrasespeakerverification)的問題。然而,之前已經組合自動語音識別(asr:automaticspeechrecognition)和語音生物統計(vb:voicebiometric)來對單個短語實施身份要求核實,這些之前的方法常常依賴整個短語對于各用戶是唯一或多半唯一的。該技術的問題中的一個是,已知唯一的密碼短語具有比共用密碼短語更高的錯誤率。這是因為共用密碼短語大大受益于校準。
本發明的實施方式相反依賴于,含有用于身份要求的唯一成分和共用成分的短語,以便實現更高準確度的語音核實。在這里所述的實施方式中,密碼短語的唯一成分可以使用關鍵字定位(keywordspotting)來提取。這是與現有方法的又一個不同,其中,這種之前的方法將整個短語用于自動語音識別。用于語音和說話人識別的一個現有方法需要兩個操作:第一,提供所要求的身份,和;第二,說出共用核實短語。然而,該兩個操作方法導致用于驗證所要求身份的更長會話。另一個現有方法在一個操作中執行,不過這種方法遭受準確度問題。在這種一個操作方法中,用戶說出諸如賬號或電話號碼這樣的唯一密碼短語,然后用自動語音識別處理該唯一密碼短語,以檢索所要求的身份,隨后用已存儲的聲紋評估該同一唯一的密碼短語,以核實所要求的標識。然而,該方法不具有可以在使用共用短語時實現的準確度益處。
和現有方法不同,本發明的實施方式在不需要用于提供所要求身份的單獨操作的同時,提供現有兩個操作方法的準確度。本發明的另外實施方式通過使用共用密碼短語或幾乎共用密碼短語,來提供比現有一個操作方法更好的說話人核實準確度。
依賴文本的說話人核實是用于商業應用中的主要語音生物統計技術。共用密碼短語核實(即,其中,所有用戶使用同一短語(諸如“我的語音是我的密碼”)來注冊并核實)是最準確形式的依賴文本的說話人核實。共用密碼短語核實允許被稱為校準的強力微調操作,其中,可以對于該具體短語(例如,“我的語音是我的密碼”)微調系統參數。微調使用對應于該具體短語的一組音頻數據來執行。該校準操作允許針對錯誤率大致30%的降低。然而,校準在用戶不使用共用短語而是使用唯一短語時具有遠遠更少的益處。
然而,共用密碼短語核實不是沒有其自己的缺點。將共用短語用于注冊和核實的缺點中的一個是:提供所要求的身份需要單獨的操作。例如,當銀行客戶嘗試憑借語音生物統計來進入他的或她的賬戶時,客戶不能僅說出共用密碼短語,并且希望系統將在潛在的數百萬用戶中準確標識他或她。這是因為說話人標識(speakeridentification)是比說話人核實更困難的問題,并且這種場景中的錯誤率連同計算機處理要求一起,將被禁止成功部署。由此,用戶必須首先提供所要求的身份(諸如賬號、電話號碼或全名),隨后用戶單獨表達語音生物統計密碼短語。
本發明的實施方式在不需要提供所要求身份的單獨操作的情況下,提供共用密碼短語說話人核實的準確度益處。示例實施方式通過使用戶說出含有偽唯一標識符連同共用短語部分這兩者的短語來實施該方法。一個這種示例是“我的名字是約翰史密斯,并且我的語音是我的密碼(mynameisjohnsmith,andmyvoiceismypassword)”。在該短語中,姓名約翰史密斯充當偽唯一標識符,而短語的剩余部分對應于共用短語部分。當提供有這種輸入短語時,自動語音識別或具體地關鍵字定位可以用于提取偽唯一標識符“約翰史密斯”。偽唯一標識符然后可以用于檢索對應于所要求的用戶標識的聲紋約翰史密斯。此時,根據本發明的原理操作的系統可以處理幾乎共用或具有所選聲紋的被提取共用短語成分的完整短語,以核實說話人。另外,在個人標識符不是唯一的情況下(即,如果存在用于約翰史密斯的多項),則可以對于所有項執行聲紋比較,以選擇具有最佳匹配的一項。
