血壓預測的方法及裝置與流程
本發明涉及醫療信息化技術領域,具體而言,涉及一種血壓預測的方法及裝置。
背景技術:
血壓是血液在血管內流動時作用于血管壁的壓力,它是推動血液在血管內流動的動力。正常的血壓是血液循環流動的前提,血壓在多種因素調節下保持正常,從而提供各組織器官以足夠的血量,以維持正常的新陳代謝。血壓過低(低血壓)或過高(高血壓)都會造成嚴重后果,血壓消失是死亡的前兆,這都說明血壓有極其重要的生物學意義。
目前,人體動脈血壓測定要用間接測定法,通常使用俄國醫師N.科羅特科夫發明的測定法,該測定法使用的裝置包括能充氣的袖袋和與之相連的測壓計,將袖袋綁在受試者的上臂,然后打氣到阻斷肱動脈血流為止,緩緩放出袖袋內的空氣,利用放在肱動脈上的聽診器可以聽到當袖袋壓剛小于肱動脈血壓血流沖過被壓扁動脈時產生的湍流引起的振動聲(科羅特科夫氏聲,簡稱科氏聲)來測定心臟收縮期的最高壓力,叫做收縮壓;繼續放氣,科氏聲加大,當此聲變得低沉而長時所測得的血壓讀數,相當于心臟舒張時的最低血壓,叫做舒張壓;當放氣到袖袋內壓低于舒張壓時,血流平穩地流過無阻礙的血管,科氏聲消失。
由于汞的比重太大,水銀測壓計難以精確迅速地反映心搏各期血壓的瞬間變化,所以后來改用各種靈敏的薄膜測壓計可以較準確地測得收縮和舒張壓。近年來常使用各種換能器與示波器結合可以更靈敏地測定記錄血壓。
整體看來,目前的方法都是對人體當前的血壓進行測量,不能夠預測人體未來的血壓。若能夠提前預測人體血壓,那么對于病患人群,尤其是對于高血壓患者來說都極為重要。雖然相關技術中也有通過固定結構神經網絡來對血壓數據進行分析,但是由于神經網絡結構固定,網絡 自適應較差,難以滿足復雜的應用場景。
因此,需要一種新的血壓預測方法來實現對血壓的有效預測。
需要說明的是,在上述背景技術部分公開的信息僅用于加強對本發明的背景的理解,因此可以包括不構成對本領域普通技術人員已知的現有技術的信息。
技術實現要素:
本發明的目的在于提供一種血壓預測的方法及裝置,進而至少在一定程度上克服由于相關技術的限制和缺陷而導致的一個或者多個問題。
本發明的其他特性和優點將通過下面的詳細描述變得顯然,或部分地通過本發明的實踐而習得。
根據本發明的一個方面,提供一種血壓預測的方法,包括:
配置用于進行血壓預測的神經網絡;
基于預設的多組訓練樣本對所述神經網絡進行訓練,得到訓練后的神經網絡;
根據訓練后的神經網絡,對人體的血壓數據進行預測。
在本發明的一些實施例中,基于前述方案,所述的血壓預測的方法還包括:
采集用戶的多個血壓數據;
基于所述多個血壓數據,形成所述多組訓練樣本,其中,每組訓練樣本包含M+1個血壓數據,所述M+1個血壓數據中按照采集順序的前M個血壓數據作為所述每組訓練樣本的輸入參數,第M+1個血壓數據作為所述每組訓練樣本的輸出參數。
在本發明的一些實施例中,基于前述方案,其中,基于預定時間間隔采集所述用戶的多個血壓數據。
在本發明的一些實施例中,基于前述方案,所述神經網絡包括:M個輸入層神經元、K個隱含層神經元和1個輸出層神經元。
在本發明的一些實施例中,基于前述方案,通過以下公式計算所述神經網絡的輸出:
其中,y(t)表示所述神經網絡的實際輸出;wk(t)表示所述隱含層神經元中第k個神經元和所述輸出層神經元的連接權值,k=1,2,…,K;φk(x(t))表示所述隱含層神經元中的第k個神經元的輸出。
