視頻切片方法和裝置、電子設備及存儲介質與流程
本申請涉及人工智能,尤其涉及一種視頻切片方法和裝置、電子設備及存儲介質。
背景技術:
1、在人工智能視頻處理算法中,通常將一段視頻輸入到神經網絡中,神經網絡對視頻進行拆幀,基于幀內的信息及幀間的區別,提取特征進行回歸計算,得到神經網絡的分析結果。通常情況下,送入神經網絡的視頻時長越長,神經網絡的處理時間越長。為了保證神經網絡結果的時效性,通常需要限制視頻的時長。目前的視頻處理算法中,常用的視頻截取及切片方法有兩種:
2、(1)指定開始時間和結束時間,使用重新編碼進行視頻提取;
3、切片過程中,嚴格從開始時間到結束時間,需要對視頻重新進行h264編碼,并根據需要插入i幀信息,以實現精準剪裁。
4、這種方法可以精準切割,但是過程中編碼需要耗費大量的時間和資源。
5、(2)使用復制方法,無需解碼實現快速剪切;
6、在視頻時間搜索過程中,搜索操作會在i幀之間跳轉,不會準確停止在i幀處。由于沒有進行重新編碼,在達到第一個i幀之前,視頻播放會出現問題。
技術實現思路
1、本申請實施例的主要目的在于提出一種視頻切片方法和裝置、電子設備及存儲介質,能夠既可以將視頻切割成期望的長度,保證算法的實時性,又可以有效保存視頻中的信息,且不需要對視頻進行解碼再編碼,從而節省大量的計算量,加快處理速度。
2、為實現上述目的,本申請實施例的第一方面提出了一種視頻切片方法,所述方法包括:
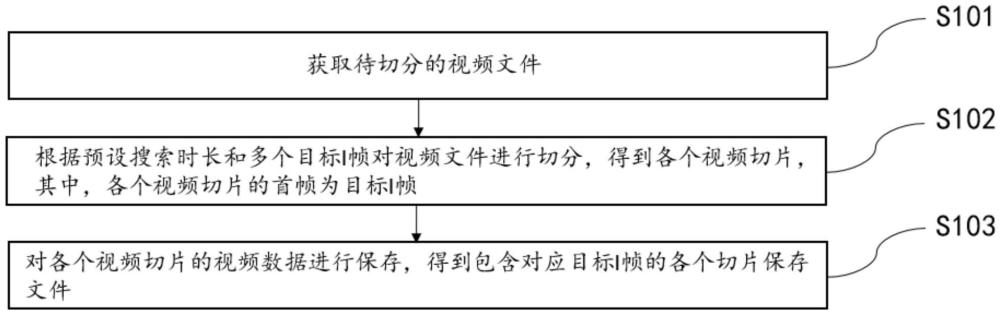
3、獲取待切分的視頻文件;
4、根據預設搜索時長和多個目標i幀對所述視頻文件進行切分,得到各個視頻切片,其中,各個所述視頻切片的首幀為所述目標i幀;
5、對各個視頻切片的視頻數據進行保存,得到包含對應所述目標i幀的各個切片保存文件。
6、在一些實施例,所述根據預設搜索時長和多個目標i幀對所述視頻文件進行切分,得到各個視頻切片,包括:
7、從視頻文件的第一幀開始對所述視頻文件的各個視頻幀進行搜索,讀取各個所述視頻幀距離所述第一幀的間隔時長,所述第一幀為i幀;
8、遍歷所述視頻文件的各個視頻幀,在預設搜索時長內確定各個目標i幀;
9、根據所述預設搜索時長、所述間隔時長和目標i幀對所述視頻文件進行切分,得到各個視頻切片。
10、在一些實施例,所述根據所述預設時長、所述間隔時長和目標i幀對所述視頻文件進行切分,得到各個視頻切片,包括:
11、根據所述預設時長和所述間隔時長確定距離上一所述目標i幀最近的下一所述目標i幀;
12、將上一所述目標i幀至下一所述目標i幀之前的視頻幀寫入至對應的切片保存文件;
13、遍歷所述視頻文件的各個視頻幀進行切分,直至所述視頻文件的最后一幀,得到各個視頻切片。
14、在一些實施例,所述根據所述預設時長和所述間隔時長確定距離上一所述目標i幀最近的下一所述目標i幀,包括:
15、確定距離上一所述目標i幀不同所述間隔時長內的視頻幀;
16、在所述預設時長內從所述視頻幀中搜索出下一所述目標i幀。
17、在一些實施例,所述在所述預設時長內從所述視頻幀中搜索出下一所述目標i幀,包括:
18、在所述預設時長內對所述視頻幀的標識位進行識別,得到識別結果;
19、在所述識別結果為av_pkt_flag_key的情況下,確定所述視頻幀為下一所述目標i幀。
20、在一些實施例,所述對各個視頻切片的視頻數據進行保存,得到包含對應所述目標i幀的各個切片保存文件,包括:
21、新建多個切片保存文件;
22、拷貝已切分的各個所述視頻切片;
23、將各個視頻切片的視頻數據寫入至對應的切片保存文件,得到包含對應所述目標i幀的各個切片保存文件。
24、在一些實施例,所述視頻文件包括多個gop圖像組,每個所述gop圖像組包括一個i幀、至少一個p幀和至少一個b幀。
25、為實現上述目的,本申請實施例的第二方面提出了一種視頻切片裝置,所述裝置包括:
26、獲取模塊,用于獲取待切分的視頻文件;
27、切片模塊,用于根據預設搜索時長和目標i幀對所述視頻文件進行切分,得到各個視頻切片,其中,各個所述視頻切片的首幀為所述目標i幀;
28、保存模塊,用于對各個視頻切片的視頻數據進行保存,得到包含對應所述目標i幀的各個切片保存文件。