還可以更一般地應用上述實施方式。本發明的實施方式可以首先基于可以由asr引擎標識的個人標識符確定候選者的“n最佳”列表。然后可以在聲紋匹配的語境中(即,在標識潛在候選者之后)搜索該“n最佳”列表,可以將用于所標識的候選者的對應已存儲的聲紋與所說短語進行比較,以標識并核實說話人。該方法最后將允許用戶說出:提供所要求身份和共用或幾乎共用密碼短語的單個短語。該處理在語音生物統計共同體中被稱為“id&v”或“標識和核實(identificationandverification)”。盡管id&v之前已經通過僅使用唯一的密碼短語(諸如賬號)來執行,但這種方法產生比本發明的實施方式更低的準確度。
圖1是可以采用本發明的實施方式的環境100的簡化圖。示例環境100包括用戶位置102,從該用戶位置102,用戶101可以經由裝置103撥打電話。裝置103可以是本領域中已知的任意通信裝置,諸如蜂窩電話。環境100還包括計算機處理環境110,該計算機處理環境110在地理上可以與用戶的位置102分離。計算機處理環境110包括服務器108和存儲裝置109。服務器108可以是與本領域中已知相同的任意處理裝置。進一步地,存儲裝置109可以是硬盤驅動器、固態存儲裝置、數據庫或本領域中已知的任意其他存儲裝置。另外,環境110包括網絡111,該網絡111提供用戶位置102與計算機處理環境110之間的通信連接。網絡111可以是本領域中已知的任意網絡,諸如局域網(lan)、廣域網(wan)、公用開關電話網絡(pstn)和/或領域中已知的任意網絡或網絡的組合。
下文中描述在環境100中執行實施方式的示例。根據這種示例,用戶101嘗試聯系銀行的客戶服務中心來咨詢賬戶信息。銀行轉而借助計算環境110進行路由呼叫,以執行用戶101的標識和核實。根據這種實施方式,用戶101經由網絡111使用手持裝置103撥打電話。響應于電話,計算環境110經由服務器108向用戶101發送提示105。示例提示105可以是“請說出‘我的姓名是你的姓名且我的語音是我的密碼’”。用戶101然后響應提示105,并且經由網絡111向計算環境110發送所說短語106。在計算環境110處接收所說短語106。在計算環境110處,分解所說短語,并且標識個人標識符部分(即,“你的姓名”)。服務器108然后基于所分解的結果并使用存儲裝置109上所存儲的信息(諸如聲紋)來標識并核實用戶。作為響應,服務器108然后經由網絡111向用戶101發送標識和核實確認(verificationconfirmation)107。在執行標識和核實之后,計算環境110可以促進用戶101與呼叫中心(諸如銀行客戶服務中心)之間的通信連接。
下文中描述由計算環境110執行的、關于分解以及標識和核實的另外細節。計算環境110連同服務器108和存儲裝置109可以被配置為執行這里所述的任意實施方式。
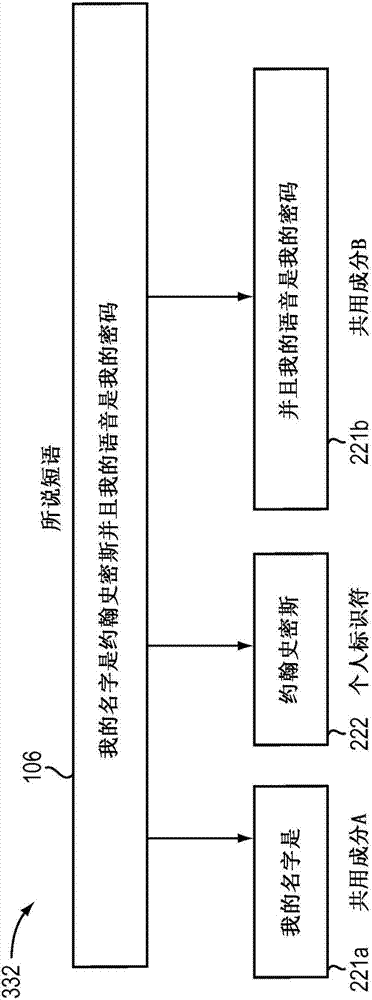
圖2是根據本發明的實施方式的、可以對所說短語執行的分解處理332的簡化圖。如上所述,在實施方式中,當用戶(諸如用戶101)說出提示短語時,分解(332)該短語,使得可以執行用戶的標識和核實。