在本發明的一些實施例中,基于前述方案,基于以下公式計算所述φk(x(t))的值:
其中,μk表示所述隱含層神經元中的第k個神經元的中心值,σk表示所述隱含層神經元中的第k個神經元的中心寬度。
在本發明的一些實施例中,基于前述方案,基于預設的多組訓練樣本對所述神經網絡進行訓練,包括:
將所述神經網絡中的參數表示為粒子群中的粒子,并初始化粒子群;
通過所述預設的多組訓練樣本對所述粒子群進行迭代優化,直至滿足迭代終止條件。
在本發明的一些實施例中,基于前述方案,對所述粒子群進行迭代優化時的任一次優化過程,包括:
計算所述粒子群中每個粒子的適應度值;
根據所述每個粒子的適應度值,確定所述每個粒子的歷史最優位置和全局最優位置;
基于所述每個粒子的歷史最優位置和全局最優位置,更新所述每個粒子的位置和速度;
基于所述每個粒子的全局最優位置,確定所述神經網絡的最優網絡結構,以更新所述每個粒子對應的隱含層神經元的個數。
在本發明的一些實施例中,基于前述方案,通過以下公式將所述神經網絡中的參數表示為粒子群中的粒子:
其中,ai表示第i個粒子的位置,i=1,2,…,s;s表示粒子群中的粒子總個數,s為正整數;μi,k、σi,k和wi,k分別表示第i個粒子的第k個隱含層神經元的中心值、中心寬度和連接權值;Ki表示第i個粒子表示的神經網絡的隱含層神經元數;μi,k、σi,k和wi,k的初始值取(0,1)中的任意數,Ki的初始值為任意正整數。
在本發明的一些實施例中,基于前述方案,初始化粒子群,包括:
初始化粒子群加速常數c1和c2,c1∈(0,1),c2∈(0,1);
設定粒子群平衡權值α∈[0,1];
初始化粒子的速度:其中,vi表示第i個粒子的速度,Di表示第i個粒子的維數,Di=3Ki。
在本發明的一些實施例中,基于前述方案,通過以下公式計算所述粒子群中每個粒子的適應度值:
其中,f(ai(t))表示所述每個粒子的適應度值;i=1,2,…,s;s表示粒子群中的粒子總個數,s為正整數;T表示所述預設的訓練樣本的個數;y(t)表示所述神經網絡的實際輸出;yd(t)表示所述神經網絡的期望輸出。
在本發明的一些實施例中,基于前述方案,根據所述每個粒子的適應度值,確定所述每個粒子的歷史最優位置和全局最優位置,包括:
計算所述每個粒子的慣性權重:ωi(t)=S(t)tAi(t);
其中,t表示對所述粒子群進行迭代優化的次數;S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t));fmin(a(t))、fmax(a(t))分別表示當前時刻的最小適應度值和最大適應度值,g(t)表示粒子全局最優位置,且fmin(a(t))、fmax(a(t))和g(t)分別表示為:
其中,每個粒子的歷史最優位置pi(t)通過以下公式表示:
在本發明的一些實施例中,基于前述方案,通過以下公式更新所述每個粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t);
其中,r1和r2分別表示每個粒子的歷史最優位置系數和全局最優位置系數,r1和r2取[0,1]中的任意數。
在本發明的一些實施例中,基于前述方案,通過以下公式更新所述每個粒子對應的隱含層神經元的個數:
其中,Ki(t)表示更新后的所述每個粒子對應的隱含層神經元的個數;Ki(t-1)表示更新前的所述每個粒子對應的隱含層神經元的個數;Kbest表示所述神經網絡的最優網絡結構的隱含層神經元個數。
在本發明的一些實施例中,基于前述方案,所述神經網絡包括自組織徑向基神經網絡。
根據本發明的另一方面,還提出了一種血壓預測的裝置,包括:
配置單元,用于配置用于進行血壓預測的神經網絡;
訓練處理單元,用于基于預設的多組訓練樣本對所述神經網絡進行訓練,得到訓練后的神經網絡;
預測處理單元,用于根據訓練后的神經網絡,對人體的血壓數據進行預測。
在本發明的一些實施例所提供的技術方案中,通過配置進行血壓預測的神經網絡,并基于預設的多組訓練樣本來對神經網絡進行訓練,進而通過訓練后的神經網絡來進行血壓預測,使得能夠提前預知人體的血壓值,以將其作為血壓參考,確保醫生及患者可以提前了解血壓的變化情況,從而提前采取相應的預防措施,對于健康管理和疾病治療具有極大的意義。
在本發明的一些實施例所提供的技術方案中,通過采集用戶的多個血壓數據以形成多組訓練樣本,進而基于這些訓練樣本來對神經網絡進行訓練,使得能夠利用人體的歷史血壓數據作為訓練樣本來實現對神經網絡的校正,進而能夠確保快速、準確地對人體血壓進行預測,有利于疾病的預防和健康管理。
應當理解的是,以上的一般描述和后文的細節描述僅是示例性和解釋性的,并不能限制本發明。
附圖說明
此處的附圖被并入說明書中并構成本說明書的一部分,示出了符合本發明的實施例,并與說明書一起用于解釋本發明的原理。顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。在附圖中:
圖1示意性示出了根據本發明的一個實施例的血壓預測的方法的流程圖;
圖2示意性示出了根據本發明的一個實施例的神經網絡的結構圖;
圖3示意性示出了根據本發明的一個實施例的基于自組織徑向基神經網絡的血壓預測方法的流程圖;
圖4示意性示出了根據本發明的一個實施例的自組織徑向基神經網絡的結構圖;
圖5示意性示出了根據本發明的一個實施例的血壓預測的裝置的框圖。
具體實施方式
現在將參考附圖更全面地描述示例實施方式。然而,示例實施方式能夠以多種形式實施,且不應被理解為限于在此闡述的范例;相反,提供這些實施方式使得本發明將更加全面和完整,并將示例實施方式的構思全面地傳達給本領域的技術人員。
此外,所描述的特征、結構或特性可以以任何合適的方式結合在一個或更多實施例中。在下面的描述中,提供許多具體細節從而給出對本發明的實施例的充分理解。然而,本領域技術人員將意識到,可以實踐本發明的技術方案而沒有特定細節中的一個或更多,或者可以采用其它的方法、組元、裝置、步驟等。在其它情況下,不詳細示出或描述公知方法、裝置、實現或者操作以避免模糊本發明的各方面。
附圖中所示的方框圖僅僅是功能實體,不一定必須與物理上獨立的實體相對應。即,可以采用軟件形式來實現這些功能實體,或在一個或多個硬件模塊或集成電路中實現這些功能實體,或在不同網絡和/或處理器裝置和/或微控制器裝置中實現這些功能實體。
附圖中所示的流程圖僅是示例性說明,不是必須包括所有的內容和 操作/步驟,也不是必須按所描述的順序執行。例如,有的操作/步驟還可以分解,而有的操作/步驟可以合并或部分合并,因此實際執行的順序有可能根據實際情況改變。
圖1示意性示出了根據本發明的一個實施例的血壓預測的方法的流程圖。
