一種基于神經元激活的機器閱讀理解方法、裝置、設備及計算機可讀介質
本發明涉及人工智能,尤其涉及一種基于神經元激活的機器閱讀理解方法。
背景技術:
1、近年來,隨著大模型的快速發展,機器的閱讀理解能力越來越強,應用場景得到了廣泛探索。例如:問答式搜索引擎、數學問題推理解析服務、能提供高效高質量咨詢服務的智能客服等。模型的可解釋性是提高機器在應用過程中的推理一致性(機器學習模型對同類輸入產生穩定、一致的輸出或決策的能力)的關鍵技術。
2、隨著語言模型的能力變得越來越強以及模型結構越來越復雜,理解它們的行為及其預測背后的基本原理也越來越具有挑戰性。為了理解這些模型所做的預測,人們開發了各種方法,如根據每個輸入特征對給定模型中的神經元激活提供解釋,捕捉每個輸入特征對給定模型預測的影響。
3、神經元激活分析是一種研究模型性能關鍵因素或與特定語言屬性相關的表示中特定維度(即神經元)的方法,而非對整個向量空間進行檢查。通過神經元激活分析可以進一步研究解釋llm的涌現現象,然而深度學習模型神經元數量眾多,如何確定關鍵神經元以及對成千上百個神經元激活值進行分析是非常困難的。其中一種簡單的方法包括兩個主要步驟:首先,以無監督的方式確定重要的神經元;其次,通過監督任務學習語言屬性與個別神經元之間的關系。在假設不同模型學習類似屬性時通常共享相似的神經元的基礎上,這些共享神經元根據各種指標(如相關度測量和學習權重)進行排名。或者,也可以采用傳統的監督分類方法來找到給定模型中的重要神經元。然而,這些方法在準確性和選擇性之間往往難以平衡。雖然bau和antverg等人認為只有一小部分神經元對決策起到重要作用。但模型中的神經元相互連結,一般來說,應該對模型的所有神經元進行解釋。隨著llm的泛化性不斷提高,openai利用gpt-4對gpt-2xl中的單個神經元激活生成了自然語言解釋。它使用gpt-4來總結文本中觸發給定gpt-2xl神經元的高激活值的模式。例如,gpt-4可以將一個神經元的模式總結為:對電影、角色和娛樂的參考。每個神經元解釋的質量是通過測試gpt-4如何在新的文本例子上模擬真實神經元的行為來評估的。根據gpt-4的模擬激活與真實激活之間的相關性,對解釋進行了評分。高相關性表明了一個準確的解釋,捕捉了神經元編碼的本質。超過1000個gpt-2xl神經元被發現有來自gpt-4的高分解釋,這占了他們的大部分行為。這種自動生成的自然語言提供了對gpt-2xl中涌現的內部計算和特征表示的直觀洞察力。
4、上述研究提供了對模型神經元的自動可解釋技術,但缺少如何將神經元的解釋運用于模型推理可靠性提高的研究,且大量的神經元激活解釋,難以有效地總結出利于人們理解的模型推理解釋。因此,現在亟需一種將神經元的解釋運用到模型推理中的技術。
