一種基于RGB-D視覺引導的家庭服務機器人智能抓取方法及系統與流程
本發明屬于機器人以及計算機視覺,特別涉及一種基于rgb-d視覺引導的家庭服務機器人智能抓取方法及系統。
背景技術:
1、基于視覺的服務機器人抓取系統,通過圖像采集、圖像處理等方法技術完成對待抓取目標的檢測識別與位姿估計,然后將視覺結果反饋給機器人完成對目標的抓取。近年來,隨著雙目、rgb-d、tof三維視覺相機的出現,以及深度學習、強化學習理論方法的進步,面向服務機器人智能抓取的視覺引導系統呈現出從二維圖像到三維點云,從傳統機器學習算法到深度神經網絡快速發展迭代的趨勢。當下,基于三維點云引導的機器人的智能抓取方法多以各種深度網絡模型為主,但距離實際應用還有很大的距離。2020年,來自伯明翰大學和國防科技大學的wei?chen等人提出一種目標位姿估計網絡g2l-net,其通過rgb-d圖像獲得場景點云,借助平移定位網絡進行語義分割和目標平移估計,進而利用旋轉定位網絡進行目標旋轉估計,拿到目標在三維空間中的位姿信息。2022年,劍橋大學和清華大學jianfeng?wang等人提出了一種改進的grcnn網絡模型,該網絡由特征提取層、序列模型和轉譯層構成,通過對輸入的rgb圖像和深度圖像進行分析處理,可直接輸出在理想平面之上的各目標的抓取點和抓取角度。
2、現有視覺引導機器人抓取技術應用于家庭服務場景依然存在諸多不足。首先,傳統的rgb圖像引導方法僅可獲取目標的色彩信息,無法獲取深度信息,這使得待抓取目標在三維空間中的位置和姿態難以感知與檢測。其次,基于三維點云的目標分割與位姿估計方法,雖然可以獲得待抓取目標的類型及其在三維空間中的位姿,但在混合堆疊場景下的局限性較大,且位姿估計網絡的訓練樣本制備困難,同時也需要將網絡輸出的目標空間位姿轉換為目標抓取位姿。再者,基于三維點云的抓取位姿估計方法,盡管可直接輸出待抓取目標的6d抓取位姿,但大多依賴于一個理想的背景平面,這就使得點云中無序稀疏的各類背景數據對位姿估計結果的準確性造成較大影響,即便此類方法可滿足環境目標較為單一的工業生產場景,但依然無法應對復雜的非結構化的家庭服務場景。
技術實現思路
1、為了克服上述現有技術的缺點,本發明的目的在于提供一種基于rgb-d視覺引導的家庭服務機器人智能抓取方法及系統,以滿足目前家庭服務場景中服務機器人智能取放任務需求,為智能家居領域提供有效、穩定的解決方案。
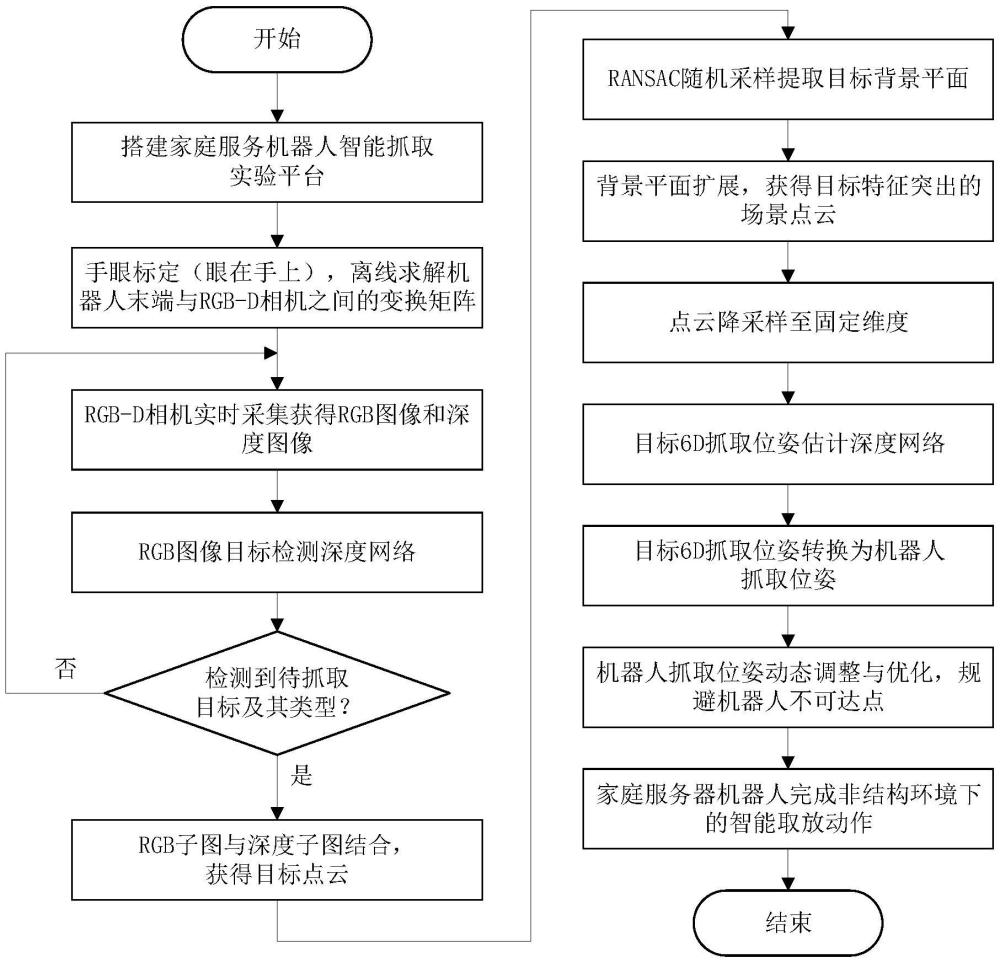
2、為了實現上述目的,本發明采用rgb-d視覺傳感器,結合rgb圖像和深度信息,實現對周圍環境和物體的感知和識別。首先,通過目標檢測網絡識別出rgb圖像中抓取目標的種類和錨定框信息,隨后,利用深度信息和目標網絡檢測結果融合生成目標物體的三維點云數據,將生成的點云數據送入到位姿估計網絡中,計算出目標物體的最佳抓取位姿,最終,通過位姿轉換將計算得到的抓取位姿轉換為機器人坐標系下,引導機器人進行抓取。本系統提供直觀的人機交互界面,用戶可以通過簡單的操作指令設定任務和監控抓取過程,進一步增強系統的操作便攜性和用戶體驗。
3、基于上述整體原理,本發明采用的技術方案可描述如下:
4、一種基于rgb-d視覺引導的家庭服務機器人智能抓取方法,包括:
5、步驟1,家庭服務機器人通過攜帶的rgb-d深度相機采集工作區域的原始圖像;
6、步驟2,對所述家庭服務機器人進行手眼標定,求解rgb-d深度相機相對于機器人末端的位置轉換關系,得到機器人末端與rgb-d深度相機之間的變換矩陣;
7、步驟3,采用特征融合的深度神經網絡算法,搭建目標檢測網絡及6d抓取位姿估計網絡;將采集到的rgb圖像送入所述目標檢測網絡,得到不同目標的類別及其錨定框信息,從rgb圖像中裁剪出目標子圖,并與相應的深度子圖融合生成目標點云;將所述目標點云輸入6d抓取位姿估計網絡,預測目標的抓取位置以及抓取姿態,為機器人的動作引導及抓取控制提供目標信息;
8、步驟4,根據所述位置轉換關系,將步驟3得到的目標6d抓取位姿轉換為機器人抓取位姿,引導控制安裝于所述機器人末端的夾爪完成目標抓取;
9、步驟5,對所述機器人目標抓取過程中的rgb圖像、深度圖像、點云圖像、抓取位姿以及控制信息進行數據可視化和人機交互。
10、在一個實施例中,所述步驟1,搭建家庭服務機器人智能抓取實驗平臺,模擬生活中儲物柜日常用品的機器人智能取放場景,以支持rgb-d視覺引導的機器人智能抓取,所述步驟2,在搭建的實驗平臺上,進行手眼標定。
11、在一個實施例中,所述實驗平臺,由rgb-d相機、機器人、夾爪、實驗操作臺、計算機主機、顯示器以及機器人視覺檢測軟件組成,rgb-d相機采用眼在手上的安裝方式,在工作時,相機朝向工作區域采集rgb圖像和深度圖像,以幀為單位發送給計算機主機進行處理,機器人視覺檢測軟件在計算機主機上運行,通過顯示器顯示界面,位置處于機器人后方,夾爪則安裝在機器人末端,機器人固定于實驗操作臺上方,工作范圍覆蓋整個實驗操作臺,在視覺引導下完成各類生活用品的智能取放。
12、在一個實施例中,所述步驟3,采用特征融合的深度神經網絡算法,搭建目標檢測網絡及6d抓取位姿估計網絡,方法如下:
13、步驟3.1,采集生活場景下各類物品的rgb圖像與深度圖像,構建訓練數據集;
14、步驟3.2,在yolov8網絡中引入注意力模塊,構建目標檢測網絡;
15、步驟3.3,結合通用物品抓取網絡graspnet以及抓取數據集graspnet-1billion,構建6d抓取位姿估計網絡。
16、在一個實施例中,所述目標檢測網絡中,對于rgb圖像,利用yolov8網絡的檢測結果,分割出包含目標的目標子圖;并從對齊的深度圖像中分割出相對應的深度子圖,將各目標子圖與相應深度子圖融合生成目標點云。
17、在一個實施例中,所述步驟3.1,對采集的圖像進行增強,并對深度圖像進行深度補全,所述深度補全的方法如下:
18、首先,將深度圖像中的每個像素值與缺失值進行比較,創建一個二值掩碼,與缺失值等值的像素在掩碼中被設置為1,其他像素被設置為0;然后,歸一化圖像全體像素值,確保像素值在-1到1范圍,并通過opencv的inpaint函數,采用navier-stokes算法對圖像中的缺失區域進行插補,最后,將圖像恢復到其原始大小,完成深度補全。
19、在一個實施例中,將所述目標點云進行點云分割與處理,然后再輸入6d抓取位姿估計網絡,實現方法如下:
20、以所述目標點云作為基礎場景點云,通過濾波、遠點篩選方法對點云進行預處理,再以ransac(random?sample?consensus)隨機采樣算法從基礎場景點云中提取出目標背景平面,并對背景平面進行擬合與擴展,得到目標特征突出的場景點云,隨后,對處理后的點云降采樣至固定尺寸,輸入6d抓取位姿估計網絡,預測目標的抓取位置以及6d抓取姿態,并根據置信度、抓取角度對預測位姿進行打分,篩選出得分最高的預測結果作為目標的最終抓取位姿。
21、在一個實施例中,其特征在于,所述6d抓取位姿估計網絡中,依次對目標點云執行如下過程:
22、首先,利用點編碼器-解碼器提取點云特征,并對具有c個維度特征的m個點進行采樣;
23、其次,將得到的具有c通道特征的新點通過接近網絡預測逼近向量,得到v個分類完成的預定義的視點以及可抓取的置信度;
24、然后,為每一個候選點通過分配一個二進制標簽進行分組和對齊,表示候選位置是否可以抓取,同時對于物體上的每一個點,需要在5mm半徑的相鄰區域找到亦可以抓取的真值點;
25、最后,將可抓取點的逼近向量分別通過操作網絡和公差網絡,得到目標抓取位姿、寬度和深度并進一步提高置信度。
26、在一個實施例中,所述步驟4,對于由6d抓取位姿估計網絡得到的置信度較高但受限于硬件設備條件而機器人無法到達的抓取位姿,通過抓取點預估和姿態動態調整算法,完成抓取位姿的優化,以實現機器人末端位姿穩定可達,從而提高了抓取成功率。
27、本發明還提供了一種實現所述基于rgb-d視覺引導的家庭服務機器人智能抓取方法的系統,包括圖像采集模塊、目標識別與位姿估計模塊、深度學習模型部署模塊、抓取位姿轉換模塊、通信控制模塊以及可視化模塊;
28、所述圖像采集模塊將rgb-d深度相機采集到的圖像信息,包括rgb圖像和深度圖像,實時向目標識別與位姿估計模塊傳遞;
29、所述目標識別與位姿估計模塊對接收到的圖像信息進行分析和處理,根據所述目標檢測網絡與6d抓取位姿估計網絡,得到目標的抓取位置以及抓取姿態;
30、所述深度學習模型部署模塊實現所述目標檢測網絡和6d抓取位姿估計網絡的實際加載與調用執行;
31、所述抓取位姿轉換模塊將目標6d抓取位姿轉換為機器人抓取位姿;
32、所述通信控制模塊用于各模塊與機器人和夾爪之間的通信控制,控制機器人和夾爪完成相應動作,實現目標的智能抓取;
33、所述可視化模塊用于視覺引導機器人抓取過程中各類數據的可視化顯示和人機交互。
34、與現有技術相比,本發明的有益效果是:
35、1、通過結合rgb圖像和深度信息,本系統可以有效的識別和定位三維空間中待抓取目標的類別和位姿,比傳統二維視覺系統更為準確和可靠;
36、2、通過三維點云位姿估計網絡,直接估計得到目標抓取位姿,而非目標空間位姿,降低了訓練樣本制備難度,同時也避免了后期從目標空間位姿向目標抓取位姿的變換,提升了結果的有效性;
37、3、通過融合rgb圖像目標檢測與三維點云位姿估計網絡,發揮二維圖像目標檢測在應對復雜背景以及三維點云目標位姿估計在空間描繪上的優勢,可在復雜多變的家庭場景下引導機器人完成特定類別目標的智能化取放;
38、4、系統提供直觀的二維和三維人機交互界面,用戶可以通過簡單操作實時監控整個智能抓取過程,提升了系統操作便捷性,優化了用戶使用體驗。
- 還沒有人留言評論。精彩留言會獲得點贊!