自適應不同用戶的智能顯示裝置的制作方法
本發明涉及顯示領域,具體而言,尤其涉及一種自適應不同用戶的智能顯示裝置。
背景技術:
單屏或多屏顯示,在會展、培訓、酒店、商場等等領域得到廣泛的商業應用。隨著科技的飛速發展進步,顯示裝置的應用已經深入到各行各業中,尤其是液晶顯示及led顯示器已經愈發廣泛,而目前又有許多廣告牌或宣傳牌直接采用顯示器作為其播放內容的媒介,所以使得顯示裝置的使用范圍更加廣泛。
在日常生活中,許多城市中的交通道路人流量、車流量很大,許多商家借此在十字路口、轉彎路口、與馬路相鄰的某些住宅小區門口及學校門口等場所設置一些用于播放公益廣告的顯示裝置和用于播放閱讀、科普或廣告的顯示裝置等作為廣告宣傳設施。但是,現今的道路上的顯示屏等設施功能單一,廣告形式往往過于單一,而且播放的次序往往是預設的,廣告無法做到自適應不同用戶的人群,無法與大眾形成互動,影響了廣告的效果,同時容易使行人產生視覺疲勞,既造成了資源的浪費又無法產生預期的廣告效果。
技術實現要素:
本發明的目的是克服現有技術存在的不足,提供一種自適應不同用戶的智能顯示裝置。
本發明的目的通過以下技術方案來實現:
一種自適應不同用戶的智能顯示裝置,至少包括設置在顯示裝置上用于儲存至少一將被顯示的多媒體數據物件的儲存裝置、用以決選一所述儲存裝置內的多媒體數據物件的處理裝置以及用以將所述處理裝置選擇的多媒體數據物件進行播放的播放器,還包括與所述處理裝置連接的智能音箱,所述智能音箱用以對用戶的語音信息進行解析并回應相應的視音頻信息或/和用以對用戶的人臉進行識別并在所述播放器上播放相應年齡段的視頻或圖片信息。
優選的,所述播放器至少包括用于播放公益廣告或公益宣傳的第一顯示裝置和用于播放閱讀、科普或廣告的第二顯示裝置。
優選的,所述智能音箱包括用以對用戶的語音信息進行解析的語音識別裝置,所述語音識別裝置至少包括用于獲取用戶語音信息的語音獲取裝置,所述語音獲取裝置與內置有存儲器、運算器及處理器的神經計算棒連接,所述神經計算棒用以對所述語音獲取裝置所接收的語音信息進行解析,解析完成后在其內置的存儲器中進行搜索相應答案,并將相應答案轉換成文本信息或/和視頻或圖片信息發送至所述處理裝置,所述處理裝置接收到所述神經計算棒傳送的相應答案在所述播放器中以文本或/和視頻或圖片信息顯示出來。
優選的,所述語音識別裝置內還包括麥克風,所述麥克風與所述神經計算棒連接。
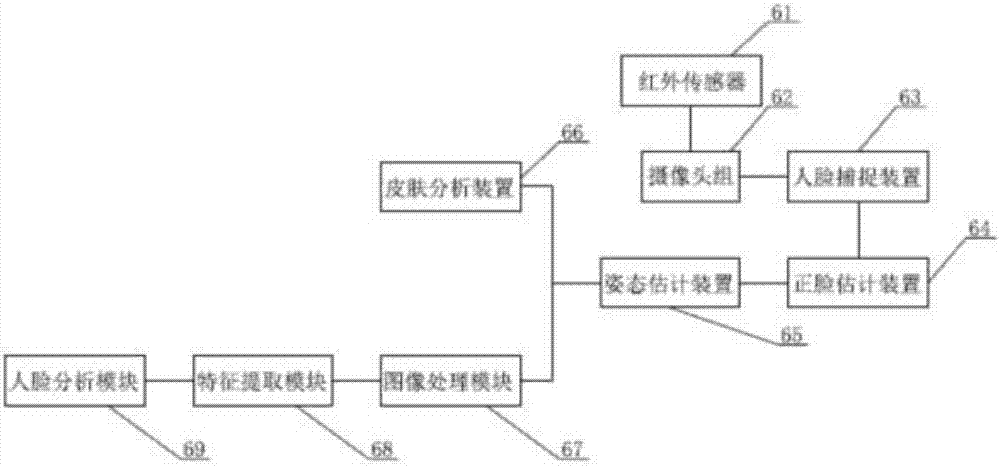
優選的,所述智能音箱包括用于對用戶的人臉進行識別的人臉識別裝置,所述人臉識別裝置至少包括依次連接的用于監測區域空間內來自人體的紅外線的紅外傳感器、用以對所述紅外傳感器所檢測的人體從不同角度同時進行拍攝視角圖像的攝像頭組以及用以對所述攝像頭組拍攝的圖像進行人臉圖像捕捉的人臉捕捉裝置,所述人臉捕捉裝置與用于初步估計所述人臉捕捉裝置所捕捉的人臉的偏航角,并檢測到偏航角最小的人臉視角圖像的正臉估計裝置連接;所述人臉識別裝置還包括從一個姿態正的人臉三維模型獲得所述正臉估計裝置的預定人臉特征點的三維坐標以及從所述正臉估計裝置中檢測所述預定人臉特征點的二維坐標,根據獲得的所述預定人臉特征點的二維坐標和三維坐標計算相對于拍攝所述具有偏航角最小的人臉的視角圖像的圖像捕捉設備的第一頭部姿態的姿態估計裝置,所述姿態估計裝置與所述正臉估計裝置連接,所述人臉識別裝置將識別后的用戶的年齡段傳送至內置有存儲器、運算器及處理器的神經計算棒,所述神經計算棒對所述人臉識別裝置傳輸的數據進行解析,解析完成后在其內置的存儲器中進行搜索相應答案,并將相應答案轉換成相應數據發送至處理裝置,所述處理裝置接收到所述神經計算棒傳送的相應答案在所述播放器中以文本或/和視頻或圖片信息顯示出來。
優選的,所述姿態估計裝置還包括:
三維坐標獲取模塊,根據預定人臉特征點在所述人臉三維模型上的位置,獲得預定人臉特征點的三維坐標;
特征點檢測模塊,從所述檢測的視角圖像中檢測預定人臉特征點,并獲得檢測的預定人臉特征點的二維坐標;
姿態估計模塊,利用獲得的預定人臉特征點的二維坐標和三維坐標來計算第一頭部姿態。
優選的,所述姿態估計裝置計算的所述第一頭部姿態包括俯仰角、偏航角、滾轉角,其中,
偏航角
俯仰角
滾轉角
其中,頭部姿態信息
其中,a為預定人臉特征點的三維坐標,b為預定人臉特征點的二維坐標。
優選的,所述姿態估計裝置將正臉圖像發送至皮膚分析裝置,所述皮膚分析裝置用以對正臉的色澤和色度進行檢測,并將檢測后的數據與所述皮膚分析裝置內置的數據庫進行對比,從而判定出人體的年齡段,所述皮膚分析裝置將判定后的數據發送至所述處理裝置。
優選的,所述姿態估計裝置將正臉圖像發送至圖像處理模塊,所述圖像處理模塊用于對人臉的正臉圖像進行灰度化、光照補償預處理,從而獲得灰度圖像,所述圖像處理模塊與用于從所述圖像處理模塊上提取出人臉部分特征值的特征提取模塊連接,所述特征提取模塊與用于將所述特征提取模塊提取出的人臉部分特征值與人臉數據庫存儲區所存儲的各年齡段的人臉數據進行比對的人臉分析模塊連接,所述人臉分析模塊將對比后的數據發送至所述處理裝置。
優選的,所述智能音箱與后端平臺連接,所述后端平臺與復數個客戶端無線連接,所述客戶端上設有app軟件。
本發明的有益效果主要體現在:結構簡單精巧,通過人臉識別裝置可以根據不同用戶、不同性別選擇性播放與其相適應的公益廣告、科普、閱讀及公益宣傳等,以滿足不同人的需求,同時,語音識別裝置可和神經計算棒相配合通過視音頻多元化的方式實現對用戶的問題的回答,與用戶之間形成互動,極大的增加了趣味性。
