一種前列腺神經內分泌癌預測模型的構建方法及系統
本發明涉及醫療信息處理,具體涉及一種前列腺神經內分泌癌預測模型的構建方法及系統。
背景技術:
1、前列腺神經內分泌癌預測模型是一種用于評估患者患前列腺神經內分泌癌(nepc)風險的工具或算法。nepc是一種罕見且高度惡性的前列腺癌亞型,通常在去勢抵抗性前列腺癌(crpc)患者中發生。該預測模型可能會結合多種因素,包括患者的臨床數據、基因表達特征、影像學結果等,通過計算或分析來預測某患者發展為nepc的可能性。這種模型旨在幫助醫生進行早期診斷和個性化治療決策,以改善患者的預后。
2、現有技術中,前列腺神經內分泌癌(nepc)預測模型通常通過收集和分析大量的患者數據構建。這些數據可能包括基因表達譜、蛋白質標志物、臨床特征(如年齡、病史、治療反應)以及影像學數據。研究人員運用機器學習或統計分析方法,從中提取與nepc發生相關的關鍵特征,并結合這些特征來訓練預測模型。最終模型經過驗證和優化后,可用于預測新患者發展為nepc的風險,從而輔助臨床決策。
3、現有技術中存在的不足之處:
4、由于nepc的發展時間較長,樣本數據可能跨越多個年代。隨著時間的推移,前列腺癌的診斷技術和治療方案不斷進步,這可能導致早期數據和近期數據之間存在顯著差異,即所謂的數據漂移。且如果模型訓練時未能及時識別和糾正這些差異,模型可能會基于發生漂移的數據進行預測,從而降低其在當前和未來患者群體中的準確性。
技術實現思路
1、本發明的目的是提供一種前列腺神經內分泌癌預測模型的構建方法及系統,以解決背景技術中不足。
2、為了實現上述目的,本發明提供如下技術方案:一種前列腺神經內分泌癌預測模型的構建方法,包括:
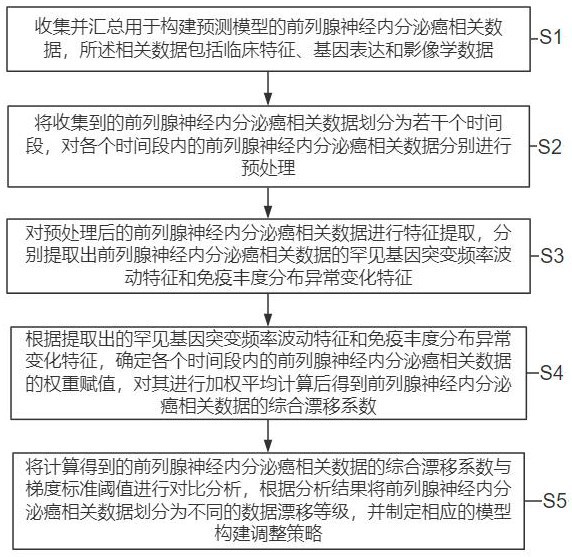
3、收集并匯總用于構建預測模型的前列腺神經內分泌癌相關數據,所述相關數據包括臨床特征、基因表達和影像學數據;
4、將收集到的前列腺神經內分泌癌相關數據劃分為若干個時間段,對各個時間段內的前列腺神經內分泌癌相關數據分別進行預處理;
5、對預處理后的前列腺神經內分泌癌相關數據進行特征提取,分別提取出前列腺神經內分泌癌相關數據的罕見基因突變頻率波動特征和免疫豐度分布異常變化特征;
6、根據提取出的罕見基因突變頻率波動特征和免疫豐度分布異常變化特征,確定各個時間段內的前列腺神經內分泌癌相關數據的權重賦值,對其進行加權平均計算后得到前列腺神經內分泌癌相關數據的綜合漂移系數;
7、將計算得到的前列腺神經內分泌癌相關數據的綜合漂移系數與梯度標準閾值進行對比分析,根據分析結果將前列腺神經內分泌癌相關數據劃分為不同的數據漂移等級,并制定相應的模型構建調整策略。
8、優選的,所述將收集到的前列腺神經內分泌癌相關數據劃分為若干個時間段,包括:
9、將前列腺神經內分泌癌相關數據按照時間順序整理,形成時間序列數據集x={x1,x2,…,xn},其中,xi是第i個時間點的數據,n是數據點的總數,計算時間序列的均值和標準差,將其作為時間序列分段的基礎;
