可解決災難性遺忘的文本預測方法、相關裝置及存儲介質與流程
本發明涉及人工智能,尤其涉及一種可解決災難性遺忘的文本預測方法、相關裝置及存儲介質。
背景技術:
1、深度學習中的“災難性”遺忘(catastrophic?forgetting)是一個在連續學習或增量學習過程中出現的問題,具體是指深度學習網絡在學習了新的目標任務之后,如果沒有再次學習以前的通用任務的數據,深度學習網絡往往會逐步忘記以前已學習過的知識,從而使導致在目標任務上表現良好,但在通用任務上的性能顯著下降。
2、在現有技術中,在嘗試讓預訓練的語言模型適應目標任務而進行微調時,為了適應新的文本數據集或目標任務,語言模型的參數會相應調整,如果目標任務的數據量較小或與通用任務的差異較大,語言模型可能會過度調整到目標任務上,導致忘記先前學習的知識,從而出現對通用任務遺忘的情況發生。
技術實現思路
1、本發明的目的是提供一種可解決災難性遺忘的文本預測方法、相關裝置及存儲介質,旨在解決現有技術中對語言模型進行微調時出現的對通用任務遺忘的問題。
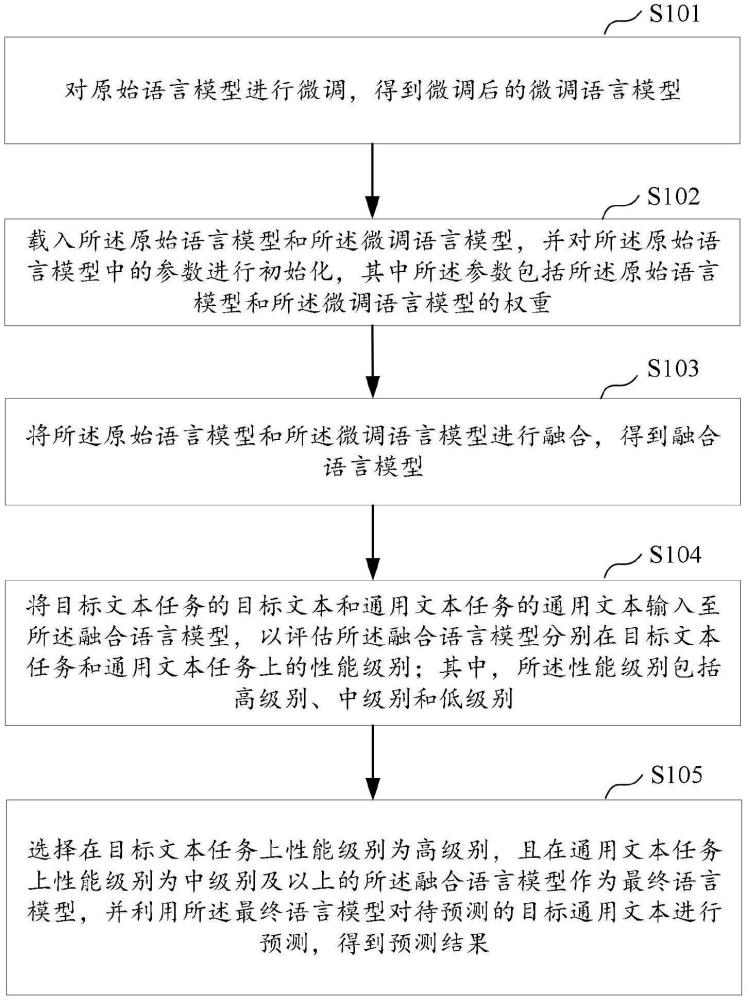
2、第一方面,本發明實施例提供一種可解決大模型災難性遺忘的文本預測方法,包括:
3、對原始語言模型進行微調,得到微調后的微調語言模型;
4、載入所述原始語言模型和所述微調語言模型,并對所述原始語言模型中的參數進行初始化,其中所述參數包括所述原始語言模型和所述微調語言模型的權重;
5、將所述原始語言模型和所述微調語言模型進行融合,得到融合語言模型;
6、將目標文本任務的目標文本和通用文本任務的通用文本輸入至所述融合語言模型,以評估所述融合語言模型分別在目標文本任務和通用文本任務上的性能級別;其中,所述性能級別包括高級別、中級別和低級別;
7、選擇在目標文本任務上性能級別為高級別,且在通用文本任務上性能級別為中級別及以上的所述融合語言模型作為最終語言模型,并利用所述最終語言模型對待預測的目標通用文本進行預測,得到預測結果。
8、第二方面,本發明實施例還提供一種可解決大模型災難性遺忘的文本預測的裝置,其包括:
9、微調單元,用于對原始語言模型進行微調,得到微調后的微調語言模型;
10、初始化參數單元,用于載入所述原始語言模型和所述微調語言模型,并對所述原始語言模型中的參數進行初始化,其中所述參數包括所述原始語言模型和所述微調語言模型的權重;
11、融合單元,用于將所述原始語言模型和所述微調語言模型進行融合,得到融合語言模型;
12、評估單元,用于將目標文本任務的目標文本和通用文本任務的通用文本輸入至所述融合語言模型,以評估所述融合語言模型分別在目標文本任務和通用文本任務上的性能級別;其中,所述性能級別包括高級別、中級別和低級別;
13、選擇單元,用于選擇在目標文本任務上性能級別為高級別,且在通用文本任務上性能級別為中級別及以上的所述融合語言模型作為最終語言模型,并利用所述最終語言模型對待預測的目標通用文本進行預測,得到預測結果。
14、第三方面,本發明實施例又提供了一種計算機設備,其包括存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的計算機程序,所述處理器執行所述計算機程序時實現上述第一方面所述的可解決大模型災難性遺忘的文本預測方法。
