一種生成式文本摘要模型的一致性評估方法及系統
本發明涉及軟件工程,特別是指一種生成式文本摘要模型的一致性評估方法及系統。
背景技術:
1、文本摘要任務是自然語言處理領域的重要研究分支。其中,生成式摘要模型則首先分析文本的語義信息來創建文本的內部表示,然后通過深入分析和推理,自行組織語言對原文檔進行概括。
2、由于生成式摘要可以更好地模擬人工撰寫摘要的過程:深入理解原文、有效整合信息、提煉總結摘要內容,近年來備受學術界的關注。專家學者們開發出了各種基于深度學習的生成式摘要模型,并構建了多個大型基準數據集用以訓練和評估這些模型。現如今,生成式摘要模型在信息處理、新聞網站以及智能搜索等領域發揮越來越重要的作用。鑒于其廣泛的應用需求,生成式摘要模型需要具備高度的一致性,即其所生成的摘要能夠真實且準確地反映原始文檔的關鍵信息和事實。
3、然而,現有的生成式摘要模型在進行一致性評估時,只考慮生成摘要和參考摘要之間的表面詞重疊,而忽略了底層的語義和事實層面的一致性,并且需要依賴于注釋良好的數據集。
技術實現思路
1、為了解決,現有的生成式摘要模型在進行一致性評估時,只考慮生成摘要和參考摘要之間的表面詞重疊,而忽略了底層的語義和事實層面的一致性,并且需要依賴于注釋良好的數據集的技術問題,本發明提供了一種生成式文本摘要模型的一致性評估方法及系統。
2、本發明實施例提供的技術方案如下:
3、第一方面:
4、本發明實施例提供的一種生成式文本摘要模型的一致性評估方法,包括:
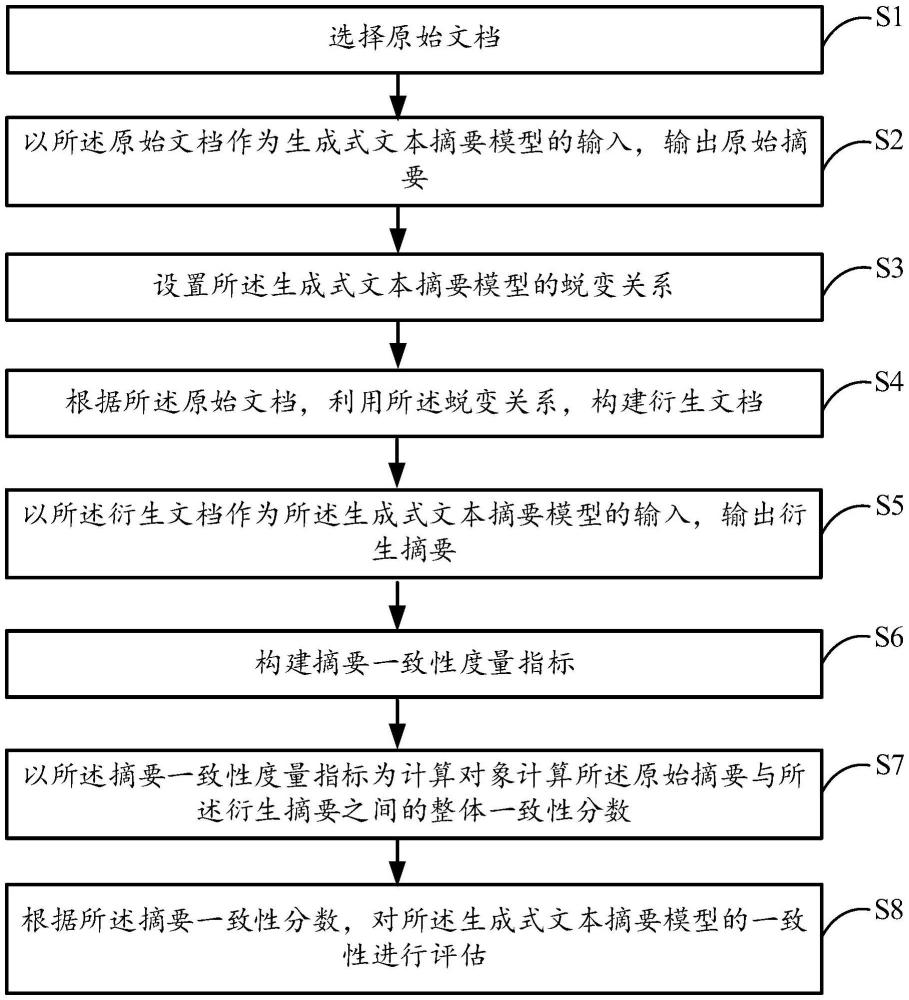
5、s1:選擇原始文檔;
6、s2:以所述原始文檔作為生成式文本摘要模型的輸入,輸出原始摘要;
7、s3:設置所述生成式文本摘要模型的蛻變關系;
8、s4:根據所述原始文檔,利用所述蛻變關系,構建衍生文檔;
9、s5:以所述衍生文檔作為所述生成式文本摘要模型的輸入,輸出衍生摘要;
10、s6:構建摘要一致性度量指標;
11、s7:以所述摘要一致性度量指標為計算對象計算所述原始摘要與所述衍生摘要之間的整體一致性分數;
12、s8:根據所述摘要一致性分數,對所述生成式文本摘要模型的一致性進行評估。
13、第二方面:
14、本發明實施例提供的一種生成式文本摘要模型的一致性評估系統,包括:
15、處理器;
16、存儲器,所述存儲器上存儲有計算機可讀指令,所述計算機可讀指令被所述處理器執行時,實現如第一方面所述的生成式文本摘要模型的一致性評估方法。
17、第三方面:
18、本發明實施例提供的一種計算機可讀存儲介質,其上存儲有計算機程序,該程序被處理器執行時實現如第一方面所述的生成式文本摘要模型的一致性評估方法。
19、本發明實施例提供的技術方案帶來的有益效果至少包括:
20、(1)在本發明中,通過設置所述生成式文本摘要模型的蛻變關系,根據所述原始文檔,利用所述蛻變關系,構建衍生文檔,以所述衍生文檔作為所述生成式文本摘要模型的輸入,輸出衍生摘要;關注了底層的語義和事實層面的一致性的問題,提高了生成摘要的一致性度量的可靠性。