附圖說明
下面結合附圖對本發明技術方案作進一步說明:
圖1:本發明的結構示意圖;
圖2:本發明人臉識別裝置的結構示意圖;
圖3:本發明語音識別裝置的結構示意圖。
具體實施方式
以下將結合附圖所示的具體實施方式對本發明進行詳細描述。但這些實施方式并不限于本發明,本領域的普通技術人員根據這些實施方式所做出的結構、方法、或功能上的變換均包含在本發明的保護范圍內。
如圖1至圖3所示,本發明揭示了一種自適應不同用戶的智能顯示裝置,至少包括設置在顯示裝置上用于儲存至少一將被顯示的多媒體數據物件的儲存裝置1、用以決選一所述儲存裝置1內的多媒體數據物件的處理裝置2以及用以將所述處理裝置2選擇的多媒體數據物件進行播放的單屏或多屏的播放器3,所述播放器3上還可設有gpu,用以對所述播放器3進行圖形處理,可采用觸摸屏,所述觸摸屏也為電容式觸摸屏,所述的電容式觸摸屏包括一基材,所述基材的正面為觸控操作面,所述基材的背面依次貼覆有一成像層和一用于感應觸控信號的導線層;所述成像層為正投影成像層或者背投影成像層;所述導線層為由超細導線分別沿x軸和y軸方向繞制的、盤錯交織的經緯線網,所述超細導線在交叉點處相互絕緣,每個網格所圍設的空間構成一個感應單元,所述導線層的輸出端與一感應信號采集控制集成電路連接。所述導線層上的感應單元彼此交錯布置,或成蜂窩狀、或成矩形狀、或成不規則菱形狀,所述感應單元之間的間隔大小相同或不同。所述導線層的輸出端通過超細導線以壓接或插接或焊接方式與所述感應信號采集控制集成電路上設置的、與所述超細導線輸出匹配的引腳相接。
所述儲存裝置1可為快閃記憶體、隨機存取記憶體、硬碟機、光碟片、或任意形式的大數據儲存媒體。所述處理裝置2耦接至儲存裝置1,并且自儲存裝置1取得多媒體數據物件。上述中所述處理裝置2可為中央處理單元、微處理裝置、或其它類似的裝置,用以執行內嵌或儲存于儲存裝置1的電腦可讀取的程序碼,以處理顯示該多媒體數據物件的程序,可與安卓等系統兼容。
除了顯示多媒體數據物件,處理裝置2更為觀賞由顯示裝置顯示的多媒體數據物件的觀賞者(即,顯示裝置的使用者)提供避免眼睛疲勞的功能,以避免觀賞者因用眼過度而產生眼睛疲勞的情況。在一些眼睛疲勞的情況之下,可能進一步造成近視。值得注意的是,根據本發明所揭示的智能顯示裝置,所述顯示裝置可實施為一積體電路以及/或一播放器,所述播放器3,其耦接至一或多個播放裝置3-1~3-n,用以播放由播放器所顯示的多媒體物件數據。播放器3可以是任一可顯示多媒體數據物件的裝置,例vcd/dvd播放器3,而顯示裝置可以是電視機、屏幕、手機、投影機,或其它。根據本發明所揭示的智能顯示裝置,顯示裝置也可為可顯示并播放多媒體數據物件的播放裝置,例如電視機,其可透過電纜線以有線的方式、或透過無線電接口(interface)以無線的方式、或透過互聯網接收多媒體數據物件(例如,電視節目)。
當接收到要被播放的多媒體數據物件時,處理裝置2可決定多媒體數據物件的一物件類別,并根據一播放模式顯示該多媒體數據物件,其中播放模式是根據物件類別被選擇或決定。當多媒體數據物件為一影片或一電視節目時,多媒體數據物件的物件類別可以是影片或電視節目的型態、制作影片或電視節目的方法、影片或電視節目的類型、或其它。更具體的說,處理裝置2可決定多媒體數據物件是否為電影或電視節目、多媒體數據物件是否為使用2d或3d技術制作的物件、3d的多媒體數據物件是使用哪種3d影片制作方法(例如,紅藍色片(anaglyph)、偏光(polarization)、遮影(eclipse)、或其它方法)制作出來的、多媒體數據物件是否為新聞節目、談話節目、影集、或其它、多媒體數據物件是否為恐怖片、愛情片、文藝片、動作片、或其它。物件類別可被儲存于多媒體數據物件的標頭檔中的特定欄位,或者被儲存于多媒體數據物件的目錄中。例如,當多媒體數據物件被儲存于藍光碟片中時,標頭檔的格式欄位可提供這些信息(例如,關于被儲存的影片檔是2d或3d的影片)。又例如,當多媒體數據物件為被廣播的數位電視的電視節目時,物件類別可由廣播的電子節目表(electronicprogramguide,簡稱epg)中取得。
處理裝置2還可與移動ai芯片連接,通過使用神經處理引擎,來獲得更快的運行速度,其運行速度比普通狀態下的cpu處理器的運行速度快四倍之多,同時,還可對儲存裝置1及播放器3進行系統優化,使其運行速度得到極大,當然了,本發明中所述處理裝置2不僅限于與所述移動ai移動芯片連接,還可與其他芯片連接,通過芯片來提高其反應速度以及系統優化均處于本發明所保護的范圍內。
在決定多媒體數據物件的物件類別后,處理裝置2可包含cpu處理系統,可在開始顯示多媒體數據物件后,根據物件類別決定是否觀賞該多媒體數據物件的一觀賞者已發生或即將發生眼睛疲勞的情況,用以為觀賞者提供可避免眼睛疲勞的功能。在取得一多媒體數據物件并決定該多媒體數據物件的一物件類別(后,處理裝置根據一播放模式顯示該多媒體數據物件。所述處理裝置2可根據物件類別決定或選擇播放模式。在顯示多媒體數據物件的期間,處理裝置更取得觀賞多媒體數據物件的一觀賞者的眼睛疲勞相關信息,并根據物件類別以及/或取得的信息決定觀賞者是否已發生或即將發生眼睛疲勞。當處理裝置決定觀賞者已發生或即將發生眼睛疲勞時,處理裝置可根據物件類別調整用以顯示多媒體數據物件的播放模式。