技術實現思路
1、本發明描述一種基于神經元激活的機器閱讀理解方法、裝置、設備及計算機可讀介質,可以解決上述技術問題。
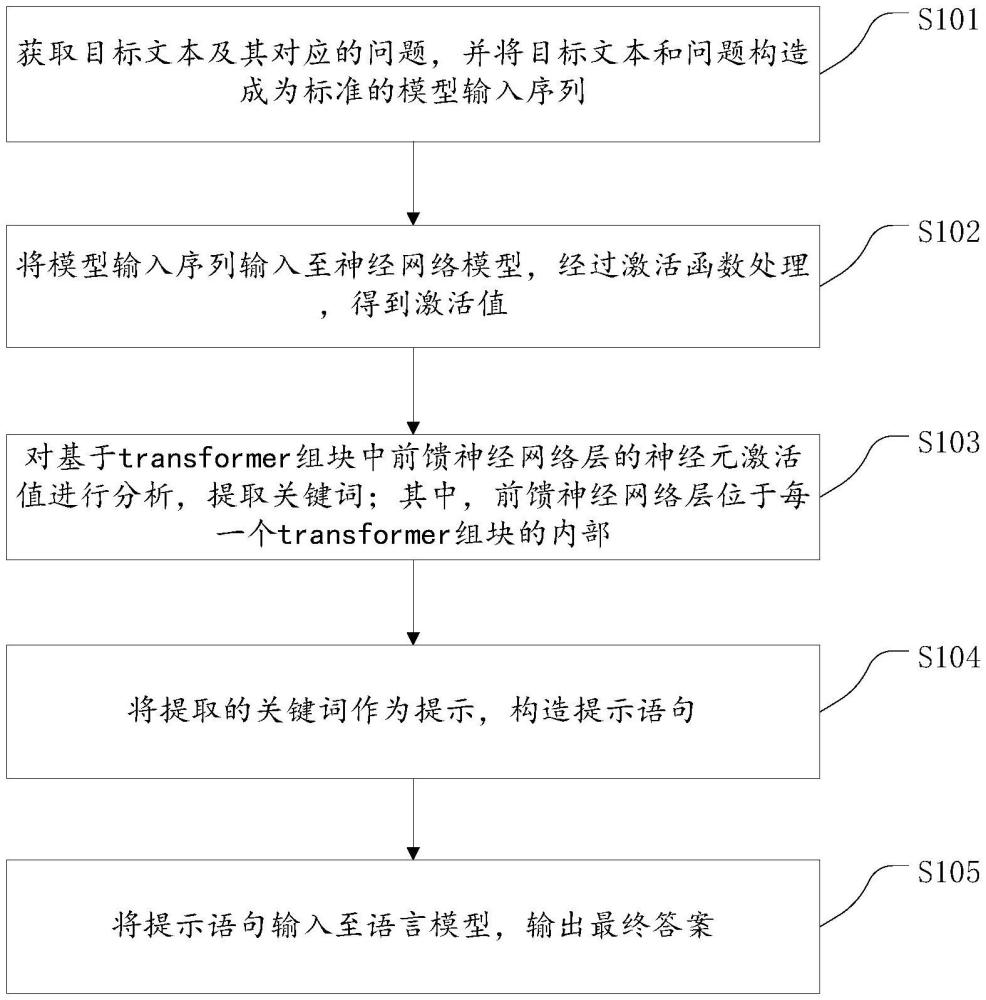
2、根據第一方面,提供一種基于神經元激活的機器閱讀理解方法。該方法包括:
3、獲取目標文本及其對應的問題,并將目標文本和問題構造成為標準的模型輸入序列;
4、將模型輸入序列輸入至神經網絡模型,經過激活函數處理,得到激活值;
5、對基于transformer組塊中前饋神經網絡層的神經元激活值進行分析,提取關鍵詞;其中,前饋神經網絡層位于每一個transformer組塊的內部。
6、將提取的關鍵詞作為提示,構造提示語句;
7、將提示語句輸入至語言模型,輸出最終答案。
8、在一些實施例中,對目標文本和問題進行構造的過程具體包括:
9、對目標文本和問題進行分詞;
10、將每個單詞或子詞映射到一個向量;
11、將單詞或子詞的向量按文本中的順序排列,并對向量進行裁剪或填充,得到固定長度的模型輸入序列。
12、在一些實施例中,激活函數選用s?i?lu激活函數。
13、在一些實施例中,提取關鍵詞的方法包括:
14、將最后一層的transformer組塊中前饋神經網絡層的所有神經元激活值按照token進行劃分;
15、然后對每個token的所有激活值進行加和取平均值;
16、去除文本中的標點符號token,將剩余文本token按照激活值從大到小進行排序,選取前三個token作為關鍵詞。
17、根據第二方面,提供一種基于神經元激活的機器閱讀理解裝置,包括:
18、模型輸入序列構造模塊,用于將目標文本和問題構造成標準的模型輸入序列;
19、激活值提取模塊,對模型輸入序列進行激活函數處理,得到激活值;
20、關鍵詞提取模塊,用于對基于transformer組塊中前饋神經網絡層的神經元激活值進行分析,提取關鍵詞;
21、提示語句構造模塊,用于將關鍵詞作為提示,構造提示語句;
22、答案輸出模塊,用于根據提示語句,輸出問題對應的答案。
23、在一些實施例中,關鍵詞提取模塊,具體包括:
24、激活值劃分單元,用于將最后一層的transformer組塊中前饋神經網絡層的所有神經元激活值按照token進行劃分;
25、激活值計算單元,用于對每個token的所有激活值進行加和取平均值計算;
26、激活值排序單元,用于對文本token按照激活值從大到小進行排序,并選取前三個token作為關鍵詞。
