視頻生成方法、裝置、電子設備、存儲介質及產品與流程
本申請涉及視頻剪輯,尤其涉及視頻生成方法、裝置、電子設備、存儲介質及產品。
背景技術:
1、傳統的視頻生成不僅需要創作者自行撰寫文案、拍攝并收集素材,還需進行復雜的圖像處理,如摳圖與背景融合,以及插入個人素材、調整音量與添加字幕等步驟。這一系列操作耗時費力,即便對于經驗豐富的創作者而言,完成一個視頻生成作品也往往需要數小時乃至一兩天的時間,極大地降低了創作效率。此外,傳統視頻生成在制作風格上亦顯得較為單一,所產出的視頻往往要么全程采用空鏡風格,缺乏實質性內容;要么則完全依賴于真人或數字人的口播形式,視覺效果與信息傳遞方式均較為單調,難以充分調動觀眾的觀看興趣。因此,這類視頻不僅給予觀眾的體驗感受相對乏味,而且在信息承載量上也存在明顯的局限性,難以滿足現代多媒體環境下對豐富、多元內容的需求。
2、綜上,如何簡化視頻生成的操作流程并提升視頻表現力,儼然已成為本領域亟需解決的技術問題。
技術實現思路
1、本申請的主要目的在于提供一種視頻生成方法、裝置、電子設備、存儲介質及產品,旨在簡化視頻生成的操作流程并提升視頻表現力。
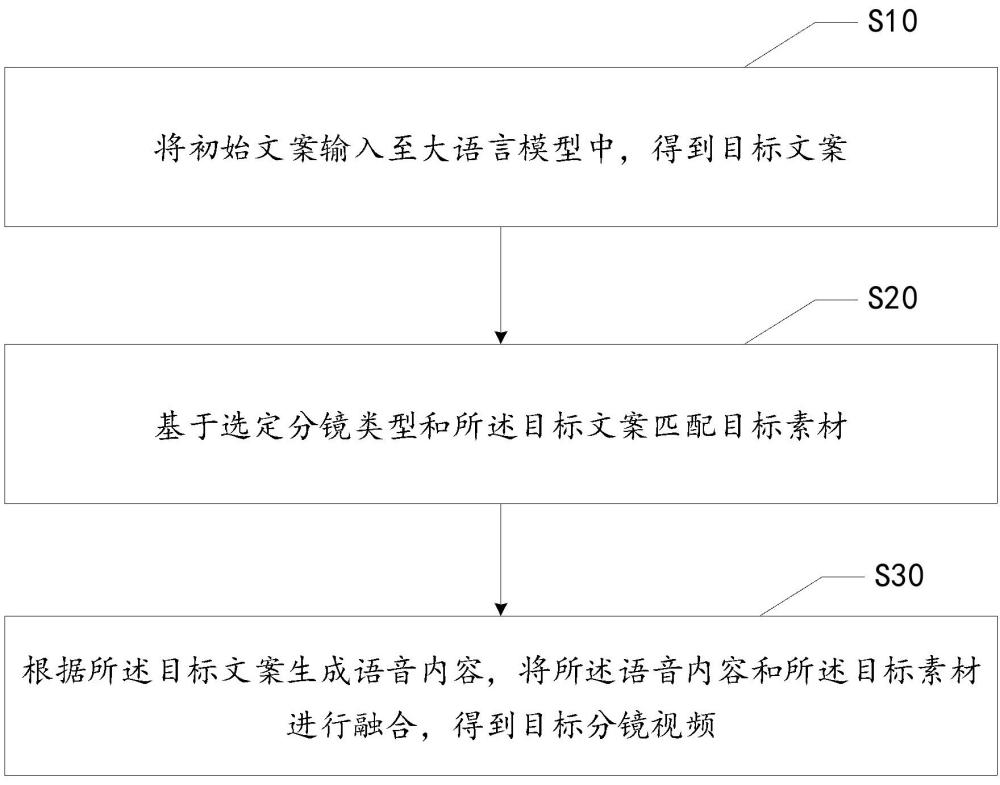
2、為實現上述目的,本申請提出一種視頻生成方法,視頻生成方法包括:
3、將初始文案輸入至大語言模型中,得到目標文案;
4、基于選定分鏡類型和所述目標文案匹配目標素材;
5、根據所述目標文案生成語音內容,將所述語音內容和所述目標素材進行融合,得到目標分鏡視頻。
6、在一實施例中,所述基于選定分鏡類型和所述目標文案匹配目標素材的步驟,包括:
7、在選定分鏡類型為空鏡類型時,通過素材匹配算法從預設的素材庫中查找所述目標文案匹配的初始目標素材;
8、通過視頻畫面混淆算法對所述初始目標素材進行混淆處理,得到目標素材。
9、在一實施例中,所述通過素材匹配算法從預設的素材庫中查找所述目標文案匹配的初始目標素材的步驟,包括:
10、通過所述素材匹配算法對預設的素材庫中各素材分別進行向量化處理,得到各素材向量;
11、對所述目標文案進行向量化操作,得到文案向量;
12、依次計算所述文案向量與各所述素材向量之間的相似度值,將相似度值最高的素材確定為與所述目標文案匹配的初始目標素材。
13、在一實施例中,所述基于選定分鏡類型和所述目標文案匹配目標素材的步驟還包括:
14、在選定分鏡類型為數字人口播類型時,根據預設的數字人形象設定生成初始目標素材,其中,所述初始目標素材包括初始數字人模型和數字人背景畫面;
15、根據所述目標文案的文本內容對所述初始數字人模型進行狀態調整,以及對所述數字人背景畫面進行畫面渲染處理,得到所述目標文案匹配的目標素材。
16、在一實施例中,所述根據所述目標文案生成語音內容,將所述語音和所述目標素材進行融合,得到分鏡視頻的步驟之后,所述方法還包括:
17、生成包含所述目標分鏡視頻在內的各分鏡視頻后,通過視頻轉場特效算法連接各所述分鏡視頻,得到初始目標視頻;
18、根據各所述分鏡視頻各自的語音內容為所述初始目標視頻添加字幕和視頻配樂,得到目標視頻。
19、在一實施例中,所述通過視頻轉場特效算法連接各所述分鏡視頻,得到初始目標視頻的步驟之前,還包括:
20、確定各所述分鏡視頻各自的視頻規格,其中,所述視頻規格包括分辨率、幀率、編碼格式、色調和尺寸;
21、對各所述分鏡視頻的參數進行調整,以使各所述分鏡視頻的視頻規格一致,得到調整后的各分鏡視頻;
22、所述通過視頻轉場特效算法連接各所述分鏡視頻,得到初始目標視頻的步驟,包括:
23、通過視頻轉場特效算法連接各調整后的分鏡視頻,得到初始目標視頻。
24、此外,為實現上述目的,本申請還提出一種視頻生成裝置,所述裝置包括:
25、文案生成模塊,用于將初始文案輸入至大語言模型中,得到目標文案;
