音頻數據處理方法和裝置與流程
本發明涉及計算機應用技術領域,特別涉及一種音頻數據處理方法和裝置。
背景技術:
隨著媒體應用的發展,針對音頻數據進行編輯的應用越來越多,不再僅限于實現各種音頻數據的采集和播放,而更為專注于音頻數據的編輯,以采集的音頻數據為原聲來實現豐富多樣的音頻數據輸出。
例如,在為用戶提供的K歌功能中,對于采集得到的音頻數據,大都實際對其進行編輯,以附加了一定的音效之后才由輸出,以供聽眾收聽。在對音頻數據所進行的編輯中,如需實現和聲音效的模擬,所對應的實現方式是以采集的音頻數據,即輸入的人聲作為原聲,在此基礎上將其它人聲以某個數量某個比例疊加在原聲上,便可得到用以輸出的音頻數據。
然而,這一和聲音效模擬的實現是對整個原聲都附加了和聲音效,即在整個時間段上均進行了和聲,這有悖于真實場景中的和聲,存在著和聲音效模擬失真的局限性。
技術實現要素:
基于此,有必要提供一種音頻數據處理方法,該方法能夠避免整個音頻數據在整個時間段均附加和聲音效,提高和聲模擬的真實性。
此外,還有必要提供一種音頻數據處理裝置,該裝置能夠避免整個音頻數據在整個時間段均附加和聲音效,提高和聲模擬的真實性。
為解決上述技術問題,將采用如下技術方案:
一種音頻數據處理方法,包括:
根據待處理的音頻數據獲取對應的歌詞文件;
按照所述歌詞文件中的句子分割所述音頻數據,以得到音頻數據段;
提取所述音頻數據段中尾音所對應的數據;
對所述尾音所對應的數據進行和聲處理。
一種音頻數據處理裝置,包括:
歌詞獲取模塊,用于根據待處理的音頻數據獲取對應的歌詞文件;
分割模塊,用于按照所述歌詞文件中的句子分割所述音頻數據,以得到音頻數據段;
提取模塊,用于提取所述音頻數據段中尾音所對應的數據;
尾音處理模塊,用于對所述尾音所對應的數據進行和聲處理。
由上述技術方案可知,對于任一需進行和聲模擬的音頻數據,首先獲取該音頻數據對應的歌詞文件,按照歌詞文件中的句子對音頻數據進行分割,以得到音頻數據段,提取音頻數據段中尾音所對應的數據,以對該數據進行和聲處理,也就是說,在對該音頻數據所進行的編輯中,將在該音頻數據中僅對尾音所對應的數據進行和聲,而不再對整個音頻數據在整個時間段進行和聲,進而使得和聲模擬的實現與實際唱歌時進行的和聲相一致,提高了和聲模擬的真實性。
附圖說明
圖1是本發明實施例提供的一種電子設備的結構示意圖;
圖2是一個實施例中音頻數據處理方法的流程圖;
圖3是圖2中根據待處理的音頻數據獲取對應的歌詞文件的方法流程圖;
圖4是圖2中按照歌詞文件中的句子分割音頻數據,以得到音頻數據段的方法流程圖;
圖5是一個實施例中根據預設的尾音長度值在音頻數據段中提取尾音所對應的數據的方法流程圖;
圖6是圖2中對尾音所對應的數據進行和聲處理的方法流程圖;
圖7是一個實施例中音頻處理裝置的結構示意圖;
圖8是圖7中歌詞獲取模塊的結構示意圖;
圖9是圖7中分割模塊的結構示意圖;
圖10是圖7中提取模塊的結構示意圖;
圖11是圖7中尾音處理模塊的結構示意圖。
具體實施方式
體現本發明特征與優點的典型實施方式將在以下的說明中詳細敘述。應理解的是本發明能夠在不同的實施方式上具有各種的變化,其皆不脫離本發明的范圍,且其中的說明及圖示在本質上是當作說明之用,而非用以限制本發明。
