對話提示文本重生成方法、裝置、電子設備及存儲介質與流程
本發明涉及自然語言領域,具體涉及一種對話提示文本重生成方法、裝置、電子設備及存儲介質。
背景技術:
1、隨著自然語言處理技術的不斷發展,語言模型技術的應用越來越廣泛。語言模型是一種可訓練的算法,可以生成符合語言規則的文本。最近幾年,通過使用大規模訓練數據和深度學習技術,語言模型的性能得到了大幅提升。在實際應用中,語言模型的回復質量往往受到多種因素的影響,其中包括上下文信息、對話歷史、用戶意圖等。為了提高語言模型的回復質量,目前研究人員提出了如下方法:基于對話歷史的方法,通過對之前的對話歷史進行分析和處理,生成相應的提示,以幫助大語言模型更好地理解上下文信息和用戶意圖。
2、然而,在實際應用中,上下文信息和對話歷史的質量和數量往往是不穩定的。有時候,用戶提供的上下文信息和對話歷史非常詳細,可以幫助語言模型生成準確的回復;而有時候,用戶提供的上下文信息和對話歷史非常簡略,或者對話歷史中包含了無關的信息,這會降低語言模型的回復質量。因此,當前的對話提示文本重生成技術通常生成一些靜態的、固定的提示序列,依賴于預定義的模板,可能會導致大語言模型回復的準確性和可靠性較低,并且,當前的基于深度學習的提示生成技術通常需要大量的訓練數據和計算資源,這也限制了其在實際應用中的可行性和效率。
技術實現思路
1、本發明實施例提供一種對話提示文本重生成方法、裝置、電子設備及存儲介質,用以解決對于對話信息生成的提示文本的準確性低下的問題。
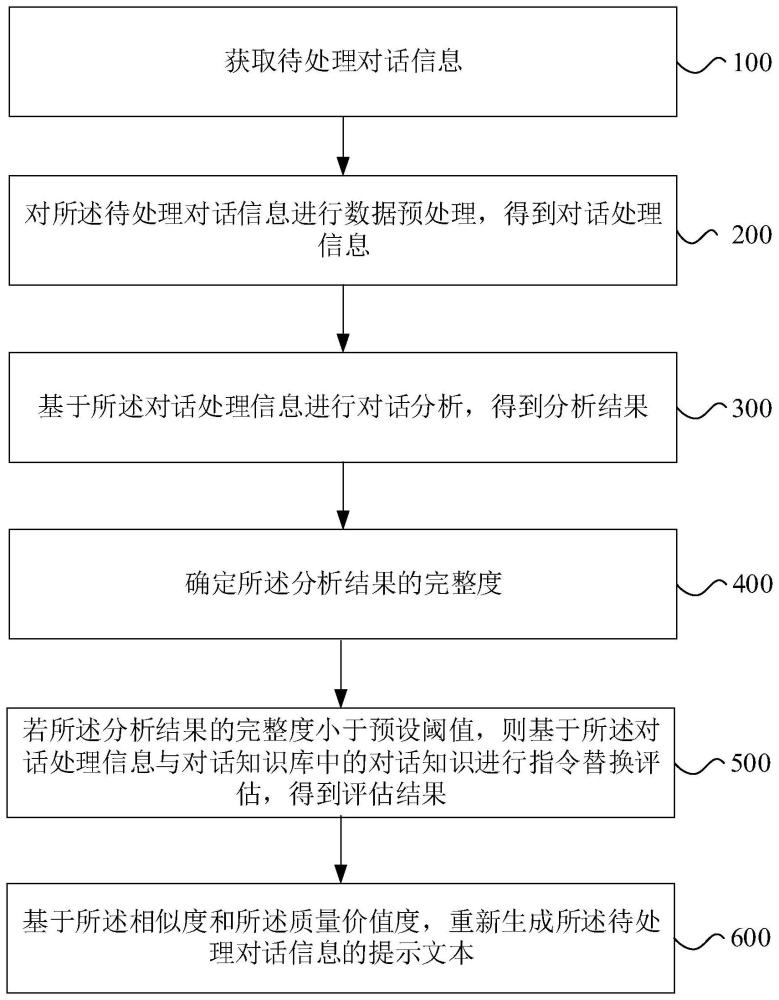
2、第一方面,本發明實施例提供一種對話提示文本重生成方法,包括:
3、獲取待處理對話信息;
4、對所述待處理對話信息進行數據預處理,得到對話處理信息;
5、基于所述對話處理信息進行對話分析,得到分析結果;所述分析結果包括歷史分析結果、意圖分析結果、背景分析結果和語言分析結果;
6、確定所述分析結果的完整度;
7、若所述分析結果的完整度小于預設閾值,則基于所述對話處理信息與對話知識庫中的對話知識進行指令替換評估,得到評估結果;所述評估結果包括所述對話處理信息與所述對話知識之間的相似度和所述對話處理信息與所述對話知識進行替換的質量價值度;
8、基于所述相似度和所述質量價值度,重新生成所述待處理對話信息的提示文本。
9、在一個實施例中,所述基于所述對話處理信息與對話知識庫中的對話知識進行指令替換評估,得到評估結果,包括:
10、對所述對話處理信息進行非關鍵字提取,得到非關鍵信息;
11、將所述非關鍵信息進行詞向量化處理,得到非關鍵向量;
12、基于所述非關鍵向量與對話知識庫中的對話知識進行點積運算,得到所述相似度和所述質量價值度。
13、在一個實施例中,所述基于所述相似度和所述質量價值度,重新生成所述待處理對話信息的提示文本,包括:
14、基于所述相似度和所述質量價值度,確定目標對話知識;
15、基于所述目標對話知識,對所述分析結果進行信息補全處理,得到目標補全信息;
16、基于所述目標補全信息,重新生成所述待處理對話信息的提示文本。
17、在一個實施例中,所述基于所述相似度和所述質量價值度,確定目標對話知識,包括:
18、若確定所述相似度大于預設相似閾值,則將最大相似度的對話知識確定為初始對話知識;
19、基于所述初始對話知識和所述質量價值度,確定目標對話知識。
20、在一個實施例中,所述基于所述初始對話知識和所述質量價值度,確定目標對話知識,包括:
21、若確定所述質量價值度大于預設質量價值閾值,則將質量價值度最大的所述初始對話知識確定為目標對話知識。
22、在一個實施例中,所述基于所述相似度和所述質量價值度,重新生成所述待處理對話信息的提示文本之后,包括:
23、確定用戶的回復反饋結果;
24、基于所述回復反饋結果,評估目標補全信息的質量;
25、基于所述評估目標補全信息的質量,對所述對話知識進行修正,得到新的對話知識。
26、在一個實施例中,所述基于所述對話處理信息進行對話分析,得到分析結果,包括:
27、對所述對話處理信息進行關鍵字提取,得到關鍵信息;
28、基于對話處理信息和所述關鍵信息進行上下文分析,得到歷史分析結果;
29、基于對話處理信息和所述關鍵信息進行指令識別,得到意圖分析結果;
30、基于對話處理信息和所述關鍵信息進行背景識別,得到背景分析結果;
31、基于對話處理信息和所述關鍵信息進行語言識別,得到語言分析結果。
32、第二方面,本發明實施例提供一種對話提示文本重生成裝置,包括:
33、獲取模塊,用于獲取待處理對話信息;
34、預處理模塊,用于對所述待處理對話信息進行數據預處理,得到對話處理信息;
35、分析模塊,用于基于所述對話處理信息進行對話分析,得到分析結果;所述分析結果包括歷史分析結果、意圖分析結果、背景分析結果和語言分析結果;
36、確定模塊,用于確定所述分析結果的完整度;
37、評估模塊,用于若所述分析結果的完整度小于預設閾值,則基于所述對話處理信息與對話知識庫中的對話知識進行指令替換評估,得到評估結果;所述評估結果包括所述對話處理信息與所述對話知識之間的相似度和所述對話處理信息與所述對話知識進行替換的質量價值度;
38、提示文本生成模塊,用于基于所述相似度和所述質量價值度,重新生成所述待處理對話信息的提示文本。
39、第三方面,本發明實施例提供一種電子設備,包括處理器和存儲有計算機程序的存儲器,所述處理器執行所述程序時實現第一方面所述的對話提示文本重生成方法。
40、第四方面,本發明實施例提供一種存儲介質,所述存儲介質為計算機可讀存儲介質,包括計算機程序,所述計算機程序被處理器執行時實現第一方面所述的對話提示文本重生成方法。