10、將時間序列x劃分為k個區間,每個區間sj表示一個子序列xj={xsj,…,xej},其中,sj和ej分別為第j個區間的起始和結束位置,通過損失函數c(sj)來度量區間sj的內部變化,損失函數為:;其中,是區間內數據的均值,目標為通過動態規劃最小化整個時間序列的總損失函數,計算表達式為:;動態規劃的任務是找到使得總損失最小的變化點;創建一個數組dp用于存儲前i個數據點的最小損失值,初始化為dp[0]=0,其余為無窮大∞,定義一個數組p用于存儲每個分段的最佳分割點位置,對于每個時間點i,計算在各個可能的前一段時間點j之間的分割成本,表達式為:;存儲對應的最佳分割點j:p[i]=j;通過回溯p數組來找到最優的分割點序列,初始化tk=n,然后進行回溯:;繼續回溯,直到找到所有個分割點,最終得到的分割點序列?,即為數據特征發生顯著變化的節點位置,根據識別出的變化節點,將數據集劃分為多個時間段,并為每個數據點添加相應的時間段標簽。
11、優選的,所述分別提取出前列腺神經內分泌癌相關數據的罕見基因突變頻率波動特征和免疫豐度分布異常變化特征之后,所述方法還包括根據提取出前列腺神經內分泌癌相關數據的罕見基因突變頻率波動特征生成突變頻率波動指數,則突變頻率波動指數的獲取方法為:
12、將前列腺神經內分泌癌相關的基因突變頻率數據按照時間順序整理,形成一個時間序列x(t),其中,t是時間,x(t)是t時刻的突變頻率,對數據進行標準化,將標準化后的數據記為,表達式為:;其中,是突變頻率數據的均值,是其標準差,使用快速傅里葉變換將標準化后的時間序列從時間域轉換到頻率域,得到頻譜,表達式為:;其中, n是時間序列的長度, f是頻率,為傅里葉變換的核函數,計算基因突變頻率數據的頻譜幅值,頻譜幅值代表信號在各個頻率分量上的強度,計算表達式為:?;其中,是 x(f)的實部,是 x(f)的虛部,根據的幅值分布,獲取幅值的主頻率,計算頻譜中的總能量e,表達式為:;根據計算得到的頻譜中的總能量e計算突變頻率波動指數,表達式為:;式中,為突變頻率波動指數,表示選定的主頻率成分的能量總和。
13、優選的,所述分別提取出前列腺神經內分泌癌相關數據的罕見基因突變頻率波動特征和免疫豐度分布異常變化特征之后,所述方法還包括根據提取出的前列腺神經內分泌癌相關數據的免疫豐度分布異常變化特征生成免疫豐度分布異常指數,則免疫豐度分布異常指數的獲取方法為:
14、收集前列腺神經內分泌癌患者的免疫相關數據,包括不同免疫細胞類型的豐度;對免疫豐度數據進行標準化處理,計算每個免疫細胞類型在患者樣本中的豐度分布均值和標準差;對每個樣本中的免疫豐度值進行檢測,判斷其是否偏離正常分布,確定異常免疫豐度值,表達式為:或;其中,k是常數;統計每個樣本中異常免疫豐度值的數量,以及異常值的偏離程度,表達式為:;s為免疫細胞類別的標號,計算免疫豐度分布異常指數,表達式為:;式中,m是免疫細胞類型的總數,是第i類免疫細胞的異常免疫豐度值的數量,是第i類免疫細胞的樣本總數,是第i類免疫細胞異常免疫豐度值的偏離程度總和,是第i類免疫細胞的總偏離程度,為免疫豐度分布異常指數。
15、優選的,所述根據提取出的罕見基因突變頻率波動特征和免疫豐度分布異常變化特征,確定各個時間段內的前列腺神經內分泌癌相關數據的權重賦值,對其進行加權平均計算后得到前列腺神經內分泌癌相關數據的綜合漂移系數,包括:
16、將突變頻率波動指數和免疫豐度分布異常指數轉換為第一特征向量,將第一特征向量作為機器學習模型的輸入,機器學習模型以每組第一特征向量預測各個時間段內的前列腺神經內分泌癌相關數據的權重賦值標簽為預測目標,以最小化對所有時間段內的前列腺神經內分泌癌相關數據的權重賦值標簽的預測誤差之和作為訓練目標,對機器學習模型進行訓練,直至預測誤差之和達到收斂時停止模型訓練,根據模型輸出結果確定各個時間段內的前列腺神經內分泌癌相關數據的權重賦值,其中,機器學習模型為多項式回歸模型,對各個時間段內的前列腺神經內分泌癌相關數據的權重賦值進行加權平均計算后得到前列腺神經內分泌癌相關數據的綜合漂移系數。
