一種包含異常血糖概率報警器的連續血糖監測設備的制作方法
本發明屬于血糖預測報警和分析的研究領域,特別是涉及一種包含異常血糖概率報警器的連續血糖監測設備。
背景技術:
為了實現良好的血糖控制,必須要對血糖水平進行測量,目前采用的是連續血糖監測(cgm)設備。隨著連續血糖監測設備的快速發展,使得更高精度的控制變為了可能,實時的cgm系統對高低血糖的提前檢測起到了重要的作用。然而,根據當前的cgm設備采集到的血糖值進行報警,再采取相應的治療措施會延遲對于血糖的控制,一方面胰島素在體內產生作用會有一定的時間,因此會延遲對于高血糖的控制;另一方面碳水化合物在體內也會過一段時間才產生作用,因此會延遲對于低血糖的控制。所以需要提前一段時間進行血糖預測,根據預測的血糖情況來選擇合適的治療策略。傳統的預測報警方法是直接將預測的血糖值和高低血糖報警閾值進行比較,超過報警閾值就會產生報警。然而由于預測方法都有一定的預測誤差,因此預測值和真實的血糖值會有一定的偏差,直接用預測的血糖值進行報警會產生漏報和誤報,嚴重影響血糖的控制策略,影響到病人的血糖控制。
技術實現要素:
本發明的目的在于針對現有預測報警方法的不足,提供一種包含異常血糖概率報警器的連續血糖監測設備。
本發明的目的是通過以下技術方案來實現的:一種包含異常血糖概率報警器的連續血糖監測設備,該設備包括:用于采集人體血糖信息,輸出血糖可用信號的傳感器;用于對傳感器的輸出信號進行放大處理的信號放大器;用于對信號放大器輸出的模擬信號進行數字轉換的單片機;用于對單片機輸出的數字信號進行數據處理的濾波器;用于將濾波后的血糖值進行異常血糖報警概率計算的異常血糖概率報警器;用于進行數值和波形顯示的顯示器;用于數據存儲的存儲器;所述報警器進行異常血糖報警概率計算的過程包括以下步驟:
(1)血糖預測誤差的獲得:通過選定的預測模型的血糖預測值
其中yi是第i個時刻連續血糖監測設備的采樣值,
(2)通過基于高斯混合模型(gmm)的方法估計血糖預測誤差的分布情況;
(3)根據步驟(2)的預測誤差分布估計,進行在線血糖采樣點的高低血糖報警概率的計算,具體包括以下子步驟:
(3.1)計算預測誤差概率密度函數的中位數點:
其中p(e|θ)是步驟(2)中估計的預測誤差概率密度函數,θ是gmm中待估計的參數,即θ=(μ,σ),μ是gmm中各個單高斯模型的均值,σ是gmm中各個單高斯模型的協方差矩陣,c是概率密度函數的中位數點;
(3.2)根據95%的置信度確定預測誤差的置信區間:
其中σ是置信半徑,c-σ是置信下限,c+σ是置信上限;
(3.3)計算每個血糖預測值的異常血糖報警概率:
(3.3.1)如果血糖預測值加上預測誤差的置信下限高于高血糖報警閾值,或者血糖預測值加上預測誤差的置信上限低于低血糖報警閾值,則報警概率為1,即產生報警;
(3.3.2)如果高低血糖報警閾值在血糖預測值置信區間內,則要計算該預測值的高低血糖報警概率,按照下式定義報警距離dlow和dhigh:
其中hlow是低血糖報警閾值,hhigh是高血糖報警閾值,dlow是預測值與低血糖報警閾值的距離,dhigh是預測值與高血糖報警閾值的距離;則高低血糖的概率按照如下公式計算:
其中是plow低血糖報警概率,phigh是高血糖報警概率;
(4)根據新的血糖采樣值得到的新的預測誤差更新gmm參數。
進一步地,所述步驟(2)具體包括以下子步驟:
(2.1)估計步驟(1)中獲得的預測誤差e={e1,e2,…,en}的分布,假定預測誤差的概率密度函數由k個單高斯模型組成,gmm的概率密度函數為:
其中p(e|θ)是預測誤差概率密度函數,αk是第k個單高斯模型的權值,φ(e|θk)是第k個單高斯模型的概率密度函數,其滿足:
其中μk是第k個單高斯模型的均值,是第k個單高斯模型的協方差矩陣σk,θk是第k個單高斯模型參數集,即θk=(μk,σk),n為e的維數,這里e是一維變量,因此n=1;
(2.2)采用em算法估計gmm的參數,具體步驟如下:
(2.2.1)對于αk,μk和σk賦初值,k=1,2,…,k;
(2.2.2)計算后驗概率
其中
(2.2.3)計算
其中
所述步驟(4)具體包括以下子步驟:
(4.1)對于新獲得的預測誤差en+1,根據式(7)分別計算en+1對應的每個單高斯模型的概率密度函數φ(en+1|θk);
(4.2)找出其中概率密度函數最大的值所對應的單高斯模型mk,判斷en+1是否在單高斯模型95%的置信區間內,如果在該單高斯模型的95%的置信區間內,則該單高斯模型mk是en+1的匹配單高斯模型,采用更新算法更新gmm的參數;如果連續有三個預測誤差不在概率密度函數最大的值對應的單高斯模型的95%的置信區間內,則認為gmm的結構發生改變,根據式(8)-(11)重新進行gmm參數估計;
(4.3)gmm參數更新算法如下:
ρ=λ*φ(en+1|θk)(16)
其中,p(mi|en+1)是標志符,只有預測誤差en+1匹配的單高斯模型mk其標志符p(mk|en+1)才為1,其他的單高斯模型的標志符為0;
與現有技術相比,本發明的有益效果是:本發明所提出的包含異常血糖概率報警器的連續血糖監測設備能夠根據預測誤差的分布估計出血糖預測值的高低血糖報警概率,而不是直接將預測的血糖值與高低血糖報警閾值進行比較而給出是否報警。因此,病人可以根據異常血糖報警概率來制定合適的治療計劃,以此避免異常血糖事件。本發明易于實施,為血糖處理和分析的研究指明了新的方向。
附圖說明
圖1是本發明連續血糖監測設備的結構框圖;
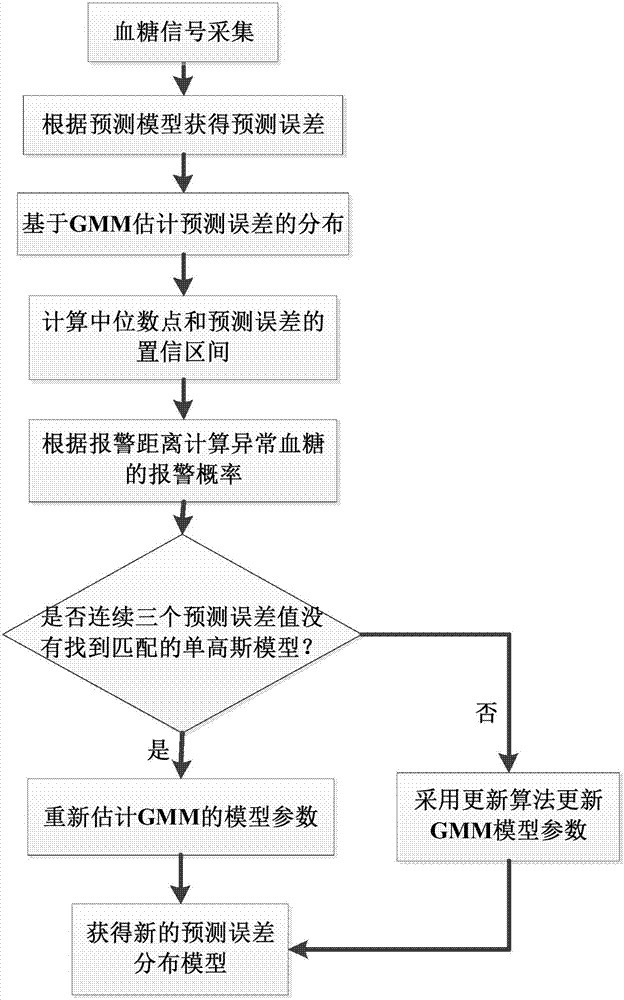
圖2是本發明連續血糖監測設備中異常血糖報警概率計算的實現流程圖;
圖3是對象7分別采用ar和arx模型進行預測所產生的預測誤差的分布函數圖像,(a)ar預測模型(b)arx預測模型;
圖4是對象7采用ar模型進行預測的血糖預測值和血糖測量值,以及對應的高低血糖報警概率和傳統報警方法的對比,(a)后三天的結果(b)低血糖報警概率局部放大圖(c)高血糖報警概率局部放大圖;