21、(2)在本發明中,通過以所述原始文檔作為生成式文本摘要模型的輸入,輸出原始摘要,根據所述原始文檔,利用所述蛻變關系,構建衍生文檔,并輸出衍生摘要,以所述摘要一致性度量指標為計算對象計算所述原始摘要與所述衍生摘要之間的整體一致性分數,根據所述摘要一致性分數,對所述生成式文本摘要模型的一致性進行評估,提高了更全面和客觀的摘要評估質量,減少了對人工標注的數據集的依賴。
技術特征:
1.一種生成式文本摘要模型的一致性評估方法,其特征在于,包括:
2.根據權利要求1所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述蛻變關系包括獨立于所述原始摘要的蛻變關系以及依賴于所述原始摘要的蛻變關系。
3.根據權利要求2所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述獨立于所述原始摘要的蛻變關系包括mr1;
4.根據權利要求3所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述s4具體包括:
5.根據權利要求3所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述s4具體還包括:
6.根據權利要求1所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述摘要一致性度量指標包括:語義相關性指標和事實一致性指標。
7.根據權利要求1所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述原始摘要與所述衍生摘要之間的整體一致性分數具體為:
8.根據權利要求6所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述語義相關性分數的計算方式包括:
9.根據權利要求5所述的生成式文本摘要模型的一致性評估方法,其特征在于,所述事實一致性分數的計算方式包括:
10.一種生成式文本摘要模型的一致性評估系統,其特征在于,包括:
技術總結
本發明提供一種生成式文本摘要模型的一致性評估方法及系統,涉及軟件工程技術領域,方法包括:選擇原始文檔,以原始文檔作為生成式文本摘要模型的輸入,輸出原始摘要,設置生成式文本摘要模型的蛻變關系,根據原始文檔,利用蛻變關系,構建衍生文檔,以衍生文檔作為生成式文本摘要模型的輸入,輸出衍生摘要。構建摘要一致性度量指標,以摘要一致性度量指標為計算對象計算原始摘要與衍生摘要之間的整體一致性分數,根據摘要一致性分數,對生成式文本摘要模型的一致性進行評估。本發明提供了生成摘要的一致性評估方法,提升了摘要一致性度量的可靠性,減少了對人工標注的數據集的依賴。
技術研發人員:江明月,朱小艷
受保護的技術使用者:浙江理工大學
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!