26、素材匹配模塊,用于基于選定分鏡類型和所述目標文案匹配目標素材;
27、視頻生成模塊,用于根據所述目標文案生成語音內容,將所述語音內容和所述目標素材進行融合,得到目標分鏡視頻。
28、此外,為實現上述目的,本申請還提出一種電子設備,電子設備包括:存儲器、處理器及存儲在存儲器上并可在處理器上運行的計算機程序,計算機程序配置為實現如上文的視頻生成方法的步驟。
29、此外,為實現上述目的,本申請還提出一種存儲介質,存儲介質為計算機可讀存儲介質,存儲介質上存儲有計算機程序,計算機程序被處理器執行時實現如上文的視頻生成方法的步驟。
30、此外,為實現上述目的,本申請還提供一種計算機程序產品,計算機程序產品包括計算機程序,計算機程序被處理器執行時實現如上文的視頻生成方法的步驟。
31、本申請提出了一種視頻生成方法,本申請首先利用大語言模型技術,將用戶輸入的初始文案自動轉化為更具吸引力和邏輯性的目標文案,隨后,基于視頻創作者選定的分鏡類型與生成的目標文案自動匹配素材資源,在獲得目標文案與目標素材后,自動生成與目標文案和目標素材對應的語音內容,并將語音內容與目標素材進行融合,生成目標分鏡視頻。
32、綜上可知,本申請通過引入大語言模型實現了視頻文案的自動生成,通過智能匹配技術實現了文案與素材的自動匹配,且匹配的素材可根據視頻創作者選定的分鏡類型進行調整,同時,將語音內容與目標素材的融合過程自動化,如此,通過智能匹配多樣化的素材與自動生成的語音內容,既縮短了視頻制作周期,也使得視頻內容更加豐富多元,有效避免了內容的單調性,增強整體的觀看體驗,實現了簡化視頻生成的操作流程并提升視頻表現力的效果。
技術特征:
1.一種視頻生成方法,其特征在于,所述方法包括:
2.如權利要求1所述的視頻生成方法,其特征在于,所述基于選定分鏡類型和所述目標文案匹配目標素材的步驟,包括:
3.如權利要求2所述的視頻生成方法,其特征在于,所述通過素材匹配算法從預設的素材庫中查找所述目標文案匹配的初始目標素材的步驟,包括:
4.如權利要求1所述的視頻生成方法,其特征在于,所述基于選定分鏡類型和所述目標文案匹配目標素材的步驟還包括:
5.如權利要求1所述的視頻生成方法,其特征在于,所述根據所述目標文案生成語音內容,將所述語音和所述目標素材進行融合,得到分鏡視頻的步驟之后,所述方法還包括:
6.如權利要求5所述的視頻生成方法,其特征在于,所述通過視頻轉場特效算法連接各所述分鏡視頻,得到初始目標視頻的步驟之前,還包括:
7.一種視頻生成裝置,其特征在于,所述裝置包括:
8.一種電子設備,其特征在于,所述電子設備包括:存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的計算機程序,所述計算機程序配置為實現如權利要求1至6中任一項所述的視頻生成方法的步驟。
9.一種存儲介質,其特征在于,所述存儲介質為計算機可讀存儲介質,所述存儲介質上存儲有計算機程序,所述計算機程序被處理器執行時實現如權利要求1至6中任一項所述的視頻生成方法的步驟。
10.一種計算機程序產品,其特征在于,所述計算機程序產品包括計算機程序,所述計算機程序被處理器執行時實現如權利要求1至6中任一項所述的視頻生成方法的步驟。
技術總結
本申請公開了一種視頻生成方法、裝置、電子設備、存儲介質及產品,涉及視頻剪輯技術領域,方法包括:將初始文案輸入至大語言模型中,得到目標文案;基于選定分鏡類型和所述目標文案匹配目標素材;根據所述目標文案生成語音內容,將所述語音內容和所述目標素材進行融合,得到目標分鏡視頻。本申請能夠簡化視頻生成的操作流程并提升視頻表現力。
技術研發人員:吳天,譚領城
受保護的技術使用者:深圳市明源云科技有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!