圖5是對象7采用arx模型進行預測的血糖預測值和血糖測量值,以及對應的高低血糖報警概率和傳統報警方法的對比,(a)后三天的結果(b)低血糖報警概率局部放大圖(c)高血糖報警概率局部放大圖。
具體實施方式
下面結合附圖和具體實施例對本發明作進一步詳細說明。
如圖1所示,本發明提供的一種包含異常血糖概率報警器的連續血糖監測設備,包括:用于采集人體血糖信息,輸出血糖可用信號的傳感器;用于對傳感器的輸出信號進行放大處理的信號放大器;用于對信號放大器輸出的模擬信號進行數字轉換的單片機;用于對單片機輸出的數字信號進行數據處理的濾波器;用于將濾波后的血糖值進行異常血糖報警概率計算的異常血糖概率報警器;用于進行數值和波形顯示的顯示器;用于數據存儲的存儲器;所述報警器進行異常血糖報警概率計算的過程包括以下步驟:
步驟1:獲得血糖預測誤差
將以采樣周期為5分鐘所獲得的連續血糖監測信號組合成一維時序數據y1×l,其中,y表示檢測到的血糖信號,l為樣個數,去除其中的尖峰信號。本實例中,共有三組對象的采樣信號,采樣周期為5分鐘,第1組為青少年組,第2組為成人組,第3組為兒童組,每組10人,三組共30人,每個對象的采樣信號包括五天的數據。
這里采用ar模型和arx模型進行預測,arx的通用公式為:
其中y(k)是血糖值,uins(k-kins)和umeal(k-kmeal)分別是胰島素和飲食輸入量,kins是胰島素的輸入延遲,kmeal是飲食的輸入延遲,β是偏差值,ε(k)是隨機擾動,a(q-1),bins(q-1)和bmeal(q-1)分別代表血糖,胰島素和飲食的系數。這里,對于ar模型,選取bins(q-1)=bmeal(q-1)=0,a(q-1)階數是7;對于arx模型,選取a(q-1),bins(q-1)和bmeal(q-1)的階數分別是7,4和4;
第一天的血糖數據用于ar和arx建模,隨后對于第二天的血糖數據進行預測,從而得到血糖的預測誤差e:
其中yi是第i個時刻連續血糖監測設備的采樣值,
步驟2:通過基于高斯混合模型(gmm)的方法估計血糖預測誤差的分布情況,具體包括以下子步驟:
(2.1)估計步驟1中獲得的預測誤差e={e1,e2,…,en}的分布,假定預測誤差的概率密度函數由k個單高斯模型組成,這里選取k=4,gmm的概率密度函數為:
其中p(e|θ)是預測誤差概率密度函數,αk是第k個單高斯模型的權值,φ(e|θk)是第k個單高斯模型的概率密度函數,其滿足:
其中μk是第k個單高斯模型的均值,是第k個單高斯模型的協方差矩陣σk,θk是第k個單高斯模型參數集,即θk=(μk,σk),n為e的維數,這里e是一維變量,因此n=1;
(2.2)采用em算法估計gmm的參數,具體步驟如下:
(2.2.1)對于αk,μk和σk賦初值,k=1,2,…,k;
(2.2.2)計算后驗概率
其中
(2.2.3)計算
其中
步驟3:根據步驟2的預測誤差分布估計,進行在線血糖采樣點的高低血糖報警概率的計算,具體包括以下子步驟:
(3.1)計算預測誤差概率密度函數的中位數點:
其中p(e|θ)是步驟2中估計的預測誤差概率密度函數,θ是gmm中待估計的參數,即θ=(μ,σ),μ是gmm中各個單高斯模型的均值,σ是gmm中各個單高斯模型的協方差矩陣,c是概率密度函數的中位數點;
(3.2)根據95%的置信度確定預測誤差的置信區間:
其中σ是置信半徑,c-σ是置信下限,c+σ是置信上限;
(3.3)計算每個血糖預測值的異常血糖報警概率:
(3.3.1)如果血糖預測值加上預測誤差的置信下限高于高血糖報警閾值,或者血糖預測值加上預測誤差的置信上限低于低血糖報警閾值,則報警概率為1,即產生報警;
(3.3.2)如果高低血糖報警閾值在血糖預測值置信區間內,則要計算該預測值的高低血糖報警概率,按照下式定義報警距離dlow和dhigh:
其中hlow是低血糖報警閾值,hhigh是高血糖報警閾值,這里低血糖報警閾值設置為70mg/dl,高血糖報警閾值設置為180mg/dl,dlow是預測值與低血糖報警閾值的距離,dhigh是預測值與高血糖報警閾值的距離;則高低血糖的概率按照如下公式計算:
其中是plow低血糖報警概率,phigh是高血糖報警概率;
步驟4:根據新的血糖采樣值得到的新的預測誤差更新gmm參數,具體包括以下子步驟:
(4.1)對于新獲得的預測誤差en+1,根據式(4)分別計算en+1對應的每個單高斯模型的概率密度函數φ(en+1|θk);
(4.2)找出其中概率密度函數最大的值所對應的單高斯模型mk,判斷en+1是否在單高斯模型95%的置信區間內,如果在該單高斯模型的95%的置信區間內,則該單高斯模型mk是en+1的匹配單高斯模型,采用更新算法更新gmm的參數;如果連續有三個預測誤差不在概率密度函數最大的值對應的單高斯模型的95%的置信區間內,則認為gmm的結構發生改變,根據式(5)-(8)重新進行gmm參數估計;
(4.3)gmm參數更新算法如下:
ρ=λ*φ(en+1|θk)(17)
其中,p(mi|en+1)是標志符,只有預測誤差en+1匹配的單高斯模型mk其標志符p(mk|en+1)才為1,其他的單高斯模型的標志符為0;
圖4和圖5分別展示了對象7采用ar模型和arx模型進行預測的血糖預測值和血糖測量值,以及對應的高斯血糖報警概率和傳統報警方法的對比。
步驟5:根據計算的報警概率與傳統的報警方法進行對比,這里采用正確的報警,誤報的次數,漏報的次數以及報警的延遲四方面進行對比。這里選取40%的報警概率作為報警閾值,大于40%的概率即產生報警。表1針對3組(青少年組、成人組和兒童組)共30個對象的血糖采樣數據對于傳統的報警方法和基于報警概率的方法進行了對比,可以看出,基于概率報警的方法有更多的正確報警次數,較少的誤報和漏報次數,同時,報警延遲也要小于傳統的報警方法。
表1針對3組(青少年組、成人組和兒童組)共30個對象的血糖采樣數據對于傳統的報警方法和基于報警概率的方法進行了對比(結果用均值±標準差表示)
*a/ba是正確報警或者漏報的個數;b是總共的高/低血糖事件。
- 還沒有人留言評論。精彩留言會獲得點贊!