一種大模型訓練數據過濾方法、裝置、設備及介質與流程
本發明屬于數據壓縮,具體而言涉及一種大模型訓練數據過濾方法、裝置、設備及介質。
背景技術:
1、大型語言模型(llms)顯著推進了機器語言理解的邊界。然而,用于微調它們的指令調優數據集的巨大規模顯著增加了llm開發的費用。
2、大型語言模型能夠掌握廣泛的語言、編碼甚至數學技能,這得益于模型自身、計算能力及訓練數據集的擴展。例如,opt-175b報告使用了992個a100gpu進行預訓練;其指令微調產生的opt-iml模型,需要128個a100gpu和72小時的訓練時間。
3、因此,隨著大型語言模型(llms)及其數據集的持續增長,低效且成本高昂的訓練挑戰變得越來越緊迫。盡管存在一些包括數據蒸餾、核心集選擇和主動學習在內的現有數據修剪方法,但它們對于llms的指令調優并不方便。一方面,基于蒸餾和主動學習的方法在修剪過程中通常是計算密集型的。例如,需要模型在完整數據集上的整個訓練軌跡作為監督來蒸餾數據集。另一方面,雖然原本為計算機視覺設計的核心集選擇方法通常效率較高,但最近的研究表明,隨著所選子集比例的增加,這些方法實際上并不能始終優于隨機選擇。此外,數據蒸餾旨在合成少量樣本以替代原始數據集。在數據蒸餾的大量工作中,查詢并匹配模型在完整數據集上訓練過程中的重要特征。這些特征包括軟標簽、梯度、訓練軌跡、數據集特征分布。盡管這些方法性能良好,但它們通常計算成本高,且需要針對特定模型實現。
4、綜上,現有的數據修剪過濾方法需要結合訓練過程進行推理計算,存在計算成本高的問題需要解決。
技術實現思路
1、鑒于上述的分析,本發明實施例旨在提供一種大模型訓練數據過濾方法、裝置、設備及介質,用以解決現有技術中數據過濾存在計算成本高的問題。
2、本發明第一方面實施例提供一種大模型訓練數據過濾方法,包括以下步驟:
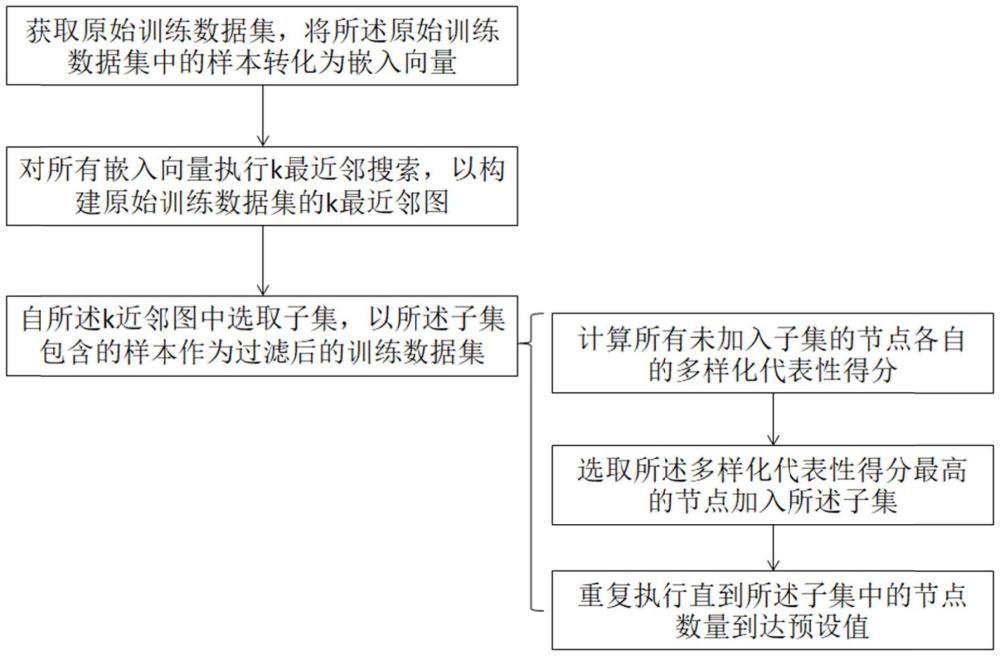
3、s1、獲取原始訓練數據集,將所述原始訓練數據集中的樣本轉化為嵌入向量;
4、s2、對所有嵌入向量執行k最近鄰搜索,以構建原始訓練數據集的k最近鄰圖;
5、s3、自所述k近鄰圖中選取子集,以所述子集包含的樣本作為過濾后的訓練數據集,選取子圖的方法包括:
6、s31、計算所有未加入子集的節點各自的多樣化代表性得分;
7、s32、選取所述多樣化代表性得分最高的節點加入所述子集;
8、s33、重復執行步驟s31-s32,直到所述子集中的節點數量到達預設值。
9、在一些實施例中,所述多樣化代表性得分的計算表示為:
10、x=a-b,其中x表示目標節點的多樣化代表性得分,a表示k最近鄰圖中與目標節點有邊且不屬于所述子集的節點的個數,b表示k最近鄰圖中與目標節點有邊且屬于所述子集的節點的個數。
11、在一些實施例中,所述k最近鄰圖通過faiss庫或者raft算法構建。
12、在一些實施例中,所述過濾后的訓練數據集用于大模型指令調優階段的訓練。
13、在一些實施例中,所述方法以插播的形式應用于下游模型的訓練。
14、本發明第二方面實施例提供一種大模型訓練數據過濾裝置,包括:
15、轉化模塊,用于獲取原始訓練數據集,將所述原始訓練數據集中的樣本轉化為嵌入向量;
16、knn構建模塊,對所有嵌入向量執行k最近鄰搜索,以構建原始訓練數據集的k最近鄰圖;