所述儲存裝置1內可事先儲存多個觀賞者的眼睛疲勞相關信息。這些信息可透過不同的方式取得。例如,處理裝置可提供一接口(例如,于一首頁目錄或是一特定的目錄中的使用者接口(userinterface,簡稱ui)),用以與使用者互動,以收集時間相關信息,例如當使用者開始觀賞影片多久后,經過多久時間使用者會感覺疲倦或眼睛開始感覺疲勞,或者使用者所設定的預防眼睛疲勞時間(即,當預防眼睛疲勞時間到時,使用者希望被提醒要閉眼休息)。處理裝置可更進一步分析這些收集到的時間信息,以取得各使用者的使用習慣,并將取得的使用者使用習慣儲存起來作為各使用者的眼睛疲勞相關信息。
以下將介紹一些處理裝置2取得使用者的眼睛疲勞相關信息的案例。值得注意的是以下并非用以限定本發明的范圍。如所述處理裝置2首先辨識使用者的身份。辨識身份的方法可以是透過指紋辨識(例如,使用者可透過遙控器控制顯示裝置的操作)、或者透過顯示裝置所提供的使用者接口接收使用者所輸入的身份信息。無論是透過輸入指紋或透過使用者接口,待使用者輸入身份信息后,處理裝置2可接收到夾帶著使用者身份相關信息的對應信號。
當使用著的身份被辨識出來后,處理裝置2可提供另一接口與使用者互動,藉此使用者可輸入其使用習慣,或所謂的時間信息。例如,當使用者開始觀賞影片多久后,經過多久時間使用者會感覺疲倦或眼睛開始感覺疲勞,或者上述的預防眼睛疲勞時間。處理裝置2可接收到夾帶使用者所輸入的時間信息的一回應信息。所述處理裝置2也可通過遙控器上的特定按鍵取得時間信息,其中此按鍵,上述中所述遙控器的按鍵,可為特別設計用來收集時間信息的按鍵。例如,當使者在觀看影片或電時節目時,一旦使用者感到疲倦或眼睛開始感覺疲勞時,可按下此特定的按鍵(即,讓特定的按鍵由一狀態改變為另一狀態),用以通知處理裝置2。通知的信息可在特定的按鍵被按下后,被傳送至處理裝置2。接收到通知信息后,處理裝置2可調整顯示模式,并進一步因應該通知信息計算使用者開始感覺疲倦或該觀賞者的眼睛開始感覺疲勞的時間。例如,處理裝置2可得知使用者已經觀看影片或電時節目多久了,并藉此取得時間信息。無論是使用者自己輸入或者透過上述特定的按鍵輸入,處理裝置2都可以得到包含使用者眼睛疲勞相關信息的相關回應信息或通知信息。處理裝置2可接著將取得的信息儲存于儲存裝置1,作為處理多媒體數據物件的參考信息。
值得注意的是,使用者的眼睛疲勞相關信息可分別對應于不同的使用者被儲存,甚至可分別對應于不同的物件類別被儲存。更具體的說,處理裝置2可分別針對不同使用者儲存對應的眼睛疲勞相關信息。此外,對于各使用者,眼睛疲勞相關信息(以下簡稱為疲勞信息)可更進一步根據不同的物件類別被分類。例如,處理裝置2可分別儲存使用者觀賞2d影片、3d影片、新聞、影集、或其它多媒體數據物件的疲勞信息。又例如,處理裝置2可更分別儲存使用者觀賞不同類型的電影的疲勞信息,例如恐怖電影、愛情電影、文藝電影、動作電影、或其它。疲勞信息可以表格的形式被儲存于儲存裝置1內,并且當需要時,處理裝置2可通過查表取得一特定使用者以及/或一特定的物件類別的疲勞信息。
所述處理裝置2也為使用者將一或多個特定的物件類別相關的疲勞信息儲存于儲存裝置1內,并且根據一既定法則推導出未被儲存于儲存裝置1內的其它物件類別相關的疲勞信息。例如,處理裝置2可儲存使用者觀賞2d影片時的相關疲勞信息(例如,觀賞2d影片時,使用者多久開始覺得疲倦或眼睛疲勞,或者上述的預防疲勞時間),并根據2d影片相關的疲勞信息推導出該使用者觀賞3d影片時的疲勞信息。更具體的來說,假設觀賞2d影片的疲勞信息為2小時,處理裝置2可,例如將2乘上一個既定的數值(例如,0.75),推導出觀賞3d影片的疲勞信息為1.5小時。因此,當處理裝置2顯示3d多媒體數據物件達1.5小時后,處理裝置2可調整顯示模式(以下段落將作詳細的介紹)。如此一來,由于使用者可以不需手動為各種物件類別分別輸入疲勞信息,使用便利性可大幅提升,此外用以儲存疲勞信息的記憶體空間也可被優化。
進一步,本發明中優選所述播放器3至少包括用于播放公益廣告或公益宣傳的第一顯示裝置31和用于播放閱讀、科普或廣告的第二顯示裝置32,采用兩個顯示裝置用以滿足各式人群的需求,同時又可以宣傳正能量,當然,也可以為上述中所涉及的多個顯示裝置。上述中公益廣告和公益宣傳可用于政治環境下的宣傳,是黨的宣傳工作新渠道,是繼報紙、電視、廣播、網絡外又開辟的一條宣傳工作的主戰場,可深入宣傳貫徹黨和國家領導人的重要精神,以社會主義核心價值觀為引路,為正確輿論引導“鋪路搭橋、深入生活、深入群眾”,為實現“兩個一百年”奮斗目標,為實現中華民族偉大復興中國夢提供強大的價值引導力、文化凝聚力和精神推動力,本發明中所用的播放器3主應用在戶內落地式或懸掛式,當然,所述播放器3不局限于上述中所述第一顯示裝置31和第二顯示裝置32。
所述智能音箱4包括用以對用戶的語音信息進行解析的語音識別裝置5,所述語音識別裝置5至少包括一種能夠按照事先設定或存儲的指令,自動進行數值計算和/或信息處理的電子設備,其硬件包括但不限于微處理裝置、專用集成電路(applicationspecificintegratedcircuit,asic)、可編程門陣列(fieldprogrammablegatearray,fpga)、數字處理裝置(digitalsignalprocessor,dsp)、嵌入式設備等。所述語音識別裝置5還可包括用戶設備。所述用戶設備包括但不限于任何一種可與用戶通過鍵盤、鼠標、遙控器、觸摸板或聲控設備等方式進行人機交互的電子產品,例如,個人計算機、平板電腦、智能手機、個人數字助理(personaldigitalassistant,pda)、游戲機、交互式網絡電視(internetprotocoltelevision,iptv)、智能式穿戴設備等。其中,所述用戶設備所處的網絡包括但不限于互聯網、廣域網、城域網、局域網、虛擬專用網絡(virtualprivatenetwork,vpn)等,所述用戶設備所處的網絡也可以為其他網絡設置。
