一種面向自然場景的文本檢測方法
本發明涉及深度學習圖像文本檢測,具體涉及一種面向自然場景的文本檢測方法。
背景技術:
1、在自然場景中,背景復雜且多變,有效地從圖像中分割出文本對象和定位文本位置,成為人們關注的問題。在2012年之前,文本分割與定位技術主要依賴于傳統圖像處理技術和統計機器學習方法。這些技術通過圖像預處理(如灰度化、二值化、傾斜檢測與校正等)、特征提取(如hog特征等)和機器學習分類器(如svm等)來實現文本的檢測與識別。然而,這種方法在不同場景下需要獨立設計各個模塊的參數,工作繁瑣,且難以設計出泛化性能好的模型。自2012年起,隨著深度學習在計算機視覺領域的廣泛應用,文本分割與定位技術逐漸過渡到深度學習算法方案。深度學習算法通過自動學習圖像特征,大大簡化了傳統方法中的復雜流程,并提高了文本分割與定位的準確性和效率。
2、然而現有技術在骨干網絡特征提取時,仍然因為特征丟失的問題導致文本檢測網絡的檢測精度不足。
技術實現思路
1、本發明的目的在于提供一種面向自然場景的文本檢測方法,旨在改進有效注意力網絡,把可微分二值化算法和注意力機制應用到文本檢測中,解決文本檢測時特征丟失的問題,并提高文本檢測網絡的檢測精度。
2、為實現上述目的,本發明提供了一種面向自然場景的文本檢測方法,包括下列步驟:
3、步驟1:選定訓練集和測試集;
4、步驟2:將訓練集作為文本檢測網絡的輸入,所述文本檢測網絡包括backbone、neck和head三個部分;
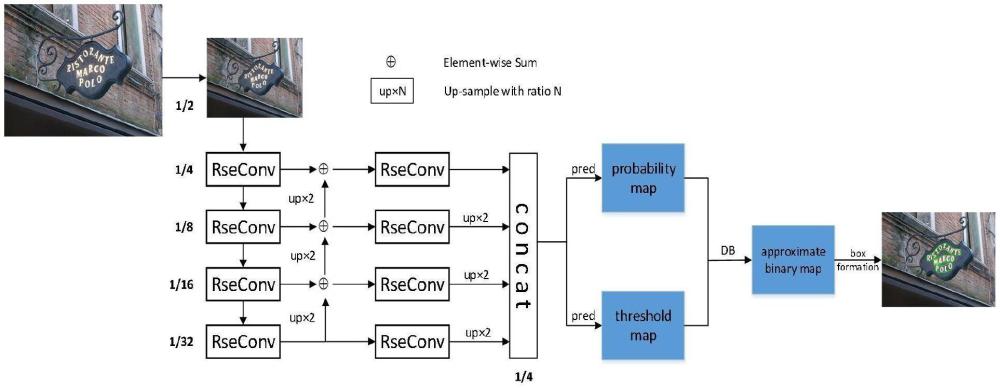
5、步驟3:基于改進的resnet50在backbone部分進行特征提取,對輸入圖片進行下采樣,得到不同的四個尺度特征圖;
6、步驟4:將四個尺度特征圖輸入到neck部分的rse-fpn進行特征融合,融合后的特征圖經過上采樣和特征級聯得到最終特征圖;
7、步驟5:將最終特征圖經過預測得到概率圖和閾值圖;
8、步驟6:在head部分運用可微分二值化算法計算概率圖和閾值圖得到近似二值化圖,對近似二值化圖進行文本框操作輸出帶文本框的最終圖片。
9、可選的,步驟3中改進的resnet50具體為將resnet?bottleneck用eanet?block結構替換,eanet?block結構psa模塊、csa模塊和兩個1*1卷積構成,其中psa模塊主要是對輸入圖片進行多尺度特征提取,csa模塊則是關注通道信息豐富特征信息。
10、可選的,步驟4中neck部分的rse-fpn中的卷積層用se模塊的殘差結構替代。se模塊可以增強網絡中不同通道之間的關注度。殘差連接可以解決深層網絡中梯度消失和梯度爆炸等問題。將se模塊與殘差連接結合起來,可以進一步提高網絡的性能。
11、可選的,步驟6中可微分二值化算法計算公式為;
12、
13、其中,表示近似二值映射;p表示由分割網絡生成的概率圖;t表示從網絡中學習到的自適應閾值映射;k表示放大因子;(i,j)表示圖中的坐標點。
14、可選的,所述面向自然場景的文本檢測方法采用l1損失函數和二進制交叉熵損失函數對網絡進行優化,損失函數的表達式為:
15、l=ls+α×lb+β×lt
16、其中ls為概率圖的損失,lb為二值圖的損失,lt為閾值圖的損失,其中α和β分別設置1和10;
17、使用二進制交叉熵損失來計算ls和lb:
18、
19、其中st表示正樣本與負樣本比例為1:3的抽樣集;
20、lt使用l1損失函數:
21、
22、其中yi*表示閾值圖的標簽,rd表示gd中的所有像素。
23、本發明提供了一種面向自然場景的文本檢測方法,基于backbone、neck和head三個部分改進獲得文本檢測網絡,再將訓練集輸入文本檢測網絡進行迭代訓練,獲得最終結果。具體為在骨干網絡特征提取時,使用eanetblock結構替換resnet?bottleneck,通過eanet包含的psa模塊和csa模塊,多尺度的提取特征信息和關注空間信息,有效地保留有效信息從而提高檢測精度;同時還引入se模塊和殘余結構增強網絡對文本信息的定位;最后可微分二值化算法和注意力機制應用到文本檢測中,解決了文本檢測時特征丟失的問題,并提高了文本檢測網絡的檢測精度。
技術特征:
1.一種面向自然場景的文本檢測方法,其特征在于,包括下列步驟:
2.如權利要求1所述的面向自然場景的文本檢測方法,其特征在于,
3.如權利要求2所述的面向自然場景的文本檢測方法,其特征在于,
4.如權利要求3所述的面向自然場景的文本檢測方法,其特征在于,
5.如權利要求4所述的面向自然場景的文本檢測方法,其特征在于,
技術總結
本發明涉及深度學習圖像文本檢測技術領域,具體涉及一種面向自然場景的文本檢測方法,基于backbone、neck和head三個部分改進獲得文本檢測網絡,再將訓練集輸入文本檢測網絡進行迭代訓練,獲得最終結果。具體為在骨干網絡特征提取時,使用EANet?block結構替換ResNet?Bottleneck,通過EANet包含的PSA模塊和CSA模塊,多尺度的提取特征信息和關注空間信息,有效地保留有效信息從而提高檢測精度;同時還引入SE模塊和殘余結構增強網絡對文本信息的定位;最后可微分二值化算法和注意力機制應用到文本檢測中,解決了文本檢測時特征丟失的問題,并提高了文本檢測網絡的檢測精度。
技術研發人員:黎海生,黎秋儀
受保護的技術使用者:廣西師范大學
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!