圖2中的方法332例示了執行所說短語的分解的一個這種方法。根據方法332,所說短語106被分解成共用成分221a和221b以及個人標識符成分222。在這種實施方式中,個人標識符可以使用asr或更具體地使用如本領域中已知的關鍵字定位來標識。共用短語成分221a和221b可以在使用關鍵字定位定位個人標識符222之后進行標識,使得將短語106的剩余部分被標識為共用短語成分221a和221b。在圖2所例示的示例實施方式中,所說短語“我的姓名是約翰史密斯并且我的語音是我的密碼”被分解成:共用成分“我的姓名是”和“并且我的語音是我的密碼”以及個人標識符部分“約翰史密斯”。根據方法332的另選實施方式,該分解可以僅包括標識個人標識符222。
圖3例示了用于執行說話人識別的方法330。方法330通過提示用戶說出包括個人標識符和共用短語成分的短語(331)而開始。接著,分解所接收的所說短語(332)。分解332包括至少定位所接收所說短語中的個人標識符。方法330通過基于分解的結果標識并核實用戶(333)而結束。
分解332可以如上文中關于圖2中描述的來執行。另外,用戶可以根據這里所述的任意實施方式(諸如下文中關于圖4描述的實施方式)來標識并核實(333)。方法330可以由計算環境110在環境100中實施。進一步地,方法330可以在由處理裝置執行的計算機代碼指令中實施。
根據方法330的實施方式,方法330還可以包括以下步驟:通過將個人標識符與之前存儲的標識信息進行比較來標識用戶。更進一步地,在方法330的另選實施方式中,分解還包括定位共用短語成分,其中,共用短語成分是在所說短語在所有用戶的至少一個子組內的用戶之中共用的成分。根據這種實施方式,核實用戶包括:將共用短語成分與和所有用戶的至少一個子組關聯的一個或更多個之前存儲的聲紋進行比較。更進一步地,在又一個實施方式中,共用短語成分例如如圖2中例示地包括兩個或更多個短語,并且核實包括:計算各共用短語成分的各自得分(score)。在這種實施方式中,各自得分指示兩個或更多個短語與一個或更多個存儲的聲紋之間的對應級別;并且核實可以使用該各自得分。可以通過根據任意數學方法使用各自得分來核實用戶,例如可以算出各自得分的平均數,并且可以將平均數與預定閾值進行比較。
方法330的另一個實施方式還包括注冊用戶。根據這種實施方式,注冊用戶包括:提示用戶說出密碼短語或密碼短語的共用成分。然后可以存儲這些所說短語,和/或從所說短語生成一個或更多個聲紋并存儲聲紋。所存儲的短語和/或聲紋然后根據方法330的實施方式然后可以用于執行id&v。
根據方法330的實施方式,標識用戶333包括:把在分解332中標識的個人標識符與之前存儲的標識信息進行比較。根據另選實施方式,分解332還包括:定位共用短語成分,其中,共用短語成分是在所說短語在所有用戶的至少一個子組內的用戶之中共用的成分。在這種實施方式中,核實用戶333包括:將共用短語成分與和所有用戶的至少一個子組關聯的一個或更多個之前存儲的聲紋進行比較。
根據實施方式,“共用短語”成分可以為密碼短語的一個或更多個成分,或者整個密碼短語本身。例如,關于圖2,比較共用短語成分來核實用戶可以包括:比較共用成分221a、221b和/或整個密碼短語106。根據實施方式,核實用戶333包括:計算共用短語成分(即,221a和221b)的各短語的各自得分,其中,各自得分指示各短語與一個或更多個已存儲的聲紋之間的對應級別。反過來,可以使用各自得分來核實用戶(333)。
根據另選實施方式,還可以通過將整個短語與一個或更多個存儲的聲紋進行比較來確定得分。更進一步地,可以分別對于整個短語106和對于各成分221a和221b確定得分,然后這些得分可以用于核實用戶(333)。例如,可以算出得分的平均數,然后可以將平均數與閾值進行比較,并且當得分在閾值以上時,該用戶可以被認為已核實。進一步地,可以對于短語的單個成分或成分的某一組合來確定得分,然后這些一個或更多個得分用于核實用戶。根據實施方式,所說短語的最長部分如可以由本領域一個技術人員確定地,可以用于核實用戶的聲紋比較,或密碼短語具有最高質量音頻的部分或某一其他部分。