需要說明的是,所述用戶設備僅為舉例,其他現有的或今后可能出現的用戶設備如可適應于本發明,也應包含在本發明的保護范圍以內,并以引用方式包含于此。
當所述語音識別裝置5至少包括用于獲取用戶語音信息的語音獲取裝置51,用于當用戶輸入語音信息時,獲取該用戶輸入的語音信息,利用基于預設模型的大詞匯量語音識別方法(例如,基于隱馬爾可夫模型的大詞匯量語音識別方法)對所輸入的語音信息進行識別得到第一語音識別結果,利用基于輔助語音數據包的語音識別方法(例如,根據該用戶當前的地理位置信息調用與該地理位置信息相對應的輔助語音數據包進行識別得到第二語音識別結果。所述語音獲取裝置51通過比較第一語音識別結果和第二語音識別結果得到一個最優識別結果,不僅提高了語音識別率,還提高了用戶的體驗。
所述語音識別裝置5還可以與tpu連接,用以基于深度學習語音識別模型的語音搜索服務,其具有更強大、更高效的處理芯片。
所述語音獲取裝置51與內置有存儲器、運算器及處理器的神經計算棒52連接,所述神經計算棒52內置了存儲器、運算器、處理器等高級芯片,其實就是一個微型電腦,可實現對所述語音獲取裝置51所獲取的數據的解析,所述神經計算棒52的存儲器用于存儲安裝于所述語音識別裝置5中的軟件程序及數據。該存儲器可以是所述語音識別裝置5的內部存儲器,例如所述語音識別裝置5的硬盤或者內存。該存儲器也可以是所述語音識別裝置5的外部存儲設備,例如所述語音識別裝置5上的插接式硬盤、智能媒體卡(smartmediacard,smc)、安全數字卡(securedigitalcard,sd)、快閃存儲器卡(flashcard)等儲存單元。進一步地,所述存儲器還可以既包括所述語音識別裝置5的內部存儲器,也可以包括外部存儲設備。
本發明中,所述存儲器中不僅可以存儲社會主義核心價值觀的觀念,還可存儲如中華傳統美德,例如:百德孝為先等美德,也可以存儲旅游景點的畫面、語言及文本,例如:桂林山水甲天下的語言、烏江的畫面及陽朔山水甲桂林等畫面等,同時,也可以存儲醫療知識,例如當用戶身體感到不適時,可根據自身癥狀對提出疑問,所述存儲器內存儲有相應的答案;所述存儲器還可以教育知識,甚至還可以存儲科普知識。
在本發明中,所述存儲器中預先存儲有多個輔助語音數據包及與該多個輔助語音數據包相對應的語音信息。所述輔助語音數據包可以是基于地理位置的語音數據包,對應地,所述存儲器中存儲的是具有該地理位置語音特征的語音信息。
在本發明中,所述的地理位置是以地市為單位進行劃分的。在其他實施例中,對于方言復雜的地理位置,還可細分到地市以下的區域,例如,以縣級市為單位進行劃分或者以設定的區域為單位進行劃分。
由于在同一地理位置,所講的普通話也會存在口音和方言的區別。或者即使不在同一地理位置,方言或者口音也有可能相同,因此,所述存儲器中存儲的基于地理位置的語音數據包在其他的一些實施例中進一步包括基于方言和地理位置的語音數據包及基于口音和地理位置的語音數據包。
例如,基于方言和地理位置的語音數據包可以包括:粵語_香港、粵語_廣州、閩南語_泉州、閩南語_廈門。基于口音和地理位置的語音數據包可以包括:口音_福建、口音_廣州。需要說明的是,基于口音和地理位置的語音數據包包括,但不限于,聲母、韻母的吐字方式以及前舌音和后舌音的吐字方式。
本發明中,所述存儲器中還存儲有旅游信息、醫療信息、教育信息、價值觀等信息,所述處理器根據所述語音獲取裝置51所獲取的語音,提取特征,對特征進行解析,所述神經計算棒52根據其儲存器中所存在的知識對所述語音獲取裝置51所獲取的語音所獲取的語音進行答復。
在本發明中,所述神經計算棒52的處理器是一個或者多個中央處理裝置(centralprocessingunit,cpu)、微處理裝置或其他數字處理芯片等。該處理器用于執行軟件程序代碼或運算數據,例如執行所述的語音識別裝置5。本實施例中,所述處理器接收用戶輸入的語音信息,同時獲取該用戶當前的地理位置信息,在進行語音識別時,結合基于預設模型的大詞匯量語音識別(例如,基于隱馬爾可夫模型的大詞匯量語音識別方法,或者基于人工神經網絡模型的語音識別方法)和基于輔助語音數據包的語音識別(例如,基于地理位置的輔助語音數據包的語音識別)分別輸出第一識別結果和第二識別結果,根據用戶比較第一識別結果和第二識別結果做出的選擇,動態調整基于預設模型的大詞匯量語音識別和基于輔助語音數據包的語音識別的權重,以提高語音識別的準確率。
所述處理器與所述語音識別裝置5、存儲單元、語音輸入單元通訊連接。通訊可以通過串行外圍設備接口總線(universalserialbus,usb)或其他通信路徑或協議來實現。
所述語音識別裝置5內還包括麥克風53,所述麥克風53與所述神經計算棒52連接,所述顯示單元包括,但不限于,麥克風。