17、優選的,所述將計算得到的前列腺神經內分泌癌相關數據的綜合漂移系數與梯度標準閾值進行對比分析,根據分析結果將前列腺神經內分泌癌相關數據劃分為不同的數據漂移等級,并制定相應的模型構建調整策略,包括:
18、將計算得到的前列腺神經內分泌癌相關數據的綜合漂移系數與梯度標準閾值進行比較,梯度標準閾值包括第一標準閾值和第二標準閾值,且第一標準閾值小于第二標準閾值,將綜合漂移系數分別與第一標準閾值和第二標準閾值進行對比;
19、若綜合漂移系數大于第二標準閾值,將前列腺神經內分泌癌相關數據劃分為數據高漂移等級,并生成數據異常信號;需要對數據進行重新分析和建模;
20、若綜合漂移系數大于等于第一標準閾值且小于等于第二標準閾值,將前列腺神經內分泌癌相關數據劃分為數據中漂移等級,并生成數據疑似異常信號;對現有模型進行參數調整;
21、若綜合漂移系數小于第一標準閾值,將前列腺神經內分泌癌相關數據劃分為數據低漂移等級,并生成數據正常信號,保持現有模型不變,繼續進行預測。
22、本發明還提供了一種前列腺神經內分泌癌預測模型的構建系統,包括數據獲取模塊、數據劃分模塊、特征提取模塊,綜合漂移系數計算模塊以及模型調整模塊;
23、數據獲取模塊:收集并匯總用于構建預測模型的前列腺神經內分泌癌相關數據,所述相關數據包括臨床特征、基因表達和影像學數據;
24、數據劃分模塊:將收集到的前列腺神經內分泌癌相關數據劃分為若干個時間段,對各個時間段內的前列腺神經內分泌癌相關數據分別進行預處理;
25、特征提取模塊:對預處理后的前列腺神經內分泌癌相關數據進行特征提取,分別提取出前列腺神經內分泌癌相關數據的罕見基因突變頻率波動特征和免疫豐度分布異常變化特征;
26、綜合漂移系數計算模塊:根據提取出的罕見基因突變頻率波動特征和免疫豐度分布異常變化特征,確定各個時間段內的前列腺神經內分泌癌相關數據的權重賦值,對其進行加權平均計算后得到前列腺神經內分泌癌相關數據的綜合漂移系數;
27、模型調整模塊:將計算得到的前列腺神經內分泌癌相關數據的綜合漂移系數與梯度標準閾值進行對比分析,根據分析結果將前列腺神經內分泌癌相關數據劃分為不同的數據漂移等級,并制定相應的模型構建調整策略。
28、在上述技術方案中,本發明提供的技術效果和優點:
29、本發明通過系統化的步驟和算法,有效解決了前列腺神經內分泌癌預測模型在數據跨越多個年代時可能面臨的數據漂移問題。通過對數據進行時間段劃分、特征提取和綜合漂移系數計算,并結合梯度標準閾值進行分析,能夠精準識別數據的漂移程度,并針對不同的漂移等級制定相應的模型調整策略。這一流程確保了模型在不斷變化的臨床數據環境中保持高水平的預測準確性和穩定性。
30、本發明通過靈活的模型調整策略,根據數據漂移的不同等級,采取相應的模型重建、微調或保持策略,從而在模型性能和臨床實用性之間實現平衡。整體而言,這種方法能夠顯著提升nepc預測模型的魯棒性,確保模型在不斷變化的臨床數據環境中,依然能夠提供可靠的預測結果,最終為臨床決策和個性化治療方案的制定提供強有力的支持。
- 還沒有人留言評論。精彩留言會獲得點贊!