如前所述的,對音頻數據進行的各種編輯中,如若需要對輸入的人聲附加和聲音效,則必須針對輸入的整個人聲進行,即對輸入的整個人聲均添加和聲音效。因此,雖然現有的音頻數據編輯中可對輸入的任一音頻數據添加所需要的音效,但是,對于和聲音效而言,也僅僅是生硬地將其它人聲直接疊加于該音頻數據中,以使得整個音頻數據均附帶了和聲音效,雖然達到了和聲的目的,但是缺乏真實性,并無法呈現真實場景中的和聲效果。
因此,為確保模擬的真實性,可呈現真實場景中的和聲效果,特提出了一種音頻數據處理方法,該音頻數據處理方法由計算機程序實現,與之相對應的,所構建的音頻數據處理裝置則被存儲于電子設備中,以在該電子設備中運行,進而實現任一音頻數據的和聲。
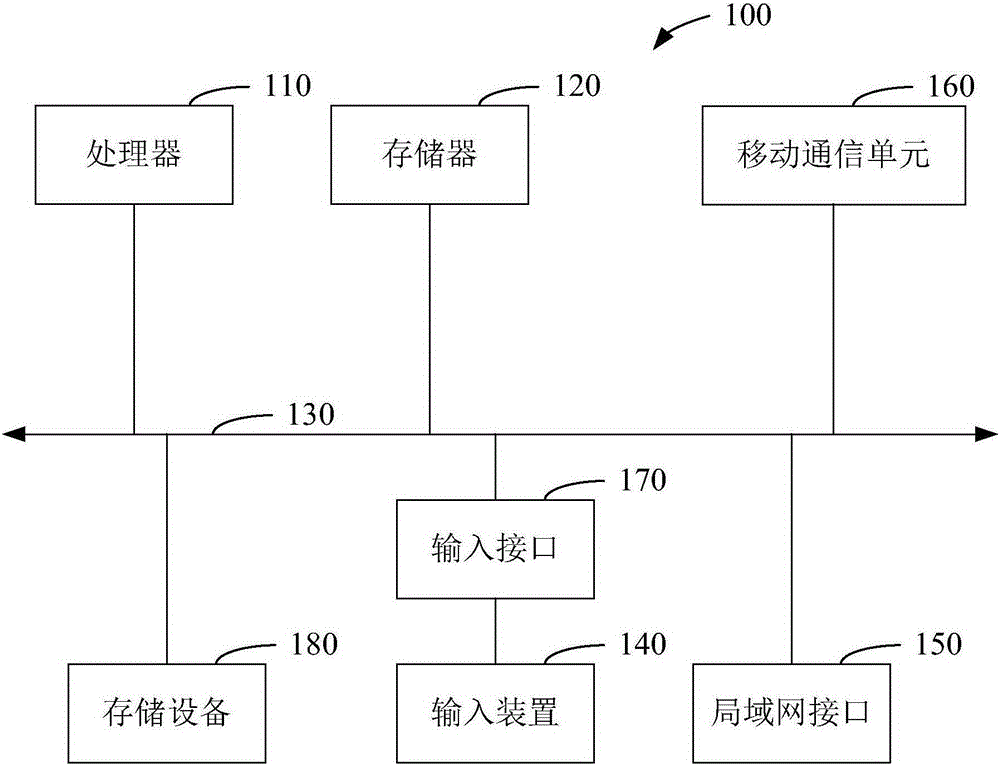
圖1示出了本發明實施例提供的一種電子設備的結構。該電子設備100只是一個適配于本發明的示例,不能認為是提供了對本發明的使用范圍的任何限制。該電子設備100也不能解釋為需要依賴于或具有圖示的示例性的電子設備100中的一個或者多個部件的組合。
如圖1所示,電子設備100包括處理器110、存儲器120和系統總線130。包括存儲器120和處理器110在內的各種組件將連接到系統總線130上。處理器110是一個用于通過計算機系統中基本的算術和邏輯運算來執行計算機程序指令的硬件。存儲器120是一個用于臨時或永久性存儲計算機程序或數據的物理設備。
其中,存儲器120中存儲了若干音頻數據以及各種歌詞文件;處理器110將執行存儲器120中的程序指令。
便攜終端設備100還包括各種輸入接口170、輸入裝置140,以實現各種操作的輸入。其中,該輸入裝置140可以是觸摸屏幕、按鍵、鍵盤和鼠標等至少一種。
便攜終端設備100還包括存儲設備180,存儲設備180可以從多種計算機可讀存儲介質中選擇,計算機可讀介質是指可以進行訪問的任何可利用的介質,包括移動的和固定的兩種介質。例如,計算機可讀介質,包括但不限于閃速存儲器(微型SD卡)、CD-ROM、數字通用光盤(DVD)或其它光盤、磁帶盒、磁帶存儲或其它存儲設備、或者可用于存儲所需信息并可訪問的任何其它介質。
如上面所詳細描述的,適用本發明的電子設備100將執行實現和聲音效的指定操作,即通過處理器110運行存儲器120中的程序指令的形式執行該指定操作,以實現電子設備100中音頻數據的處理。
此外,通過硬件電路或者硬件電路結合軟件指令也能同樣實現本發明,因此,實現本發明并不限于任何特定硬件電路、軟件以及兩者的組合。
在一個實施例中,具體的,該音頻數據處理方法如圖2所示,包括:
步驟210,根據待處理的音頻數據獲取對應的歌詞文件。
該音頻數據是當前進行編輯的音頻數據,其可為用戶在演唱某一歌曲時錄入的音頻數據,也可以是用戶預先演唱某一歌曲而預先錄入的音頻數據。因此,對該音頻數據的編輯可以是實時進行的,也可以是對該音頻數據所進行的后續編輯。
根據該音頻數據所屬的歌曲,獲取對應的歌詞文件,以便以歌詞文件為依據進行該音頻數據的和聲模擬。
步驟230,按照歌詞文件中的句子分割音頻數據,以得到音頻數據段。
歌詞文件的內容包含了歌曲的每一句歌詞以及各種相關的時間點,因此,可按照歌詞文件中的句子進行音頻數據分割,以得到與句子相對應的音頻數據段。例如,若該音頻數據是針對整首歌曲所錄入的,則根據歌詞文件中句子所進行的分割,將得到每一句子所對應的音頻數據段。
若該音頻數據是當前實時錄入的,則按照其在歌詞文件中對應的句子進行分割,以隨著音頻數據的不斷錄入而不斷分割得到音頻數據段。
