提升大語言模型在RAG框架下輸出準確率的方法及裝置與流程
本申請涉及自然語言處理,例如涉及一種提升大語言模型在rag框架下輸出準確率的方法及裝置。
背景技術:
1、隨著人工智能技術的飛速發展,大語言模型(large?language?model,簡稱llm)已成為自然語言處理(nlp)領域的一個研究熱點。這些模型通過訓練海量的文本數據,展現出了在智能問答、文本生成、對話系統等任務中的強大能力。然而,盡管大模型在多個任務上取得了令人矚目的成就,它們仍然面臨著一個主要問題——幻覺(hallucination)。所謂幻覺,是指模型在沒有足夠信息支持的情況下生成虛假信息的現象,這嚴重影響了模型輸出的準確性和可信度。
2、為了解決llm的幻覺問題,研究者們提出了檢索增強生成(retrieval-augmentedgeneration,簡稱rag)技術。rag通過將外部信息檢索與llms的生成能力相結合,旨在提高模型回答特定查詢的準確性。在rag框架下,模型不僅依賴于其內部知識,還能動態地從外部知識庫中檢索相關信息,以輔助生成過程。盡管rag技術在減少幻覺現象方面取得了一定成效,但它仍然存在一些局限性。例如,檢索到的信息可能并不總是與查詢完全相關,或者檢索器的性能限制了最終答案的準確性。此外,rag系統在整合檢索到的信息時,可能無法充分理解和利用上下文信息,導致生成的答案不夠精確或有偏差。
技術實現思路
1、為了對披露的實施例的一些方面有基本的理解,下面給出了簡單的概括。所述概括不是泛泛評述,也不是要確定關鍵/重要組成元素或描繪這些實施例的保護范圍,而是作為后面的詳細說明的序言。
2、本公開實施例提供了一種提升大語言模型在rag框架下輸出準確率的方法及裝置,以提高大語言模型在rag框架下的性能,減少幻覺現象,生成更準確、更可靠的答案。
3、在一些實施例中,所述方法包括:
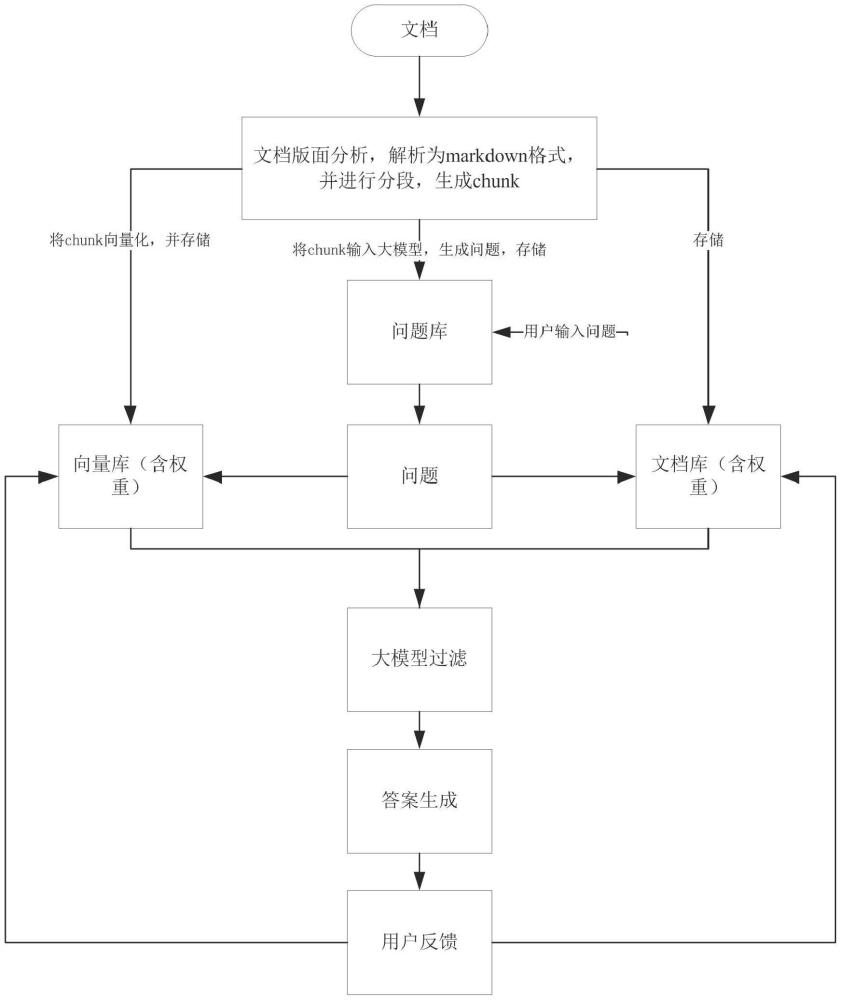
4、(1)文檔攝取與分段:支持上傳多種格式的文檔,并利用特定模型對文檔進行版面分析和內容提取,將文檔內容分段,并保留每段的關鍵信息;
5、(2)向量化操作與存儲:對每個分段進行向量化處理,并將向量及對應權重存儲于向量庫中;
6、(3)相關問題庫生成:將整理后的分段送入大模型生成相關問題,并按照一定結構分類存儲;
7、(4)意圖理解與多重搜索:在用戶提問時,根據關鍵詞實時推薦問題,并在問題獲取后,進行包括關鍵詞搜索和向量搜索的多重搜索,最終合并搜索結果進行過濾;
8、(5)答案生成:基于篩選出的素材,通過大模型生成并返回答案。
9、可選地,在步驟(1)中,支持的文檔格式包括pdf、docx及xlsx中的至少一種;對pdf文檔,利用dit模型進行版面分析,分類提取標題、段落、表格、公式、圖片;對docx文檔,使用python-docx庫解析并轉換為markdown格式;對xlsx文檔,使用pandas庫讀取內容;將文檔內容分段為多個chunk,每個chunk保留文件名、標題、關鍵詞,針對xlsx文檔,將每行內容與表頭組合成chunk。
10、可選地,在步驟(2)中的向量化處理采用bge-large模型,向量庫采用qdrant,且每個分段的初始權重設為100。
11、可選地,在步驟(3)中的問題分類存儲采用樹形結構。
12、可選地,在步驟(4)中的關鍵詞搜索包括提取問題關鍵詞,匹配文檔庫中的分段,并按權重排序。
13、可選地,在步驟(5)中的答案生成利用prompt技術。