根據方法330的實施方式,使用關鍵字定位來執行分解。在實施方式中,采用語音生物統計包括:對于各候選用戶,將所說短語或所接收的所說短語的共用短語成分,與對應的之前存儲的聲紋進行比較。在又一個實施方式中,標識用戶包括:確定與個人標識符關聯的多個候選用戶,且然后采用語音生物統計來標識多個候選用戶中的用戶。這種示例可能在例如所說的個人標識符類似于系統中所存儲的其他個人標識符的情況下發生。例如,如果系統存儲約翰史密斯、湯姆史密斯以及約翰史密斯,則這些可能足夠類似,使得系統在用戶說出一個時無法區分個人標識符。那么,在這種實施方式中,語音生物統計用于選擇人。
圖4例示了根據使用本發明的原理的示例實施方式的、執行說話人識別(標識和核實)的方法440。具體地,方法440例示了處理所接收的所說短語的示例方法。方法440可以在圖3中例示,且在上文中描述的方法330中采用。方法440通過定位個人標識符和在所有用戶的至少一個子組內的用戶之中共用的、所接收的所說短語的共用短語成分(441)而開始。方法440通過將個人標識符與可以和所有用戶的至少一個子組關聯的、之前存儲的標識信息進行比較(442)以標識用戶而繼續。最后,將共用短語成分與一個或更多個之前存儲的聲紋進行比較來核實用戶(443),其中,聲紋可以與用戶的至少同一個子組關聯。
可以在方法330的分解操作332中采用定位441。如這里所述的,使用共用短語成分可以提高標識和核實的準確度。然而,根據本發明的實施方式,具有共用短語成分的“組”可以是有利的(即,將提示不同分組的人來說出不同的共用短語成分)。例如,可以基于人們從其呼叫的地理位置、人們嘗試聯系的具體號碼、或優選語言來提示他們說出密碼短語。作為示例,可以提示具有可能由賬戶余額確定的優選狀態的用戶來說出不同的密碼短語。在又一個示例中,在多語言部署中,例如在加拿大,一些用戶可以被提示用法語說出密碼短語,而其他用戶被提示用英語說出密碼短語。在這種示例中,一個子組對應于使用法語密碼短語的用戶,而另一個子組對應于使用英語密碼短語的用戶。在示例實施方式中,分解441可以考慮子組,換言之,分解被配置為,根據子組的一個或更多個特性(即,語言)來尋找適當的成分。
比較個人標識符(442)和比較共用短語成分(443)可以在方法330的比較操作333處執行。根據實施方式,比較個人標識符(442)標識用戶。比較個人標識符(442)還可以標識多個“候選用戶”(即,可能已經說出密碼短語的可能人)。這種示例可能在例如所說的個人標識符類似于系統中所存儲的其他個人標識符的情況下發生。在這種實施方式中,當將個人標識符與之前存儲的標識信息進行比較時,標識多個候選用戶。然后,可以通過將共用短語成分與一個或更多個之前存儲的聲紋進行比較采用語音生物統計來標識多個候選用戶中的用戶(443)。在將個人標識符與之前存儲的標識信息進行比較(442)、和將共用短語成分與一個或更多個之前存儲的聲紋進行比較(443)這兩者時,可以在用戶的整個全集級別或在用戶某一子組處進行這種比較。例如,如果用戶所說的密碼短語僅與用戶的子組關聯,則比較442和443可以僅使用與用戶的所述子組關聯的數據來執行。這種實施方式可以允許更高效的處理。
根據本發明的實施方式,聲紋可以基于用戶所說的實際語音表達。例如,在建立銀行賬戶時,可能需要用戶說出所說短語、所說短語的某一部分,并且可以存儲該信息,以便另外使用,諸如如這里所述的標識和核實。還可以處理初始的所說短語,以產生可以是語音表達的模型或參數表示的聲紋。