步驟250,提取音頻數據段中尾音對應的數據。
在音頻數據段中根據其尾音進行數據提取,以得到尾音所對應的數據。由此對于分割得到的若干音頻數據段而言,便得到了每一音頻數據段中尾音所對應的數據。
步驟270,對尾音所對應的數據進行和聲處理。
僅針對音頻數據段中尾音所對應的數據進行和聲處理,以得到僅在尾音進行和聲音效模擬的音頻數據段,進而由該音頻數據段構成了和聲音效模擬的音頻數據,輸出的音頻數據附帶了和聲音效,并且在該音頻數據的輸出中僅在尾音部分進行的和聲音效的模擬,與真實場景中的和聲相一致,進而保證了和聲模擬的真實性。
進一步的,在本實施例中,如圖3所示,在一個實施例中,該步驟210包括:
步驟211,根據待處理的音頻數據得到所屬歌曲。
步驟213,獲取所屬歌曲對應的歌詞文件。
該音頻數據對應的歌詞文件可以為任意形式,但其內容則必定包含了多個句子以及每一句子對應的起止時間點,即每一句子的起始時間和終止時間。
進一步的,在實際運營中,歌詞文件中的內容包含了歌詞所對應的文字以及該文字所對應的時間點,在此,將首先確定每一句子首尾所分別對應的文字,進而得到該句子首尾所對應的時間點,該句子首尾所對應的時間點即為句子的起始時間和終止時間。
在一個實施例中,如圖4所示,該步驟230包括:
步驟231,提取歌詞文件中句子的起始時間和終止時間。
在歌詞文件中進行句子的起始時間和終止時間的提取,句子之間將以時間為界線進行區分。
需要說明的是,如若歌詞文件中句子之間存在著間隔,則該間隔可歸屬于上一句子的尾端或者下一句子的首端,與之相對應的,該終止時間將為間隔末端所對應的時間,或者,該起始時間為間隔前端所對應的時間。
步驟233,根據起始時間和終止時間分割音頻數據,得到句子對應的音頻數據段。
音頻數據中的時間是與歌詞文件中的時間相一致的,因此,可根據歌詞文件中的時間分割得到句子對應的音頻數據段。
也就是說,對于演唱歌曲所錄入的音頻數據而言,其演唱內容與歌詞文件中的歌詞和時間點相對應,因此,與歌詞文件中的句子處于相同時間段的數據即為該句子所對應的音頻數據段。
例如,一句歌詞的尾音是3秒,則該句歌詞對應的音頻數據段中的3秒即為該音頻數據段中的15秒至18秒所對應的數據,這一15秒至18秒所對應的數據即為該音頻數據段中尾音所對應的數據。
進一步的,在本實施例中,該步驟250包括:根據預設的尾音長度值在音頻數據段中提取尾音所對應的數據。
預先設定了尾音長度值,該尾音長度值為一時間值,將表征了尾音所對應的時間長度。優選地,該尾音長度值可預選設定為3秒。
在每一音頻數據段中根據預設的尾音長度值即可確定尾音所對應的數據,進而直接提取即可。也就是說,每一音頻數據段中尾部時間長度與該尾音長度值相匹配的數據即為尾音所對應的數據。
進一步的,在本實施例中,如圖5所示,該根據預設的尾音長度值在音頻數據段中提取尾音所對應的數據的步驟包括:
步驟251,根據音頻數據段所屬句子對應的終止時間和預設的尾音長度值得到尾音開始時間。
通過依據起始時間和終止時間所進行的音頻數據分割,使得該分割的音頻數據段與歌詞文件中的句子相對應。由此,每一音頻數據段均有所屬的句子,進而得到該句子對應的終止時間。
終止時間和預設的尾音長度值之間的差值即為尾音開始時間,尾音開始時間將作為音頻數據段中尾音所對應的數據提取的起始點。
步驟253,根據尾音開始時間和音頻數據的采樣率在音頻數據段中定位尾音所對應的起始數據。