如圖1所示,根據本發明的一個實施例的血壓預測的方法,包括:
步驟S102,配置用于進行血壓預測的神經網絡。
需要說明的是:在本發明的實施例中,神經網絡是一種應用類似于大腦神經突觸聯接的結構進行信息處理的數學模型,這種網絡依靠系統的復雜程度,通過調整內部大量節點之間相互連接的關系,從而達到處理信息的目的。其中,神經網絡可以是自組織徑向基神經網絡,也可以是前饋神經網絡,還可以是其它神經網絡。
步驟S104,基于預設的多組訓練樣本對所述神經網絡進行訓練,得到訓練后的神經網絡。
需要說明的是:訓練樣本的作用是為了確定神經網絡的相關參數,當通過訓練樣本對神經網絡進行訓練之后,可以認為神經網絡的結構已經確定。
根據本發明的示例性實施例,所述的血壓預測的方法還包括:采集用戶的多個血壓數據;基于所述多個血壓數據,形成所述多組訓練樣本,其中,每組訓練樣本包含M+1個血壓數據,所述M+1個血壓數據中按照采集順序的前M個血壓數據作為所述每組訓練樣本的輸入參數,第M+1個血壓數據作為所述每組訓練樣本的輸出參數。
在該示例性實施例中,通過采集用戶的多個血壓數據,以形成多組訓練樣本,使得能夠利用人體的歷史血壓數據來對神經網絡進行訓練,以校正神經網絡的參數,進而可以確保校正后的神經網絡能夠準確地實現對人體血壓的預測。
根據本發明的示例性實施例,可以基于預定時間間隔采集所述用戶的多個血壓數據。譬如每隔1小時采集用戶的一個血壓數據。
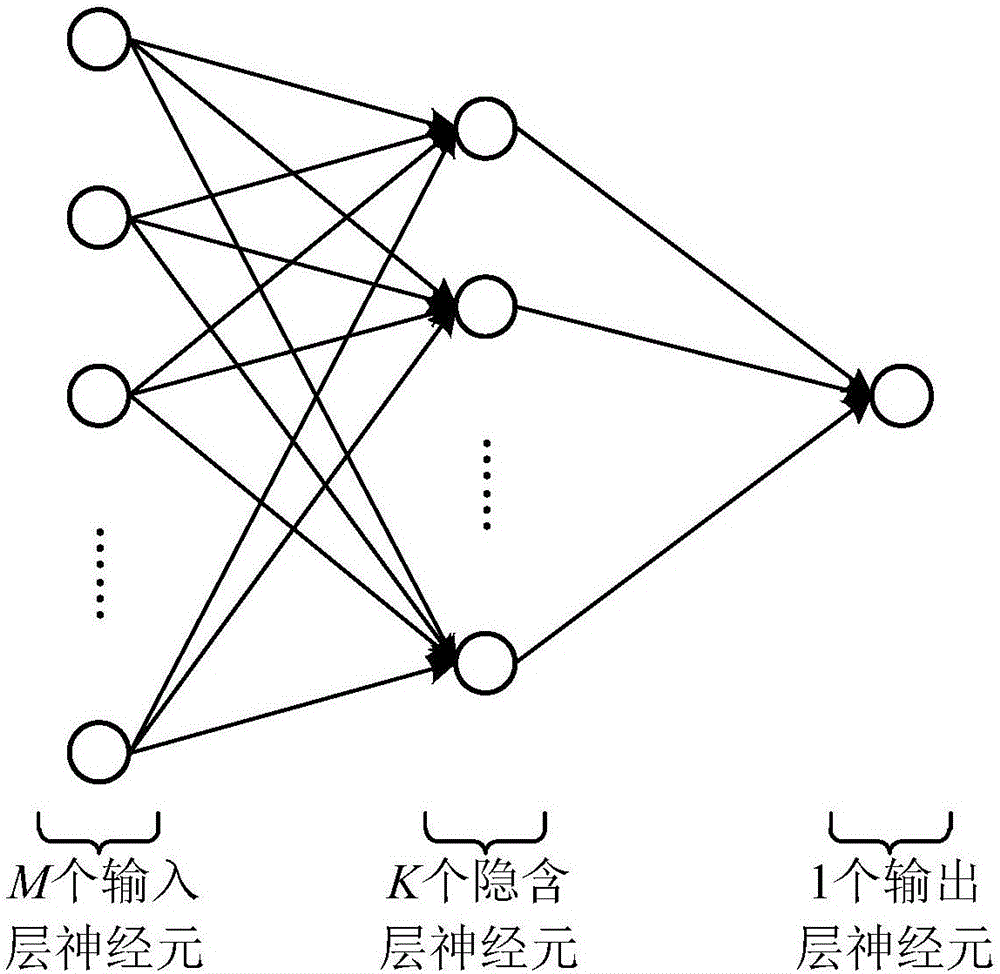
根據本發明的示例性實施例,如圖2所示,神經網絡包括:M個輸入層神經元、K個隱含層神經元和1個輸出層神經元。換句話說,神經網絡的結構是M-K-1的連接方式。
根據本發明的示例性實施例,通過以下公式計算所述神經網絡的輸出:
其中,y(t)表示所述神經網絡的實際輸出;wk(t)表示所述隱含層神經元中第k個神經元和所述輸出層神經元的連接權值,k=1,2,…,K;φk(x(t))表示所述隱含層神經元中的第k個神經元的輸出,具體可基于以下公式計算所述φk(x(t))的值:
其中,μk表示所述隱含層神經元中的第k個神經元的中心值,σk表示所述隱含層神經元中的第k個神經元的中心寬度。
根據本發明的示例性實施例,步驟S104中基于預設的多組訓練樣本對所述神經網絡進行訓練,具體包括:
將所述神經網絡中的參數表示為粒子群中的粒子,并初始化粒子群;
通過所述預設的多組訓練樣本對所述粒子群進行迭代優化,直至滿足迭代終止條件。
需要說明的是,對粒子群進行迭代優化是指通過預設的多組訓練樣本多次對粒子群進行迭代優化,以對神經網絡的結構進行優化。其中,迭代終止條件可以是迭代的次數達到設定的次數和/或優化后的精度達到了設定精度。
根據本發明的示例性實施例,對所述粒子群進行迭代優化時的任一次優化過程,包括:
計算所述粒子群中每個粒子的適應度值;
根據所述每個粒子的適應度值,確定所述每個粒子的歷史最優位置和全局最優位置;
基于所述每個粒子的歷史最優位置和全局最優位置,更新所述每個粒子的位置和速度;
基于所述每個粒子的全局最優位置,確定所述神經網絡的最優網絡結構,以更新所述每個粒子對應的隱含層神經元的個數。
根據本發明的示例性實施例,通過以下公式將所述神經網絡中的參 數表示為粒子群中的粒子:
其中,ai表示第i個粒子的位置,i=1,2,…,s;s表示粒子群中的粒子總個數,s為正整數;μi,k、σi,k和wi,k分別表示第i個粒子的第k個隱含層神經元的中心值、中心寬度和連接權值;Ki表示第i個粒子表示的神經網絡的隱含層神經元數;μi,k、σi,k和wi,k的初始值取(0,1)中的任意數,Ki的初始值為任意正整數。
在本發明的一些實施例中,基于前述方案,初始化粒子群,包括:
初始化粒子群加速常數c1和c2,c1∈(0,1),c2∈(0,1);
設定粒子群平衡權值α∈[0,1];
初始化粒子的速度:其中,vi表示第i個粒子的速度,Di表示第i個粒子的維數,Di=3Ki。
根據本發明的示例性實施例,通過以下公式計算所述粒子群中每個粒子的適應度值:
其中,f(ai(t))表示所述每個粒子的適應度值;i=1,2,…,s;s表示粒子群中的粒子總個數,s為正整數;T表示所述預設的訓練樣本的個數;y(t)表示所述神經網絡的實際輸出;yd(t)表示所述神經網絡的期望輸出。
根據本發明的示例性實施例,根據所述每個粒子的適應度值,確定所述每個粒子的歷史最優位置和全局最優位置,包括:
計算所述每個粒子的慣性權重:ωi(t)=S(t)tAi(t);
其中,t表示對所述粒子群進行迭代優化的次數;S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t));fmin(a(t))、fmax(a(t))分別表示當前時刻的最小適應度值和最大適應度值,g(t)表示粒子全局最優位置,且fmin(a(t))、fmax(a(t))和g(t)分別表示為:
其中,每個粒子的歷史最優位置pi(t)通過以下公式表示:
根據本發明的示例性實施例,通過以下公式更新所述每個粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t);
其中,r1和r2分別表示每個粒子的歷史最優位置系數和全局最優位置系數,r1和r2取[0,1]中的任意數。
根據本發明的示例性實施例,通過以下公式更新所述每個粒子對應的隱含層神經元的個數:
其中,Ki(t)表示更新后的所述每個粒子對應的隱含層神經元的個數;Ki(t-1)表示更新前的所述每個粒子對應的隱含層神經元的個數;Kbest表示所述神經網絡的最優網絡結構的隱含層神經元個數。
圖1所示的血壓預測的方法還包括:
步驟S106,根據訓練后的神經網絡,對人體的血壓數據進行預測。
根據本發明的示例性實施例,在步驟S106中,可以將檢測到的用戶的若干個血壓數據作為訓練后的神經網絡的輸入,那么訓練后的神經網絡的輸出即為預測到的血壓數據。
在本發明的一個示例性實施例中,神經網絡可以是自組織徑向基神經網絡,以下結合圖3以自組織徑向基神經網絡為例,對本發明的技術方案進行詳細說明:
參照圖3,根據本發明的一個實施例的基于自組織徑向基神經網絡的血壓預測方法,包括如下步驟:
步驟S302,確定自組織徑向基神經網絡模型的輸入輸出變量。
具體地,將M組歷史數據作為模型輸入,第M+1作為輸出變量,在實際應用中M為間隔固定時間取得的數據,如每隔1小時取一個血壓數據,前M個作為輸入,第M+1作為輸出。在本發明的示例性實施例中,可以取6個歷史血壓數據作為輸入,即自組織徑向基神經網絡的 模型為6輸入,1輸出。
步驟S304,設計用于人體血壓預測的自組織徑向基神經網絡拓撲結構。