所述神經計算棒52用以對所述語音獲取裝置51所接收的語音信息進行解析,解析完成后在其內置的存儲器中進行搜索相應答案,并將相應答案轉換成文本信息或/和視頻或圖片信息發送至所述處理裝置2,所述處理裝置2接收到所述神經計算棒52傳送的相應答案在所述播放器3中以文本或/和視頻或圖片信息顯示出來。
所述語音識別裝置5至少包括語音獲取裝置51及神經計算棒52。本發明所稱的模塊是指一種能夠被處理單元所執行并且能夠完成固定功能的一系列計算機程序段,其存儲在存儲單元中。在本發明中,關于各模塊的功能將在后續詳述。
所述語音獲取裝置51,用于獲取用戶輸入的語音信息。
在本發明中,用戶可以直接通過所述語音識別裝置5輸入語音,所述獲取模塊51根據用戶輸入語音的內容獲取語音信息。
所述第一語音識別模塊,用于識別所述語音信息得到第一識別結果。
所述第二語音識別模塊,用于識別所述語音信息得到第二識別結果。
在本實施例中,所述第一語音識別模塊可以是基于預設模型的大詞匯量語音識別模塊,所述第二語音識別模塊可以是基于輔助語音數據包的語音識別模塊。即利用基于輔助語音數據包的語音識別模塊協助基于預設模型的大詞匯量語音識別模塊進行語音識別。所述基于輔助語音數據包的語音識別模塊可以是基于地理位置建立的輔助語音數據包的語音識別模塊。在一些實施例中,所述語音識別裝置5可以先執行所述第一語音識別模塊識別所述語音信息,再執行所述第二語音識別模塊識別所述第二語音信息。
在一些實施例中,為了提高識別效率,所述語音識別裝置5可以并行執行所述第一語音識別模塊與所述第二語音識別模塊分別識別所述語音信息。利用基于預設模型的大詞匯量語音識別模塊識別所述語音信息時,同時利用所述基于輔助語音數據包的語音識別模塊識別所述語音信息,即所述語音識別裝置5以第一線程運行所述第一語音識別模塊以識別所述語音信息,并行地一第二線程運行所述第二語音識別模塊以識別所述語音信息。
在本實施例中,基于預設模型的大詞匯量語音識別模塊是指按照標準普通話建立的語音識別庫,任何用戶均可以調用所述語音識別庫,按照標準普通話進行識別。基于預設模型的大詞匯量語音識別不考慮方言和地理位置及/或口音和地理位置的影響。所述基于預設模型的大詞匯量語音識別模塊與現有技術中的相同。
所述基于輔助語音數據包的語音識別模塊(為便于描述,下文簡稱為“輔助語音識別模塊”)考慮方言和地理位置及/或口音和地理位置的影響,需要事先通過訓練和學習建立基于地理位置的語音數據包。
所述顯示模塊,用于根據預先設置的規則顯示所述第一語音識別結果和第二語音識別結果。
本實施例中,所述預先設置的規則由所述設置模塊預先設置。所述設置模塊可以為所述第一語音識別結果預先分配第一權重,為所述第二語音識別結果預先分配第二權重,根據權重值的大小確定對應該權重值的語音識別結果的顯示方式。所述第一權重值和所述第二權重值的總和可以為一固定數,例如,為整數1。優選地,所述設置模塊預先設置的第一權重值大于第二權重值,也就是說所述設置模塊為第一語音識別方法分配的權重值大于為第二語音識別方法分配的權重值。
在其他實施例中,所述設置模塊預先設置的規則還可以是,為所述第一語音識別結果預先設置第一識別分數,為所述第二語音識別結果預先設置第二識別分數,根據識別分數的大小確定對應該識別分數的語音識別結果的顯示方式。優選地,所述設置模塊預先設置的第一識別分數值大于第二識別分數值。
所述語音識別結果的顯示方式包括,但不限于:顯示的時間及/或顯示的位置。但不限于顯示的時間和顯示的位置。
例如,所述設置模塊預先設置的規則是為語音識別結果分配權重,則當預先設置的第一權重值大于預先設置的第二權重值時,所述顯示模塊可以在所述顯示單元上將對應權重值大的第一語音識別結果顯示在第一位置,如所述顯示單元提供的用戶界面的上半部分;當預先設置的第一權重值小于預先設置的第二權重值時,所述顯示模塊將對應權重值小的第一語音識別結果顯示在第二位置,如所述顯示單元提供的用戶界面的下半部分。
此外,當預先設置的第一權重值大于預先設置的第二權重值時,所述顯示模塊在所述顯示單元上顯示第一語音識別結果,在預設時間之后(例如,2秒后)在所述電子設備1的顯示單元上顯示第二語音識別結果。
在本實施例中,所述的語音識別裝置5進一步包括更新模塊,用于結合獲取的用戶反饋信息更新所述預先設置的規則。
本實施例中,所述用戶反饋信息可以根據用戶的操作得到。例如,用戶選取了第一語音識別結果,則所述獲取模塊51獲取到的用戶反饋信息表示最佳語音識別結果是利用第一語音識別方法得到的。若用戶選取了第二語音識別結果,則所述獲取模塊51獲取到的用戶反饋信息表示最佳語音識別結果是利用第二語音識別方法得到的。
所述更新模塊更新所述預先設置的規則可以是調整預先設置的權重值或者調整預先設置的識別分數值。
具體地,所述更新模塊根據用戶選取的語音識別結果,將對應該語音識別結果的權重值或者識別分數值變大,及/或將用戶沒有選取的語音識別結果對應的權重值或者識別分數值減小。例如,當獲取的用戶反饋信息是選取了第一語音識別結果,則所述更新模塊將對應該第一語音識別結果的第一權重值或者第一識別分數值變大,及/或將對應第二語音識別結果的第二權重值或者第二識別分數值減小。當獲取的用戶反饋信息是選取了第二語音識別結果,則所述更新模塊將對應該第二語音識別結果的第二權重值或者第二識別分數值變大,及/或將對應第一語音識別結果的第一權重值或者第一識別分數值減小。
其中,上述的權重值或者分數值的變大或減小可根據預先設置的比例或者數值進行。