17、過濾模塊,自所述k近鄰圖中選取子集,以所述子集包含的樣本作為過濾后的訓練數據集,選取子圖的方法包括:
18、s31、計算所有未加入子集的節點各自的多樣化代表性得分;
19、s32、選取所述多樣化代表性得分最高的節點加入所述子集;
20、s33、重復執行步驟s31-s32,直到所述子集中的節點數量到達預設值。
21、本發明第三方面實施例提供一種電子設備,包括存儲器和處理器,所述存儲器存儲有計算機程序,所述計算機程序被所述處理器執行時實現如上任一實施例所述的大模型訓練數據過濾方法。
22、本發明第四方面實施例提供一種計算機可讀存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現如上任一實施例所述的大模型訓練數據過濾方法。
23、本發明以上實施例至少具有以下有益效果:
24、1、本發明實施例通過對原始訓練數據集中的樣本構建k最近鄰圖(knn圖),然后通過貪心算法對knn圖進行切割,也就是對原始訓練數據集的修剪,并且通過多樣化代表性得分的計算使得修剪得到的數據集能夠對原始訓練數據集的特征實現多樣性代表。
25、2、本發明實施例是一種對于數據集的通用的、計算高效的修剪方法,避免了全數據集訓練的需要,并且在降低壓縮成本的同時保持了數據訓練的有效性。
26、3、本發明實施例可以部署在一個gpu上處理數百萬樣本的數據集。
技術特征:
1.一種大模型訓練數據過濾方法,其特征在于,包括以下步驟:
2.根據權利要求1所述的大模型訓練數據過濾方法,其特征在于:所述多樣化代表性得分的計算表示為:
3.根據權利要求1所述的大模型訓練數據過濾方法,其特征在于:所述k最近鄰圖通過faiss庫或者raft算法構建。
4.根據權利要求1所述的大模型訓練數據過濾方法,其特征在于:所述過濾后的訓練數據集用于大模型指令調優階段的訓練。
5.根據權利要求1所述的大模型訓練數據過濾方法,其特征在于:所述方法以插播的形式應用于下游模型的訓練。
6.一種大模型數據過濾裝置,其特征在于,包括:
7.一種電子設備,其特征在于,包括存儲器和處理器,所述存儲器存儲有計算機程序,所述計算機程序被所述處理器執行時實現如權利要求1-5任一項所述的大模型訓練數據過濾方法。
8.一種計算機可讀存儲介質,其特征在于,其上存儲有計算機程序,所述計算機程序被處理器執行時實現如權利要求1-5任一項所述的大模型訓練數據過濾方法。
技術總結
本發明涉及一種大模型訓練數據過濾方法、裝置、設備及介質,屬于數據壓縮技術領域,解決了現有技術中數據過濾存在計算成本高的問題。本發明技術方案主要包括:S1、獲取原始訓練數據集,將所述原始訓練數據集中的樣本轉化為嵌入向量;S2、對所有嵌入向量執行k最近鄰搜索,以構建原始訓練數據集的k最近鄰圖;S3、自所述k近鄰圖中選取子集,以所述子集包含的樣本作為過濾后的訓練數據集,選取子圖的方法包括:S31、計算所有未加入子集的節點各自的多樣化代表性得分;S32、選取所述多樣化代表性得分最高的節點加入所述子集;S33、重復執行步驟S31?S32,直到所述子集中的節點數量到達預設值。
技術研發人員:陳澤毅,劉瀟,張鵬
受保護的技術使用者:北京智譜華章科技有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!