41、本發明實施例提供的對話提示文本重生成方法、裝置、電子設備及存儲介質,基于當前對話信息進行對話分析得到的分析結果,可以提高大語言模型回復的針對性和個性化程度,進而基于對話處理信息進行評估得到的替換相似性和質量代價,可以實現系統的自適應學習,優化生成提示文本,提高了提示文本的準確性和可靠性,從而提高了大語言模型回復的準確性和可靠性,并且,通過自適應學習實現提示文本優化,無需大量的訓練數據和計算資源,提高了生成提示文本的效率和實用性。
技術特征:
1.一種對話提示文本重生成方法,其特征在于,包括:
2.根據權利要求1所述的對話提示文本重生成方法,其特征在于,所述基于所述對話處理信息與對話知識庫中的對話知識進行指令替換評估,得到評估結果,包括:
3.根據權利要求1所述的對話提示文本重生成方法,其特征在于,所述基于所述相似度和所述質量價值度,重新生成所述待處理對話信息的提示文本,包括:
4.根據權利要求3所述的對話提示文本重生成方法,其特征在于,所述基于所述相似度和所述質量價值度,確定目標對話知識,包括:
5.根據權利要求4所述的對話提示文本重生成方法,其特征在于,所述基于所述初始對話知識和所述質量價值度,確定目標對話知識,包括:
6.根據權利要求1所述的對話提示文本重生成方法,其特征在于,所述基于所述相似度和所述質量價值度,重新生成所述待處理對話信息的提示文本之后,包括:
7.根據權利要求1-6任一項所述的對話提示文本重生成方法,其特征在于,所述基于所述對話處理信息進行對話分析,得到分析結果,包括:
8.一種對話提示文本重生成裝置,其特征在于,包括:
9.一種電子設備,包括處理器和存儲有計算機程序的存儲器,其特征在于,所述處理器執行所述計算機程序時實現權利要求1至7任一項所述的對話提示文本重生成方法。
10.一種存儲介質,所述存儲介質為計算機可讀存儲介質,包括計算機程序,其特征在于,所述計算機程序被處理器執行時實現權利要求1至7任一項所述的對話提示文本重生成方法。
技術總結
本發明涉及自然語言領域,提供一種對話提示文本重生成方法、裝置、電子設備及存儲介質,包括:獲取待處理對話信息;對待處理對話信息進行數據預處理,得到對話處理信息;基于對話處理信息進行對話分析,得到分析結果;確定分析結果的完整度;若分析結果的完整度小于預設閾值,則基于對話處理信息與對話知識庫中的對話知識進行指令替換評估,得到評估結果;基于相似度和質量價值度,重新生成待處理對話信息的提示文本。本發明實施例提供的對話提示文本重生成方法,基于對話處理信息進行評估得到的替換相似性和質量代價,可以實現系統的自適應學習,優化生成提示文本,提高提示文本的準確性和可靠性,從而提高大語言模型回復的準確性和可靠性。
技術研發人員:周勛,王曉征,郭岳,潘宇虹,史露強
受保護的技術使用者:中國移動通信集團浙江有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!