所述第二語音識別模塊包括調用子模塊、下載子模塊確定子模塊。本發明所稱的模塊是指一種能夠被處理單元所執行并且能夠完成固定功能的一系列計算機程序段,其存儲在存儲單元中。在本實施例中,關于各模塊的功能將在后續的實施例中詳述。
所述獲取模塊51,還用于接收到用戶的語音信息時,獲取該用戶當前的地理位置信息。
在本實施例中,所述獲取模塊51通過所述語音識別裝置5內置的定位模塊及/或網絡連接模塊獲取所述電子設備1當前所在的地理位置信息。所述定位模塊包括,但不限于:全球定位系統(globalpositioningsystem,gps)。所述所述網絡連接模塊包括,但不限于:第3代移動通信技術(the3rdgenerationtelecommunication,3g)、通用分組無線業務(generalpacketradioservice,gprs)以及無線保真技術(wirelessfidelity,wi-fi)。所述電子設備1當前所在的地理位置信息即被認為是該用戶當前所在的地理位置信息。
在一些實施例中,所述獲取模塊51還可以通過接收用戶設置的指令,并根據該用戶設置的指令確定該用戶當前的地理位置信息。
例如,所述語音識別裝置5中設置有位置選擇列表,該位置選擇列表包括中國所有城市的名稱。用戶通過觸發該位置選擇列表,選擇與用戶輸入語音信息相應的地理位置信息。
又如,所述語音識別裝置5中設置有文本輸入框,用戶通過激活該文本輸入框功能,在相應的界面中輸入當前地理位置信息。
所述調用子模,用于根據所述地理位置信息調用對應的輔助語音數據包。
在本實施例中,所述調用子模塊根據所述地理位置信息從所述存儲單元中調用對應的輔助語音數據包。
所述存儲單元中預先存儲有輔助語音數據包及該輔助語音數據包包括的具有地理位置語音特征的語音信息。
例如,所述地理位置信息是廣東,則所述調用子模塊調用識別廣東語音特征的輔助語音數據包。
在一些實施例中,如果所述語音識別裝置5的存儲單元中沒有預先存儲有對應所述地理位置信息的輔助語音數據包時,則所述獲取模塊51在獲取用戶當前的地理位置信息時,執行所述下載子模塊。所述下載子模塊從與所述語音識別裝置5通訊連接的服務器下載該輔助語音數據包。所述通訊連接可以是無線通訊連接。所述輔助語音數據包由用戶事先進行訓練和學習得到并布署于所述服務器,下載子模塊可以通過網絡請求所述服務器發送對應所述地理位置信息的輔助語音數據包。
所述第二語音識別模塊,用于根據所述輔助語音數據包識別所述語音信息得到第二語音識別結果。
在本實施例中,第二語音識別模塊利用所述第二語音識別方法識別所述語音信息得到所述第二語音識別結果。
進一步地,為了解決即使在同一地理位置也會存在方言或者口音的差別而造成的語音識別率不高的問題,所述第二語音識別模塊還可以包括確定子模塊:用于根據所述語音信息確定該用戶的語音類型。所述調用子模塊基于所述語音類型和所述地理位置信息共同確定對應的輔助語音數據包。
該用戶的語音類型由用戶語言的發音和音調決定,可以包括方言和口音。
例如,用戶的當前的地理位置為廣州,用戶的語音類型是口音(例如,粵語),則所述調用子模塊調用“口音_廣州”的輔助語音數據包識別所述語音信息。
在一些實施例中,所述獲取模塊51還可以通過獲取所述顯示單元提供的包括有文本輸入框的界面上輸入的信息獲取用戶的語音類型或其他方式也可使用。
更進一步地,為了避免用戶臨時去某地出差或者旅游時,所述獲取模塊51獲取該用戶當前的地理位置信息,所述調用子模塊根據該當前的地理位置信息調用相應的輔助語音數據包造成識別率低時,所述獲取模塊51還用于獲取用戶當前的地理位置信息以及歷史地理位置信息,所述調用子模塊根據歷史地理位置信息和當前地理位置信息確定調用的輔助語音數據包。
在本實施例中,所述歷史地理位置信息是指用戶的經常居住地的地理位置信息。
例如,用戶當前的地理位置為廣州,而用戶的經常居住地在福建,則所述調用子模塊調用識別福建語音特征的輔助語音數據包來識別所述語音信息。
綜上所述,本發明實施例公開的一種語音識別系統,預先通過訓練和學習得到多個輔助語音數據包,該輔助語音數據包是以地理位置為單位進行劃分的語音數據庫。同時基于用戶的語音類型,輔助語音數據包進一步細分為基于方言和地理位置的輔助語音數據包,以及基于口音和地理位置的輔助語音數據包。利用基于預設模型的大詞匯量語音識別模塊識別用戶的語音信息時,同時也利用用該輔助語音數據包識別用戶的語音信息從而協助所述基于預設模型的大詞匯量語音識別方法,不僅提高了用戶的語音識別率,也提高了用戶體驗。
目前的人臉識別技術主要集中在二維圖像方面,但由于受到光照、姿勢、表情變化的影響,識別的準確度受到很大限制。針對人臉識別的難點,本發明揭示了一種利用三維信息進行人臉的識別。
進一步的,所述智能音箱4包括用于對用戶的人臉進行識別的人臉識別裝置6,所述人臉識別裝置6至少包括依次連接的用于監測區域空間內來自人體的紅外線的紅外傳感器61,用以對所述紅外傳感器61所檢測的人體從不同角度同時進行拍攝視角圖像的攝像頭組62以及用以對所述攝像頭組62拍攝的圖像進行人臉圖像捕捉的人臉捕捉裝置63,所述人臉捕捉裝置63與用于初步估計所述人臉捕捉裝置63所捕捉的人臉的偏航角,并檢測到偏航角最小的人臉視角圖像的正臉估計裝置64;所述人臉識別裝置6還包括從一個姿態正的人臉三維模型獲得所述正臉估計裝置64的預定人臉特征點的三維坐標以及從所述正臉估計裝置64中檢測所述預定人臉特征點的二維坐標,根據獲得的所述預定人臉特征點的二維坐標和三維坐標計算相對于拍攝所述具有偏航角最小的人臉的視角圖像的圖像捕捉設備的第一頭部姿態的姿態估計裝置65,所述姿態估計裝置65與所述正臉估計裝置64連接。