音頻數據段中每一數據都有對應的時間,也就是說,可根據其所對應的時間可根據其在音頻數據中的位置以及采樣率確定,即t = n/fs,其中,t為數據所對應的時間,n是該數據在音頻數據中的坐標,fs則是音頻數據的采樣率。
由此可知,根據尾音開始時間和音頻數據的采樣率即可運算得到時間為尾音開始時間所對應的音頻數據中的坐標,進而在音頻數據段中定位數據,以得到尾音所對應的起始數據。
步驟255,在音頻數據段中由以起始數據為起始進行數據提取直至提取至音頻數據段的尾端,以得到尾音所對應的數據。
在音頻數據段中,將直接以起始數據為起始依次往后進行數據提取,直至提取至所在音頻數據段的尾端,由此所得到的數據即為尾音所對應的數據,以待后續針對該提取的數據進行和聲。
通過如上所述的過程,將使得分割得到的音頻數據段均相應提取得到尾音所對應的數據,進而由該數據實現每一音頻數據段中的和聲音效模擬,從而完成整個音頻數據中的和聲音效模擬,并且提高了音效模擬的真實性。
需要說明的是,如若句子之間的間隔歸屬于上一句子對應的音頻數據段,則尾音所對應的數據提取過程將對起始數據和間隔末端之間的數據提取過程。也就是說,對于附加了間隔的音頻數據段,將仍然根據起始數據次往后進行數據提取,由此得到包含該間隔的尾音所對應的數據。
在后續的和聲處理中,對于包含間隔的尾音所對應的數據,也將直接對其進行和聲處理即可。
在一個實施例中,如圖6所示,該步驟270包括:
步驟271,以尾音所對應的數據為原聲,復制原聲并進行降調處理得到中間數據。
復制一份尾音所對應的數據,以任一尾音所對應的數據為原聲,對另一尾音所對應的數據進行降調處理,以得到中間數據。其中,用于實現降調處理的算法可以為任意的pitch shift相關的算法。
步驟273,復制若干份中間數據,以分別對每份中間數據進行隨機延遲和衰減處理得到若干份和聲音效數據。
通過如上所述的步驟得到一作為原聲的尾音所對應的數據和中間數據,此時,將中間數據s’(n)復制成L份,每份加入一個隨機的延遲和隨機的衰減,即s’’ = r*s’(n - P),其中r為純小數,P正數,s’’即為任一和聲音效數據。
步驟275,將原聲和和聲音效數據疊加得到模擬和聲的音頻數據。
將L個s’’與原聲疊加在一起便可得到音頻數據段中模擬了和聲的尾音,進而實現了音頻數據段中的和聲模擬,多個音頻數據段拼接在一起即可得到待輸出的音頻數據。
如若以包含了間隔的尾音所對應的數據為原聲,和聲音效數據也是以該包含了間隔的尾音所對應的數據為基礎所處理得到的,因此,尾音所對應的數據中,與間隔對應的部分將為空,相對應的,和聲音效數據中,與間隔對應的部分也將為空,因此,在原聲和和聲音效數據進行的疊加中,該數據為空的部分也將疊加在一起,得到模擬了和聲并仍然包含間隔的尾音,從而既實現了尾音中和聲的模擬,又不會對原有的音頻數據中存在的間隔造成影響。
在具體的應用中,對于如上所述的音頻數據處理方法,將首先需要獲取一對應的歌詞文件,歌詞文件中每一句子的起始時間s(m)和終止時間d(m),其中,m代表歌詞文件中的第m句句子。起始時間s(m)和終止時間d(m)也為該句子對應的音頻數據段的起始點和終止點。
假設待處理的音頻數據為x(n),n為小于N的整數,該音頻數據的總長度為N。
預設尾音長度值為T,T=3秒,則由此得到音頻數據段中的尾音開始時間ts(m),即ts(m) = d(m) -T,從而在每一音頻數據段中分別聚集出尾音所對應的數據s(n)。