具體參照圖4所示,自組織徑向基神經網絡包括:輸入層、隱含層、輸出層;初始化徑向基神經網絡:確定神經網絡M-K-1的連接方式,即輸入層神經元為M個,隱含層神經元為K個,K為正整數,輸出層神經元為1個;對神經網絡的參數進行賦值;設共有T組訓練樣本,若每組訓練樣本包含6個數據,則第t時刻神經網絡輸入為x(t)=[x1(t),x2(t),x3(t),x4(t),x5(t),x6(t)],神經網絡的期望輸出表示為yd(t),實際輸出表示為y(t);徑向基神經網絡的計算功能是:
其中,wk(t)表示隱含層第k個神經元和輸出層的連接權值,k=1,2,…,K;φk(x(t))表示隱含層第k個神經元的輸出,其計算公式為:
其中,μk表示隱含層第k個神經元中心值,σk表示隱含層第k個神經元的中心寬度。
步驟S306,訓練神經網絡,具體包括:
①初始化粒子群加速常數c1和c2,c1∈(0,1),c2∈(0,1);設定粒子群平衡權值α∈[0,1],將徑向基神經網絡的參數表示為粒子群中的粒子:
其中,ai表示第i個粒子的位置,i=1,2,…,s;s表示粒子總個數,s為正整數,μi,k,σi,k和wi,k分別表示第i個粒子中第k個隱含層神經元的中心值,中心寬度和連接權值;Ki表示第i個粒子表示的徑向基神經網絡隱含層神經元數;μi,k,σi,k和wi,k的初始值取(0,1)的任意數,Ki的初始值為任意正整數;同時,初始化粒子的速度:
其中,vi表示第i個粒子的速度,Di表示第i個粒子的維數,Di=3Ki。
②對于神經網絡的輸入x(t),確定每個粒子的維數Di(t)=3Ki(t),計 算每個粒子的適應度值:
其中,i=1,2,…,s;T表示神經網絡輸入的訓練樣本數。
③計算每個粒子的慣性權重:
ωi(t)=S(t)tAi(t) (6)
其中:
S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t)) (7)
fmin(a(t))、fmax(a(t))分別為當前時刻最小適應度值和最大適應度值,粒子全局最優位置g(t)分別表示為:
其中,粒子本身的歷史最優位置pi(t)表示為:
④更新每個粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t) (10)
其中,r1和r2分別表示個體歷史最優系數和全局最優位置系數,r1和r2取[0,1]的任意數。
⑤根據全局最優位置g(t)找出最優網絡結構,此時的最優神經網絡隱含層神經元數為Kbest,并根據每個粒子神經元數與最優粒子神經元數的差異,更新每個粒子對應的神經網絡隱含層神經元數:
⑥輸入訓練樣本數據x(t+1),重復步驟②-⑤,直到滿足預定的精度要求或者滿足迭代次數之后停止計算。
當停止計算之后,可以得到最優的自組織神經網絡的結構,進而可以基于最優的自組織神經網絡的結構來進行血壓預測。
根據本發明的示例性實施例,可以基于智能手環來采集用戶的血壓數據。自組織徑向基神經網絡能夠通過歷史血壓數據進行學習,調整神經網絡的結構及參數,進而能夠提前預知血壓值,比如,可以根據智能 手環實時采集的最近6小時的6組血壓數據(此處僅為示例,并不作具體限定),通過自組織徑向基神經網絡進行在線預測未來一小時的血壓值,進而將預測的血壓值作為血壓參考,讓醫生及患者提前了解血壓變化,從而提前采取相應預防措施,對于健康管理和疾病治療具有極大意義。
