一種基于數據分析的英語文本數據處理方法
本發明涉及文本推薦,具體涉及一種基于數據分析的英語文本數據處理方法。
背景技術:
1、隨著科技的發展,用戶對英文文獻的需求量和查詢頻繁程度逐年上升,伴隨著信息化時代的到來依賴互聯網獲取所需要的信息,但其上的信息呈現爆炸式增長,如何有效地從海量英文信息中篩選出所需的有用信息成了關鍵性的技術問題。
2、通常情況下閱讀者通過留意文本中的標題、關鍵詞、摘要等一些關鍵信息,根據這些關鍵信息來進行判斷是否有進一步閱讀文獻全文的價值,例如閱讀者點擊相應的鏈接、打開相應的文獻,然后再進行摘要的讀取以尋找其中的關鍵信息,確定該文獻有價值則會進行瀏覽,然而當需要查看大量的文獻時,就會進行多次重復的操作,繁瑣費時,效率較低,更容易造成閱讀疲勞。
技術實現思路
1、本發明的目的在于提供一種基于數據分析的英語文本數據處理方法,解決以下技術問題:
2、通常情況下閱讀者通過留意文本中的標題、關鍵詞、摘要等一些關鍵信息,根據這些關鍵信息來進行判斷是否有進一步閱讀文獻全文的價值,例如閱讀者點擊相應的鏈接、打開相應的文獻,然后再進行摘要的讀取以尋找其中的關鍵信息,確定該文獻有價值則會進行瀏覽,然而當需要查看大量的文獻時,就會進行多次重復的操作,繁瑣費時,效率較低,更容易造成閱讀疲勞。
3、本發明的目的可以通過以下技術方案實現:
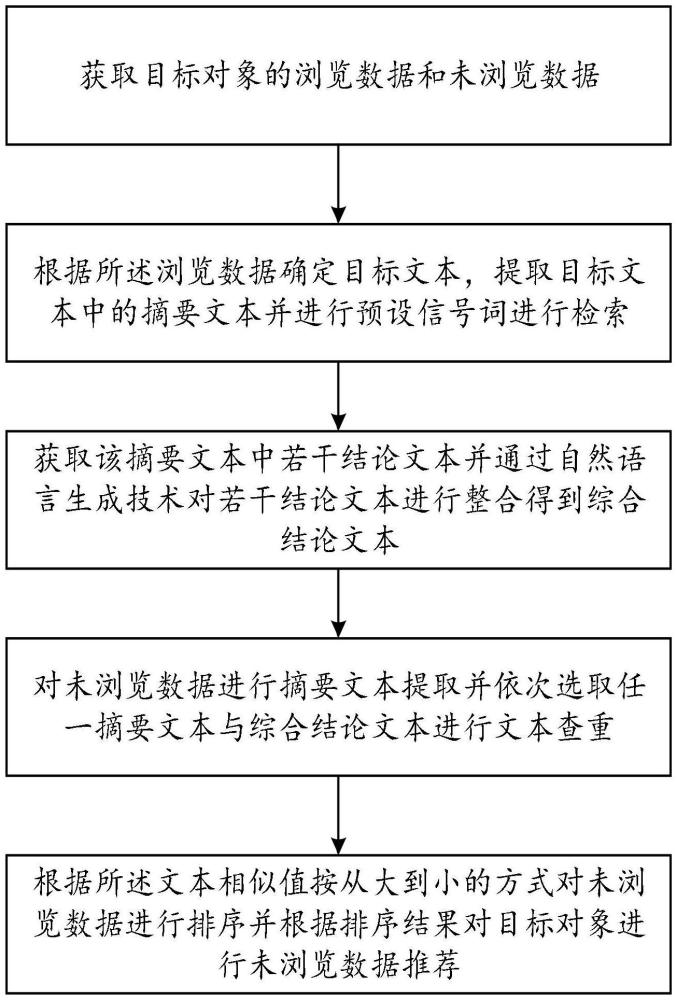
4、一種基于數據分析的英語文本數據處理方法,包括以下步驟:
5、s1,獲取目標對象檢索后的瀏覽數據和未瀏覽數據,所述瀏覽數據為檢索后瀏覽的英文文獻、文獻瀏覽時間和文獻下載記錄;所述未瀏覽數據為檢索后未瀏覽的英文文獻集合;
6、s2,根據所述瀏覽數據確定目標文本,提取目標文本中的摘要文本并進行預設信號詞進行檢索,得到該摘要文本中所有預設信號詞位置,獲取所有包含預設信號詞之后的文本信息,并將所述文本信息標定為結論文本;獲取該摘要文本中若干結論文本并通過自然語言處理技術對若干結論文本進行整合得到綜合結論文本;
7、s3,對未瀏覽數據進行文本分析得到若干摘要文本,依次選取任一摘要文本與綜合結論文本進行文本查重計算,得到若干文本查重值并標記為x1,x2,...,xn,根據所述文本查重值按從大到小的方式對未瀏覽數據進行排序并根據排序結果對目標對象進行未瀏覽數據推薦。
8、作為本發明的進一步方案,所述s1中,還包括:
9、根據目標對象輸入的檢索詞對文獻數據庫進行篩選,得到檢索數據,根據英文文獻的發表順序、文章標題與檢索詞的相關度、影響因子對檢索數據進行排序。
10、作為本發明的進一步方案,所述s2中,目標文本的確定過程為:
11、獲取任一瀏覽文獻的文獻瀏覽時間t和文獻下載記錄n,若n大于0,則根據計算公式w=b*t*d,b、d為預設系數且b小于d,計算得出所有瀏覽文獻的推薦分數w;若n等于0,則根據計算公式w=b*t,計算得出所有瀏覽文獻的推薦分數;若存在任一瀏覽文獻的推薦分數w大于等于預設閾值,則將該瀏覽文獻標定為目標文本。
12、作為本發明的進一步方案,所述s2中,若所述摘要文本中不存在預設信號詞,則從所述摘要文本中提取預設部分的文本信息,將所述文本信息作為所述摘要文本中的結論文本。
13、作為本發明的進一步方案,所述s2中,綜合結論文本的具體生成過程為:
14、依次對若干結論文本進行預處理,所述預處理包括去除停用詞、詞性標注、短語提取;利用語義網絡技術構建結論文本之間的語義關系圖,根據語義關系圖使用nlp技術將若干結論文本整合成一個綜合的結論文本。
15、作為本發明的進一步方案,所述s3中,還包括對若干摘要文本進行預處理,具體過程為:
16、依次對任一摘要文本進行預設信號詞檢索,得到該摘要文本中所有預設信號詞位置,獲取包含所有預設信號詞之后的文本信息,并將所述文本信息標定為結論文本,獲取該摘要文本中若干結論文本并通過自然語言處理技術對若干結論文本進行整合得到綜合結論文本。
17、作為本發明的進一步方案,所述s3中,文本查重計算的具體過程為:
18、分別將摘要文本和所述綜合結論文本按字符順序轉化為兩組ascii碼值;對每個字符利用周圍字符的ascii碼值表示其特征;利用自編碼器對每個字符點的特征進行降維處理;對降維后的特征利用jaccard相似值系數計算兩段文本間的相似值;
19、文本查重值的計算公式為:
20、
21、其中,a為綜合文本的特征集合,b為任一未瀏覽數據對應摘要文本的特征集合,j為相似值。
22、作為本發明的進一步方案,還包括若存在若干目標文本,則選取任一未瀏覽數據對應的摘要文本依次與若干目標文本對應的綜合結論文本進行總文本查重計算,根據所述總文本查重值按從大到小的方式對未瀏覽數據進行排序并根據排序結果對目標對象進行未瀏覽數據推薦;
23、總文本查重值的計算過程為:
24、
25、其中,ai為任一目標文本對應綜合結論文本的特征集合,b為任一未瀏覽數據對應摘要文本的特征集合,j'為總文本查重值,wai為目標文本ai對應綜合文本的推薦分數,n為目標文本的數量。
26、本發明的有益效果:
27、本發明首先通過分析用戶的瀏覽數據得到目標對象的文本瀏覽方向得到目標文本,獲取目標文本的摘要文本,可以理解的文本摘要是旨在提供全文的主要觀點、發現、方法和結論,通過檢索預設信號詞并標定結論文本,能快速提取出摘要文本中的關鍵結論信息,利用自然語言生成技術整合多個結論文本,得到一個包含了來自該目標文本的關鍵結論信息的綜合結論文本,通過計算未瀏覽數據的摘要文本與綜合結論文本的相似度,并按相似度從大到小排序,能夠優先推薦與目標對象瀏覽方向最相關的文獻,這不僅可以提高用戶的閱讀興趣,還可以確保用戶接觸到高質量的、相關的文獻資源,提高檢索效率減少了用戶篩選海量文獻的負擔,有效緩解閱讀疲勞的問題。
技術特征:
1.一種基于數據分析的英語文本數據處理方法,其特征在于,包括以下步驟:
2.根據權利要求1所述的一種基于數據分析的英語文本數據處理方法,其特征在于,所述s1中,還包括:
3.根據權利要求1所述的一種基于數據分析的英語文本數據處理方法,其特征在于,所述s2中,目標文本的確定過程為:
4.根據權利要求1所述的一種基于數據分析的英語文本數據處理方法,其特征在于,所述s2中,若所述摘要文本中不存在預設信號詞,則從所述摘要文本中提取預設部分的文本信息,將所述文本信息作為所述摘要文本中的結論文本。
5.根據權利要求1所述的一種基于數據分析的英語文本數據處理方法,其特征在于,所述s2中,綜合結論文本的具體生成過程為:
6.根據權利要求1所述的一種基于數據分析的英語文本數據處理方法,其特征在于,所述s3中,還包括對若干摘要文本進行預處理,具體過程為:
7.根據權利要求1所述的一種基于數據分析的英語文本數據處理方法,其特征在于,所述s3中,文本查重計算的具體過程為:
8.根據權利要求1所述的一種基于數據分析的英語文本數據處理方法,其特征在于,還包括若存在若干目標文本,則選取任一未瀏覽數據對應的摘要文本依次與若干目標文本對應的綜合結論文本進行總文本查重計算,根據所述總文本查重值按從大到小的方式對未瀏覽數據進行排序并根據排序結果對目標對象進行未瀏覽數據推薦;
技術總結
本發明公開了一種基于數據分析的英語文本數據處理方法,屬于文本推薦技術領域,具體包括:獲取目標對象的瀏覽數據和未瀏覽數據;根據所述瀏覽數據確定目標文本,提取目標文本中的摘要文本并進行預設信號詞進行檢索,獲取所有包含預設信號詞之后的文本信息,并將所述文本信息標定為結論文本;對未瀏覽數據進行文本分析得到若干摘要文本,將摘要文本與綜合結論文本進行文本查重計算,并根據文本查重值按從大到小的方式對未瀏覽數據進行排序,根據排序結果對目標對象進行未瀏覽數據推薦。本發明提高了檢索效率,減少了用戶篩選海量文獻的負擔。
技術研發人員:徐向楠,董俊,王達盈,趙麗娜,趙洋,鄒春玲
受保護的技術使用者:吉林師范大學
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!