下面本發明簡單闡述一下人臉識別裝置如何消除姿態對人臉識別的影響,上述中選擇采用所述紅外傳感器61主要是利用任何溫度高于絕對零度的物體,都會向外部空間以紅外線的方式輻射能量,而人體的溫度通常在37°~39°,可以被所述紅外傳感器61所感知,當所述紅外傳感器61感知到人體后,所述攝像頭組62獲取從不同角度同時拍攝的對象(即,用戶)的圖像(以下稱為視角圖像),例如,攝像頭組62可以從以適當位置和姿態布置在檢測環境中的多個圖像捕捉設備來獲取視角圖像,所述攝像頭組62與用以對所述攝像頭組62拍攝的圖像進行人臉圖像捕捉的人臉捕捉裝置63連接,所述人臉捕捉裝置63將所述攝像頭組62所拍攝的視覺圖像中人臉全部捕捉,并將其傳至所述正臉估計裝置64。
所述正臉估計裝置64從接收的視角圖像中檢測具有偏航角最小(即,最接近零)的人臉的視角圖像(即,人臉最正的視角圖像)。本領域的技術人員可以理解,這里的偏航角最小是通常意義上的,即,相對于該視角圖像這個平面來說的(例如,人們拿到一張照片時會評價照片中人的頭是否擺得正,即,偏航角是否為零)。換句話說,從不同角度拍攝的視角圖像中檢測的具有偏航角最小的人臉的視角圖像實際上是由目標對象的臉最正對的圖像捕捉設備所拍攝的視角圖像。通過上述檢測,可以找到此時目標對象的臉最正對的所述攝像頭組62中的一個。
正臉估計裝置64將該視角圖像中的人臉圖像發送到姿態估計裝置65,以作為用于更精確地估計頭部姿態的人臉圖像。姿態估計裝置65在從正臉估計裝置64接收的人臉圖像中檢測預定的人臉特征點(例如,眼角、鼻尖、鼻翼、嘴角、臉部輪廓點等)以得到預定的特征點的二維坐標,并從一個人臉三維模型獲取所述預定的人臉特征點的三維坐標,然后根據上述檢測的人臉特征點的二維坐標和三維坐計算對象的相對于拍攝所述具有偏航角最小的人臉的視角圖像的圖像捕捉設備的頭部姿態(即,偏航角、俯仰角和滾轉角)。具體地說,頭部姿態估計模塊13可包括:特征點檢測模塊、三維坐標獲取模塊、姿態估計模塊和坐標轉換模塊。
所述特征點檢測模塊用于從具有偏航角最小的人臉的視角圖像中檢測預定的人臉特征點,并獲得其二維坐標,檢測的預定的人臉特征點的二維坐標可被表示為:
這里,n表示檢測的人臉特征點的數量。
可通過使用主動形狀模型(asm)來檢測對象人臉圖像中檢測預定的人臉特征點以獲得其二維坐標。由于利用asm來檢測人臉特征點是公知的,將不再進行詳細描述。此外,這里也可以利用其他的人臉特征點檢測方法,本發明不限于僅使用asm。
由于正面人臉的特征點最為豐富、易于定位、并且對人臉姿態比較敏感,所以選擇偏航角最小的人臉的視角圖像能夠更精確的進行頭部姿態的估計。
所述三維坐標獲取模塊從一人臉三維模型獲得所述預定的人臉特征點的三維坐標a,其可以被表示為:
在本發明中,由于三維坐標a和二維坐標b從不同的對象獲得,為了計算兩者的旋轉關系,三維坐標a和二維坐標b是被歸一化的。在本發明的一個實施例中,所述歸一化是僅對三維坐標a和二維坐標b各自的坐標系的坐標原點的歸一化。即,將坐標原點設置在所述預定的人臉特征點在各個坐標軸上的坐標的算數平均值處。此時,對于三維坐標a,
本發明不限于上述歸一化,還可進一步對三維坐標a和二維坐標b的尺度進行歸一化。但是,在本發明中,也可不對尺度進行歸一化。
這里的人臉三維模型優選地為標準的人臉三維模型。此時,三維坐標a可以被預先存儲。
所述姿態估計模塊利用從特征點檢測模塊接收的預定的人臉特征點的二維坐標b和從三維坐標獲取模塊接收的三維坐標a來得到對象相對于人臉三維模型的頭部姿態(即,偏航角、俯仰角和滾轉角)。具體地說,a、b以及頭部姿態信息x之間的關系可表示為:
a=bx,則:
其中,
這里,p為俯仰角,q為偏航角,v為滾轉角。
此時獲得的頭部姿態是基于正臉估計裝置64檢測的具有偏航角最小的人臉的視角圖像獲得的,是相對于攝該具有偏航角最小的人臉的視角圖像的圖像捕捉設備的頭部姿態。因此,為了獲得以世界坐標系表示的頭部姿態,根據拍攝該具有偏航角最小的人臉的視角圖像的圖像捕捉設備的世界坐標系坐標,將通過姿態估計模塊獲得的以基于所述圖像捕捉設備的本地坐標系表示的頭部姿態轉換為以世界坐標系表示的頭部姿態。由于進行坐標系轉換是公知的技術,將不再進行詳細描述。例如,可通過攝像機標定(cameracalibration)技術來進行上述坐標系轉換。
此外,在獲得三維坐標a時,優選使用人臉三維模型姿態正時(即,俯仰角、偏航角和滾轉角都為零)獲得的三維坐標a。本領域的技術人員可以理解,與前面提到的視角圖像類似,這里的人臉三維模型姿態正也是一般意義上的,即根據現有技術通過三維坐標a計算的人臉三維模型的俯仰角、偏航角和滾轉角為零。也即,三維坐標a和二維坐標b都是使用視角圖像和人臉三維模型各自的絕對坐標系。此時,獲取所述三維坐標時人臉三維模型相當于正對著捕捉具有偏航角最小的人臉的視角圖像的圖像捕捉設備。
此外,三維坐標a可以不必是人臉三維模型姿態正時獲得的三維坐標。由于利用式計算的頭部姿態是相對于人臉三維模型的姿態,因此很容易理解,當三維坐標a在人臉三維模型姿態不正的情況下被獲得時,可以利用人臉三維模型的姿態來補償利用式計算的頭部姿態,以得到與人臉三維模型姿態正時相同的結果。
本發明無需預先存儲用戶信息,實現了對人臉的精確捕捉,因此可以適應的范圍更廣,同時,可規避姿態對人臉識別技術的影響。