圖5示意性示出了根據本發明的一個實施例的血壓預測的裝置的框圖。
參照圖5,根據本發明的一個實施例的血壓預測的裝置500,包括:配置單元502、訓練處理單元504和預測處理單元506。
具體地,配置單元502用于配置用于進行血壓預測的神經網絡;訓練處理單元504用于基于預設的多組訓練樣本對所述神經網絡進行訓練,得到訓練后的神經網絡;預測處理單元506用于根據訓練后的神經網絡,對人體的血壓數據進行預測。
其中,神經網絡可以是自組織徑向基神經網絡,也可以是前饋神經網絡,還可以是其它神經網絡。
根據本發明的示例性實施例,可以通過下述方法確定多組訓練樣本:采集用戶的多個血壓數據;基于所述多個血壓數據,形成所述多組訓練樣本,其中,每組訓練樣本包含M+1個血壓數據,所述M+1個血壓數據中按照采集順序的前M個血壓數據作為所述每組訓練樣本的輸入參數,第M+1個血壓數據作為所述每組訓練樣本的輸出參數。
根據本發明的示例性實施例,可以基于預定時間間隔采集所述用戶的多個血壓數據。比如可以每隔1小時采集用戶的一個血壓數據。
根據本發明的示例性實施例,所述神經網絡包括:M個輸入層神經元、K個隱含層神經元和1個輸出層神經元。
根據本發明的示例性實施例,通過以下公式計算所述神經網絡的輸出:
其中,y(t)表示所述神經網絡的實際輸出;wk(t)表示所述隱含層神經元中第k個神經元和所述輸出層神經元的連接權值,k=1,2,…,K;φk(x(t))表示所述隱含層神經元中的第k個神經元的輸出,具體可基 于以下公式計算所述φk(x(t))的值:
其中,μk表示所述隱含層神經元中的第k個神經元的中心值,σk表示所述隱含層神經元中的第k個神經元的中心寬度。
根據本發明的示例性實施例,訓練處理單元504配置為:將所述神經網絡中的參數表示為粒子群中的粒子,并初始化粒子群;通過所述預設的多組訓練樣本對所述粒子群進行迭代優化,直至滿足迭代終止條件。
根據本發明的示例性實施例,對所述粒子群進行迭代優化時的任一次優化過程,包括:
計算所述粒子群中每個粒子的適應度值;
根據所述每個粒子的適應度值,確定所述每個粒子的歷史最優位置和全局最優位置;
基于所述每個粒子的歷史最優位置和全局最優位置,更新所述每個粒子的位置和速度;
基于所述每個粒子的全局最優位置,確定所述神經網絡的最優網絡結構,以更新所述每個粒子對應的隱含層神經元的個數。
根據本發明的示例性實施例,通過以下公式將所述神經網絡中的參數表示為粒子群中的粒子:
其中,ai表示第i個粒子的位置,i=1,2,…,s;s表示粒子群中的粒子總個數,s為正整數;μi,k、σi,k和wi,k分別表示第i個粒子的第k個隱含層神經元的中心值、中心寬度和連接權值;Ki表示第i個粒子表示的神經網絡的隱含層神經元數;μi,k、σi,k和wi,k的初始值取(0,1)中的任意數,Ki的初始值為任意正整數。
根據本發明的示例性實施例,初始化粒子群,包括:
初始化粒子群加速常數c1和c2,c1∈(0,1),c2∈(0,1);
設定粒子群平衡權值α∈[0,1];
初始化粒子的速度:其中,vi表示第i個粒子的速度,Di表示第i個粒子的維數,Di=3Ki。
根據本發明的示例性實施例,通過以下公式計算所述粒子群中每個 粒子的適應度值:
其中,f(ai(t))表示所述每個粒子的適應度值;i=1,2,…,s;s表示粒子群中的粒子總個數,s為正整數;T表示所述預設的訓練樣本的個數;y(t)表示所述神經網絡的實際輸出;yd(t)表示所述神經網絡的期望輸出。
根據本發明的示例性實施例,根據所述每個粒子的適應度值,確定所述每個粒子的歷史最優位置和全局最優位置,包括:
計算所述每個粒子的慣性權重:ωi(t)=S(t)tAi(t);
其中,t表示對所述粒子群進行迭代優化的次數;S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t));fmin(a(t))、fmax(a(t))分別表示當前時刻的最小適應度值和最大適應度值,g(t)表示粒子全局最優位置,且fmin(a(t))、fmax(a(t))和g(t)分別表示為:
其中,每個粒子的歷史最優位置pi(t)通過以下公式表示:
根據本發明的示例性實施例,通過以下公式更新所述每個粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t);
其中,r1和r2分別表示每個粒子的歷史最優位置系數和全局最優位置系數,r1和r2取[0,1]中的任意數。
根據本發明的示例性實施例,通過以下公式更新所述每個粒子對應的隱含層神經元的個數:
其中,Ki(t)表示更新后的所述每個粒子對應的隱含層神經元的個數;Ki(t-1)表示更新前的所述每個粒子對應的隱含層神經元的個數;Kbest表示所述神經網絡的最優網絡結構的隱含層神經元個數。
根據本發明的示例性實施例,預測處理單元506配置為:將檢測到的用戶的若干個血壓數據作為訓練后的神經網絡的輸入,并將訓練后的神經網絡的輸出作為預測到的血壓數據。
基于本發明上述實施例的技術方案,可以實現人體血壓的在線預測,進而能夠使用戶提前了解未來的血壓變化,從而采取相應的干預措施,具有較大的健康管理價值;同時,提前預測血壓也可作為醫務人員治療的參考,為搶救贏取時間,具有較大的醫療價值。
應當注意,盡管在上文詳細描述中提及了用于動作執行的設備的若干模塊或者單元,但是這種劃分并非強制性的。實際上,根據本發明的實施方式,上文描述的兩個或更多模塊或者單元的特征和功能可以在一個模塊或者單元中具體化。反之,上文描述的一個模塊或者單元的特征和功能可以進一步劃分為由多個模塊或者單元來具體化。
通過以上的實施方式的描述,本領域的技術人員易于理解,這里描述的示例實施方式可以通過軟件實現,也可以通過軟件結合必要的硬件的方式來實現。因此,根據本發明實施方式的技術方案可以以軟件產品的形式體現出來,該軟件產品可以存儲在一個非易失性存儲介質(可以是CD-ROM,U盤,移動硬盤等)中或網絡上,包括若干指令以使得一臺計算設備(可以是個人計算機、服務器、觸控終端、或者網絡設備等)執行根據本發明實施方式的方法。
本領域技術人員在考慮說明書及實踐這里公開的發明后,將容易想到本發明的其它實施方案。本申請旨在涵蓋本發明的任何變型、用途或者適應性變化,這些變型、用途或者適應性變化遵循本發明的一般性原理并包括本發明未公開的本技術領域中的公知常識或慣用技術手段。說明書和實施例僅被視為示例性的,本發明的真正范圍和精神由下面的權利要求指出。
應當理解的是,本發明并不局限于上面已經描述并在附圖中示出的精確結構,并且可以在不脫離其范圍進行各種修改和改變。本發明的范圍僅由所附的權利要求來限制。
- 還沒有人留言評論。精彩留言會獲得點贊!