27、根據第三方面,提供一種電子設備,包括存儲器、處理器,所述存儲器上存儲有可在所述處理器上運行的計算機程序,其特征在于,所述處理器執行所述計算機程序時實現如第一方面中任一所述的方法。
28、根據第四方面,一種具有處理器可執行的非易失的程序代碼的計算機可讀介質,其特征在于,所述程序代碼使所述處理器執行如第一方面中任一所述的方法。
29、本發明提供一種基于神經元激活的機器閱讀理解方法、裝置、設備及計算機可讀介質。通過對目標文本和問題在最后一層的transformer組塊中前饋神經網絡層的神經元激活值進行分析,提取關鍵詞,用關鍵詞構造提示語句,模型再根據提示語句輸出問題的答案。分析神經元的激活情況,可以了解模型在不同階段對文本的理解和關注點,進而幫助理解模型的決策過程,并驗證模型的答案與推理過程的一致性,按照上述方法可以實現將其神經元的解釋應用到模型推理的過程中,減少模型推理過程與預測結果之間的偏差。
技術特征:
1.一種基于神經元激活的機器閱讀理解方法,其特征在于,所述方法包括:
2.根據權利要求1所述的方法,其特征在于,對目標文本和問題進行構造的過程具體包括:
3.根據權利要求1所述的方法,其特征在于,所述激活函數選用silu激活函數。
4.根據權利要求1所述的方法,其特征在于,所述提取關鍵詞的方法包括:
5.一種基于神經元激活的機器閱讀理解裝置,其特征在于,通過如權利要求1至4中任一項所述的方法進行機器閱讀理解,所述裝置包括:
6.根據權利要求5所述的一種裝置,其特征在于,關鍵詞提取模塊,具體包括:
7.一種電子設備,包括存儲器、處理器,所述存儲器上存儲有可在所述處理器上運行的計算機程序,其特征在于,所述處理器執行所述計算機程序時實現上述權利要求1至4任一項所述的方法。
8.一種具有處理器可執行的非易失的程序代碼的計算機可讀介質,其特征在于,所述程序代碼使所述處理器執行所述權利要求1至4任一項所述方法。
技術總結
本發明提供一種基于神經元激活的機器閱讀理解方法、裝置、設備及計算機可讀介質。首先,獲取目標文本及其對應的問題,并將目標文本和問題構造成為標準的模型輸入序列;其次,將模型輸入序列輸入至神經網絡模型,經過激活函數處理,得到激活值;然后,對基于transformer組塊中前饋神經網絡層的神經元激活值進行分析,提取關鍵詞;接著,將提取的關鍵詞作為提示,構造提示語句;最后,將提示語句輸入至語言模型,輸出最終答案。綜上所述,按照上述方法可以實現將其神經元的解釋應用到模型推理的過程中,以減少模型推理過程與預測結果之間的偏差。
技術研發人員:孫媛,鄧俊杰,朋毛才讓
受保護的技術使用者:中央民族大學
技術研發日:
技術公布日:2024/10/14
- 還沒有人留言評論。精彩留言會獲得點贊!