進一步,當所述姿態估計裝置65將正臉圖像發送至所述皮膚分析裝置66后,通常需要對該圖像進行預處理,這是因為待處理的人臉圖像經常存在光照不均勻的問題,而這會直接影響到人臉的特征提取精度,因此對輸入的圖像必須進行光照處理以改善圖像質量。一般地,灰度直方圖可用于表示數字圖像中每一個灰度級與其出現的頻率之間的統計關系。對于偏暗、偏亮、亮度范圍不足或對比度不足的圖像進行直方圖規定化,可以使得輸入圖像的直方圖分布變換成近似特定的直方圖。變換函數可以選用例如高斯、瑞利、對數、指數等形式的函數。在本實施例中采用對數變換形式:
式中,f(x,y)為輸入圖像,g(x,y)為輸出圖像,a、b、c是調整曲線的位置和形狀而引入的參數。通過這種變換可以使圖像低灰度范圍得以擴展,高灰度范圍能夠被壓縮,圖像的灰度分布趨于均勻。優選地,對灰度變換后的圖像再進行例如3×3的中值濾波,去除圖像中引入的噪聲信息,以改善圖像質量。
提取人臉特征之后,使用根據本發明實施例的方法以獲得所需的皮膚類型/問題所需輸出結果,包括:檢測皮膚色澤與色度、計算紋理對比度值、計算灰度平均值、并且將上述計算所得結果與該預設數據庫進行匹配,并輸出匹配所得的皮膚問題結果。
在本發明中,可以使用這樣一種算法以檢測皮膚色澤與色度,其中,以皮膚顏色矩陣的彩色/顏色強度分布表征來表征一彩色人臉圖像。大多數的顏色分布信息可以由三個二階矩陣來表示,其中,一線階矩陣(μc)表征的是平均顏色,二線階矩陣(δc)表征的是標準偏差,以及三階矩表征的是偏斜度(θc)顏色。利用以下的數學公式,從這三個低次矩陣(μc、δc、θc)提取各三種色平面(r、g、b):
其中,m、n為圖像的二維尺寸,i、j分別表示該像素點的所在行、列,c為顏色分量的值。其結果是,僅需要提取九個參數作為彩色人臉圖像的特征,例如包括色平面參數(rgb)、平均顏色、標準偏差、偏斜度顏色、色澤色度值、紋理對比度、灰度平均值等,通過對以上皮膚色澤與色度的計算,可以得出輸入人臉圖像的對象皮膚色澤與色度等一系列參數數組。
在本發明中,以皮膚紋理檢測算法計算紋理對比度值。紋理是人臉圖像的特征,而紋理本身的一大特點是其圖案的重復。在此,引入術語“紋理基元”,其意思即是指紋理的模式單元,紋理基元的大小、形狀、顏色和取向可在很大的區間內變化,而且任意兩個紋理之間的差異可以體現為紋理基元的變化程度。可構建一紋理共生矩陣,該紋理共生矩陣c(i,j)是由位移矢量dx、dy=(δx,δy)所定義的,其中δx、δy是分別在x方向和y方向上的位移,然后計算所有像素相隔位移dx、dy所具有的灰度級i和j。其也可能是由于圖像中的紋理基元的空間統計分布,并且包含關于底層中的圖像表面的結構布置等重要信息。然后,對矩陣c(i,j)中的每個元素進行歸一化。通過對以上計算,可計算得出皮膚紋理的一系列參數數組,紋理對比度數值的計算公式為:
由此可得到輸入人臉圖像中對象皮膚紋理的對度比大小,也就能夠表示對象皮膚紋理的深淺度。
在本實施例中,利用差和算法、以及該人臉圖像的灰度值快速匹配算法,得到以下計算公式:
其中,e(si,j)與e(t)分別是用戶皮膚子圖si,j與所述皮膚分析裝置66內置的數據庫中的皮膚圖像t(m,n)的灰度平均值。
然后,通過提取以上所得的數值,與所述皮膚分析裝置66內置的數據庫進行對比,從而判定出人體的年齡段,所述皮膚分析裝置66將判定后的數據發送至所述處理裝置2。
所述姿態估計裝置65將正臉圖像發送至圖像處理模塊67,所述圖像處理模塊67用于對人臉的正臉圖像進行灰度化、光照補償預處理,從而獲得灰度圖像,所述圖像處理模塊67與用于從所述圖像處理模塊67上提取出人臉部分特征值的特征提取模塊68連接,所述特征提取模塊68與用于將所述特征提取模塊68提取出的人臉部分特征值與人臉數據庫存儲區所存儲的各年齡段的人臉數據進行比對的人臉分析模塊69連接,所述人臉分析模塊69將對比后的數據發送至所述處理裝置2。所述特征提取模塊68包括至少包括眼部皺紋提取模塊,以確定其年齡。
第一語音識別模塊第二語音識別模塊第一語音識別模塊第二語音識別模塊第一語音識別模塊第二語音識別模塊第一語音識別模塊第二語音識別模塊第一語音識別模塊第二語音識別模塊第一語音識別模塊第二語音識別模塊第二語音識別模塊第二語音識別模塊第二語音識別模塊第二語音識別模塊
更進一步,所述智能音箱4與后端平臺連接,所述后端平臺與復數個客戶端無線連接,所述客戶端上設有app軟件。
本發明的有益效果主要體現在:結構簡單精巧,通過人臉識別裝置、語音識別裝置及人機交互裝置可以根據不同用戶、不同性別選擇性播放與其相適應的公益廣告、科普、閱讀及公益宣傳等,以滿足不同人的需求,同時,觀看各自喜歡的廣告、宣傳及政事要聞不僅不會造成視覺疲勞,而且會帶來超出預期的廣告效應。
應當理解,雖然本說明書按照實施方式加以描述,但并非每個實施方式僅包含一個獨立的技術方案,說明書的這種敘述方式僅僅是為清楚起見,本領域技術人員應當將說明書作為一個整體,各實施方式中的技術方案也可以經適當組合,形成本領域技術人員可以理解的其他實施方式。
上文所列出的一系列的詳細說明僅僅是針對本發明的可行性實施方式的具體說明,它們并非用以限制本發明的保護范圍,凡未脫離本發明技藝精神所作的等效實施方式或變更均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!