14、可選地,方法還包括人工糾錯反饋步驟:在答案生成后提供用戶評價選項,并根據用戶評價調整向量庫和文檔庫中相關素材的權重。
15、可選地,用戶評價選項包括好評和差評,且根據用戶評價調整相關素材的權重,以優化后續搜索與匹配精度。
16、在一些實施例中,所述裝置包括處理器和存儲有程序指令的存儲器,處理器被配置為在運行所述程序指令時,執行前述的提升大語言模型在rag框架下輸出準確率的方法。
17、在一些實施例中,所述存儲介質,存儲有程序指令,程序指令在運行時,執行前述的提升大語言模型在rag框架下輸出準確率的方法。
18、本公開實施例提供的提升大語言模型在rag框架下輸出準確率的方法及裝置,可以實現以下技術效果:
19、本發明通過優化文檔攝取與分段、意圖識別、多重搜索策略,實現了從大語言模型的輸入到輸出的全流程優化。具體來說,通過精細化的文檔處理,確保模型能夠更有效地理解和利用輸入信息;通過相關問題庫的生成和意圖理解,幫助用戶更準確地表達查詢意圖;通過多重搜索和過濾策略,提高檢索結果的準確性和相關性廣泛的文檔支持:系統支持多種格式的文檔上傳與解析,滿足了用戶多樣化的信息輸入需求。
20、以上的總體描述和下文中的描述僅是示例性和解釋性的,不用于限制本申請。
技術特征:
1.一種提升大語言模型在rag框架下輸出準確率的方法,其特征在于,包括:
2.根據權利要求1所述的方法,其特征在于,在步驟(1)中,支持的文檔格式包括pdf、docx及xlsx中的至少一種;
3.根據權利要求1所述的方法,其特征在于,在步驟(2)中的向量化處理采用bge-large模型,向量庫采用qdrant,且每個分段的初始權重設為100。
4.根據權利要求1所述的方法,其特征在于,在步驟(3)中的問題分類存儲采用樹形結構。
5.根據權利要求4所述的方法,其特征在于,在步驟(4)中的關鍵詞搜索包括提取問題關鍵詞,匹配文檔庫中的分段,并按權重排序。
6.根據權利要求1所述的方法,其特征在于,在步驟(5)中的答案生成利用prompt技術。
7.根據權利要求1至6任一項所述的方法,其特征在于,還包括人工糾錯反饋步驟:
8.根據權利要求7所述的方法,其特征在于,
9.一種提升大語言模型在rag框架下輸出準確率的裝置,包括處理器和存儲有程序指令的存儲器,其特征在于,所述處理器被配置為在運行所述程序指令時,執行如權利要求1至8任一項所述的提升大語言模型在rag框架下輸出準確率的方法。
10.一種存儲介質,存儲有程序指令,其特征在于,所述程序指令在運行時,執行如權利要求1至8任一項所述的提升大語言模型在rag框架下輸出準確率的方法。
技術總結
本申請涉及自然語言處理技術領域,公開了一種提升大語言模型在RAG框架下輸出準確率的方法及裝置,該方法涵蓋多個環節:先對上傳的多種格式文檔進行版面分析、內容提取與分段處理,捕捉每段關鍵信息;隨后,對這些分段進行向量化操作,連同對應權重存儲于向量庫。接下來,利用大模型為分段生成相關問題,并按結構分類儲存。在用戶提問時,系統根據關鍵詞推薦問題,并執行關鍵詞和向量雙重搜索,最后合并、過濾搜索結果。基于這些優選素材,大模型將生成并返回精準答案。這一創新方法顯著提高了大語言模型在RAG框架下的性能,有效減少了幻覺現象,為用戶提供了更準確、更可靠的回答。
技術研發人員:張磊,李雪,陳其賓,段強,姜凱,李銳
受保護的技術使用者:山東浪潮科學研究院有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!