復制一份s(n),并對復制所得到的s(n)進行降調處理得到中間數據s’(n)。
此時,復制L份中間數據s’(n),每一份中間數據s’(n)均加入隨機的延遲和隨機的衰減,即s’’= r*s’(n - P),其中r為純小數,P正數。
將L份s’’與s(n)進行疊加得到模擬了和聲的尾音y(n)。
通過如上所述的過程便對音頻數據精準實現了尾音的和聲模擬。
通過如上所述的音頻數據處理方法,將使得各種音頻應用,例如,K唱應用可對音頻數據實現和聲模擬,極大地豐富了音頻應用中的功能。
在一個實施例中,還相應地提供了一種音頻數據處理裝置,如圖7所示,該裝置包括歌詞獲取模塊310、分割模塊330、提取模塊350和尾音處理模塊370,其中:
歌詞獲取模塊310,用于根據待處理的音頻數據獲取對應的歌詞文件。
分割模塊330,用于按照歌詞文件中的句子分割音頻數據,以得到音頻數據段。
提取模塊350,用于提取單元數據段中尾音所對應的數據。
尾音處理模塊370,用于對尾音所對應的數據進行和聲處理。
在一個實施例中,如圖8所示,該歌詞獲取模塊310包括所屬歌曲獲取單元311和文件獲取單元313,其中:
所屬歌曲獲取單元311,用于根據待處理的音頻數據得到所屬歌曲。
文件獲取單元313,用于獲取所屬歌曲對應的歌曲文件。
在一個實施例中,如圖9所示,該分割模塊330包括時間提取模塊331和數據分割單元333,其中:
時間提取模塊331,用于提取歌詞文件中句子的起始時間和終止時間。
數據分割單元333,用于根據起始時間和終止時間分割音頻數據,得到句子對應的音頻數據段。
在一個實施例中,提取模塊350進一步用于根據預設的尾音長度值在音頻數據段中提取尾音所對應的數據。
進一步的,在本實施例中,如圖10所示,該提取模塊350包括尾音時間運算單元351、起始數據定位單元363和數據提取單元355,其中:
尾音時間運算單元351,用于根據音頻數據所屬句子對應的終止時間和預設的尾音長度值得到尾音開始時間。
起始數據定位單元353,用于根據尾音開始時間和音頻數據的采樣率在音頻數據段中定位尾音所對應的起始數據。
數據提取單元355,用于在音頻數據段中以起始數據為起始進行數據提取,直至提取至音頻數據段的尾端,以得到尾音對應的數據。
在一個實施例中,如圖 11所示,該尾音處理模塊370包括降調處理單元371、音效生成單元373和疊加單元375,其中:
降調處理單元372,用于以尾音所對應的數據為原聲,復制該原聲并進行降調處理得到中間數據。
音效生成單元373,用于復制若干份中間數據,以分別對每份中間數據進行隨機延遲和衰減處理得到若干份和聲音效數據。
疊加單元375,用于將原聲和和聲音效數據混合疊加得到模擬和聲的音頻數據。
本領域普通技術人員可以理解實現上述實施例的全部或部分步驟可以通過硬件來完成,也可以通過程序來指令相關的硬件完成,所述的程序可以存儲于一種計算機可讀存儲介質中,上述提到的存儲介質可以是只讀存儲器,磁盤或光盤等。
雖然已參照幾個典型實施方式描述了本發明,但應當理解,所用的術語是說明和示例性、而非限制性的術語。由于本發明能夠以多種形式具體實施而不脫離發明的精神或實質,所以應當理解,上述實施方式不限于任何前述的細節,而應在隨附權利要求所限定的精神和范圍內廣泛地解釋,因此落入權利要求或其等效范圍內的全部變化和改型都應為隨附權利要求所涵蓋。
- 還沒有人留言評論。精彩留言會獲得點贊!