15、第四方面,本發明實施例還提供了一種計算機可讀存儲介質,其中所述計算機可讀存儲介質存儲有計算機程序,所述計算機程序當被處理器執行時使所述處理器執行上述第一方面所述的可解決大模型災難性遺忘的文本預測方法。
16、本發明實施例提供一種可解決災難性遺忘的文本預測方法、相關裝置及存儲介質,該方法將原始語言模型和微調語言模型融合得到融合模型,并在目標文本任務和通用文本任務上評估其性能級別,選擇在目標文本任務上性能級別為高級別,且在通用文本任務上性能級別為中級別及以上的最終語言模型進行目標通用文本的預測,保證最終語言模型能夠保持在通用任務上的泛化能力,同時在目標任務上的性能得到提升,進一步減少或避免微調過程中出現的災難性遺忘的問題。
技術特征:
1.一種可解決大模型災難性遺忘的文本預測方法,其特征在于,包括:
2.根據權利要求1所述的可解決大模型災難性遺忘的文本預測方法,其特征在于,所述將所述原始語言模型和所述微調語言模型進行融合,得到融合語言模型,包括:
3.根據權利要求2所述的可解決大模型災難性遺忘的文本預測方法,其特征在于,將目標文本任務的目標文本和通用文本任務的通用文本輸入至所述融合語言模型,以評估所述融合語言模型分別在目標文本任務和通用文本任務上的性能級別,包括:
4.根據權利要求1所述的可解決大模型災難性遺忘的文本預測方法,其特征在于,所述對原始語言模型進行微調,得到微調后的微調語言模型,包括:
5.根據權利要求4所述的可解決大模型災難性遺忘的文本預測方法,其特征在于,所述對所述文本數據集進行預處理,包括:
6.根據權利要求4所述的可解決大模型災難性遺忘的文本預測方法,其特征在于,所述使用所述測試集和所述驗證集對所述原始語言模型進行微調,得到微調語言模型,包括:
7.根據權利要求6所述的可解決大模型災難性遺忘的文本預測方法,其特征在于,所述超參數包括學習率和批次大小。
8.一種可解決大模型災難性遺忘的文本預測裝置,其特征在于,包括:
9.一種計算機設備,包括存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的計算機程序,其特征在于,所述處理器執行所述計算機程序時實現如權利要求1至7中任一項所述的可解決大模型災難性遺忘的文本預測方法。
10.一種計算機可讀存儲介質,其特征在于,所述計算機可讀存儲介質存儲有計算機程序,所述計算機程序當被處理器執行時使所述處理器執行如權利要求1至7任一項所述的可解決大模型災難性遺忘的文本預測方法。
技術總結
本發明公開了一種可解決災難性遺忘的文本預測方法、相關裝置及存儲介質,其方法包括:對原始語言模型進行微調;載入原始語言模型和微調語言模型;將原始語言模型和微調語言模型進行融合,得到融合語言模型;將目標文本和通用文本輸入至融合語言模型,以評估融合語言模型分別在目標文本任務和通用文本任務上的性能級別;選擇在目標文本任務上性能級別為高級別,且在通用文本任務上性能級別為中級別及以上的融合語言模型作為最終語言模型,并利用最終語言模型對待預測的目標通用文本進行預測,得到預測結果。本發明能夠保證最終語言模型能保持在通用任務上的泛化能力,同時提高在目標任務上的性能,進一步有效避免災難性遺忘的問題。
技術研發人員:沈雄,趙依芳,傅斌星
受保護的技術使用者:杭州華策影視科技有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!