圖5是根據本發明的實施方式的、可以用于執行標識和核實的基于計算機的系統550的簡化框圖。系統550包括總線554。總線554充當系統550的各種部件之間的互連。連接到總線554的是:用于將各種輸入和輸出裝置(諸如鍵盤、鼠標、顯示器、揚聲器等)連接到系統550的輸入輸出裝置接口553。中央處理單元(cpu)552連接到總線554,并且為計算機指令的執行做準備。存儲器556為用于執行計算機指令的數據提供易失性存儲。儲存器555為諸如操作系統(未示出)這樣的軟件指令提供非易失性存儲。系統550還包括用于連接到本領域中已知的任意種類的網絡(包括wan和lan)的網絡接口551。
應理解的是,這里所述的示例實施方式可以以許多不同的方式來實施。在一些情況下,這里所述的各種方法和機器可以各由實體、虛擬或混合通用計算機(諸如計算機系統550)或計算機網絡環境(諸如下文中描述的計算機環境600)來實施。計算機系統550可以被轉換成:例如通過將軟件指令加載到存儲器556或非易失性儲存器555以便由cpu552執行來執行這里所述方法的機器。系統550及其各種部件可以被配置為,進行這里所述的本發明的任意實施方式。
例如,系統550可以被配置為執行上文中關于圖3描述的方法330。在這種示例實施方式中,cpu552和存儲器556與在存儲器556和/或存儲裝置555上存儲的計算機代碼指令一起將設備550配置為:提示用戶說出包括個人標識符和共用短語成分的短語;分解所接收的所說短語,其中,分解的步驟包括定位所說短語內的個人標識符;并且基于分解的結果來標識并核實用戶。
圖6例示了可以實施本發明的計算機網絡環境600。在計算機網絡環境600中,服務器601借助通信網絡602聯系到客戶端603a-n。環境600可以用于允許客戶端603a-n單獨或結合服務器601執行上述的各種方法。在示例實施方式中,客戶端603a經由網絡602向服務器601發送所接收的所說短語604。服務器601然后執行如這里所述的說話人識別方法(諸如方法330),并且因此經由網絡602向客戶端603a發送標識和核實確認605。在這種實施方式中,客戶端603a例如可以為銀行,并且響應于客戶聯系銀行,銀行可以采用在服務器601上實施的方法來執行用戶的標識和核實。
實施方式或其方面可以以硬件、固件或軟件的形式來實施。如果在軟件中實施,則軟件可以存儲在被配置為使得處理器能夠加載軟件或其指令的子集的任意永久計算機可讀介質上。處理器然后可以執行指令,并且被配置為操作或使得設備以如這里所述的方式來操作。
進一步地,固件、軟件、例程或指令在這里可以被描述為執行數據處理器的特定動作和/或功能。然而,應理解,這里所含的這種描述僅是為了方便,并且實際上因計算裝置、處理器、控制器或其他裝置執行固件、軟件、例程、指令等而產生這種動作。
還應理解,流程圖、框圖以及網絡圖可以包括更多或更少元件,被不同地設置,或者被不同地表示。但進一步應理解,特定實施方案可以指定:例示了以特定方式實施的實施方式的執行的框圖和網絡圖以及框圖和網絡圖的數量。
因此,另外的實施方式還可以以各種計算機架構、實體、虛擬、云計算機和/或其一些組合來實施,由此,這里所述的數據處理器旨在僅為了例示的目的,并且不為實施方式的限制。
雖然已經參照本發明的示例實施方式具體示出并描述了本發明,但本領域技術人員將理解,可以在不偏離由所附權利要求包含的本發明的范圍的情況下,在本發明內進行形式和細節的各種變更。
- 還沒有人留言評論。精彩留言會獲得點贊!