29、為實現上述目的,本申請實施例的第三方面提出了一種電子設備,所述電子設備包括存儲器和處理器,所述存儲器存儲有計算機程序,所述處理器執行所述計算機程序時實現上述第一方面所述的方法。
30、為實現上述目的,本申請實施例的第四方面提出了一種計算機可讀存儲介質,所述計算機可讀存儲介質存儲有計算機程序,所述計算機程序被處理器執行時實現上述第一方面所述的方法。
31、本申請提出的視頻切片方法和裝置、電子設備及存儲介質,獲取待切分的視頻文件;根據預設搜索時長和多個目標i幀對視頻文件進行切分,得到各個視頻切片,其中,各個所述視頻切片的首幀為所述目標i幀;對各個視頻切片的視頻數據進行保存,得到包含對應目標i幀的各個切片保存文件。用戶可以根據期望的視頻切分長度對預設搜索時長進行設置,在預設搜索時長內對待切分的視頻文件進行視頻幀搜索,并基于搜索到的目標i幀對視頻文件進行切分,得到的是首幀為目標i幀的各個視頻切片,因此,得到的各個視頻切片包含有目標i幀信息,基于i幀可以完整地對后續視頻幀數據進行解碼,提取到視頻幀的信息,不需要對視頻數據進行解碼再編碼,節省大量的計算量,從而加快處理速度。基于此,本發明實施例既可以將視頻切分成期望的長度,保證視頻切分處理的實時性,又可以有效保存視頻中的信息,且不需要對視頻進行解碼再編碼,從而節省大量的計算量,加快處理速度,尤其在人工智能視頻處理領域,由于各個視頻切片中i幀保留齊全,切割后的視頻幀內容可以完整復原,不會丟失信息,因此非常適合人工智能視頻算法處理。整個視頻切分過程不涉及到任何視頻幀內的信息提取和運算,僅僅是切分后快速地拷貝并保存。視頻切分后不需要進行視頻重新編碼,節省處理時間及資源消耗,從而加快視頻切片處理速度。
技術特征:
1.一種視頻切片方法,其特征在于,所述方法包括:
2.根據權利要求1所述的方法,其特征在于,所述根據預設搜索時長和多個目標i幀對所述視頻文件進行切分,得到各個視頻切片,包括:
3.根據權利要求2所述的方法,其特征在于,所述根據所述預設時長、所述間隔時長和目標i幀對所述視頻文件進行切分,得到各個視頻切片,包括:
4.根據權利要求3所述的方法,其特征在于,所述根據所述預設時長和所述間隔時長確定距離上一所述目標i幀最近的下一所述目標i幀,包括:
5.根據權利要求4所述的方法,其特征在于,所述在所述預設時長內從所述視頻幀中搜索出下一所述目標i幀,包括:
6.根據權利要求1所述的方法,其特征在于,所述對各個視頻切片的視頻數據進行保存,得到包含對應所述目標i幀的各個切片保存文件,包括:
7.根據權利要求1至6任意一項所述的方法,其特征在于,所述視頻文件包括多個gop圖像組,每個所述gop圖像組包括一個i幀、至少一個p幀和至少一個b幀。
8.一種視頻切片裝置,其特征在于,所述裝置包括:
9.一種電子設備,其特征在于,所述電子設備包括存儲器和處理器,所述存儲器存儲有計算機程序,所述處理器執行所述計算機程序時實現權利要求1至7任一項所述的視頻切片方法。
10.一種計算機可讀存儲介質,所述計算機可讀存儲介質存儲有計算機程序,其特征在于,所述計算機程序被處理器執行時實現權利要求1至7中任一項所述的視頻切片方法。
技術總結
本申請實施例提供了一種視頻切片方法和裝置、電子設備及存儲介質,屬于人工智能技術領域。該方法包括:獲取待切分的視頻文件;根據預設搜索時長和多個目標I幀對視頻文件進行切分,得到各個視頻切片,其中,各個視頻切片的首幀為目標I幀;對各個視頻切片的視頻數據進行保存,得到包含對應目標I幀的各個切片保存文件。基于此,本申請實施例既可以將視頻切分成期望的長度,保證視頻切分處理的實時性,又可以有效保存視頻中的信息,且不需要對視頻進行解碼再編碼,從而節省大量的計算量,加快處理速度,尤其在人工智能視頻處理領域,由于各個視頻切片中I幀保留齊全,切分后的視頻幀內容可以完整復原,不會丟失信息,節省處理時間及資源消耗。
技術研發人員:郭倜穎,劉偉超
受保護的技術使用者:平安科技(深圳)有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!