基于參數微調的模型訓練方法、裝置、設備及存儲介質與流程
本申請涉及機器學習領域,尤其涉及一種基于參數微調的模型訓練方法、裝置、設備及存儲介質。
背景技術:
1、隨著人工智能技術的迅速發展,智能化應用在多個領域中得到了廣泛的應用。其中,transformer作為一種重要的深度學習模型架構,已經在自然語言處理、計算機視覺和語音識別等領域取得了重大的突破,該transformer是指通過自注意力機制(self-attention)和位置編碼(position?encoding)來捕捉輸入序列中的長距離依賴關系的深度學習架構。然而,由于以transformer為基礎的大模型參數量龐大,其全參數的訓練計算成本顯著增加,對計算資源和內存的要求也極高。為了解決大模型的高計算開銷問題,參數有效微調技術應運而生。相關技術中,參數有效微調方法通常為矩陣低秩分解法,比如adalora(adaptive?budget?allocation?for?parameter?efficient?fine-tuning,參數有效微調的自適應預算分配)和fact(factor-tuning?for?lightweight?adaptation?onvision?transformer,視覺transformer上輕量級自適應的因子調整)。但是這兩種方法存在如下問題:
2、adalora的缺點在于其只能對矩陣進行分解從而進行微調。這限制了adalora在某些場景下的適用性和靈活性,因為并不是所有模型參數都可以簡單地表示為矩陣形式。adalora適用于能夠被表示為矩陣形式的模型參數,例如線性層、卷積層的權重、transformer中的qkv矩陣等。但對于某些模型參數,特別是非標準的模型結構或自定義的層,可能無法直接進行矩陣分解,從而限制了adalora在這些情況下的應用。
3、fact方法可以很好地對張量進行分解,但在如何分配更好的秩使模型微調結果最優上仍有局限性,在實際應用中,需要仔細權衡模型性能和資源開銷,同時根據具體任務和數據的特點來調整張量分解的秩,以獲得更好的微調結果。
技術實現思路
1、有鑒于此,本申請實施例提供了一種基于參數微調的模型訓練方法、裝置、設備及存儲介質,旨在提升模型的微調性能。
2、本申請實施例的技術方案是這樣實現的:
3、第一方面,本申請實施例提供了一種基于參數微調的模型訓練方法,包括:
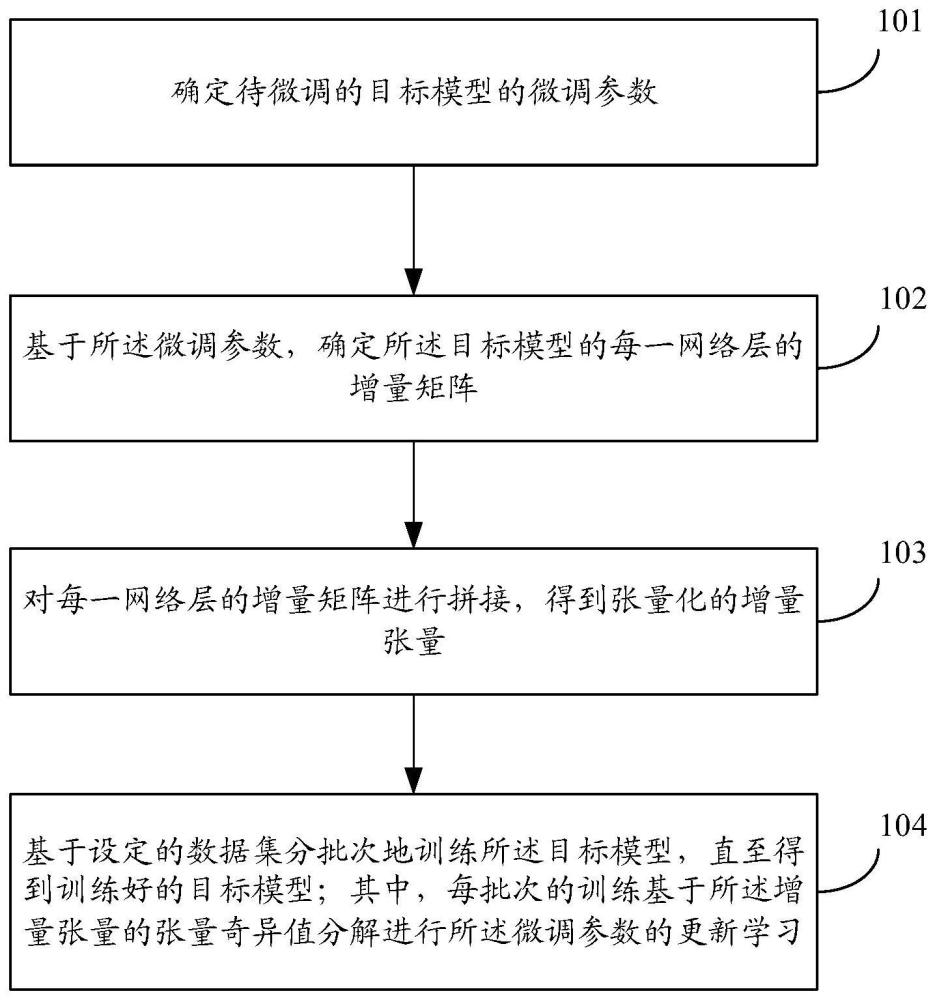
4、確定待微調的目標模型的微調參數;
5、基于所述微調參數,確定所述目標模型的每一網絡層的增量矩陣;
6、對每一網絡層的增量矩陣進行拼接,得到張量化的增量張量;
7、基于設定的數據集分批次地訓練所述目標模型,直至得到訓練好的目標模型;其中,每批次的訓練基于所述增量張量的張量奇異值分解進行所述微調參數的更新學習。
8、上述方案中,所述基于設定的數據集分批次地訓練所述目標模型,包括:
9、針對當前批次的訓練數據,基于對角張量的秩,對所述增量張量基于張量奇異值分解,得到左正交張量和右正交張量,并基于所述左正交張量和所述右正交張量更新學習所述微調參數。
10、上述方案中,所述基于所述左正交張量和所述右正交張量更新學習所述微調參數,包括:
11、基于正則項進行所述微調參數的更新學習,使得所述左正交張量和所述右正交張量均滿足正交性。
12、上述方案中,所述方法還包括:
13、求取當前批次的所述微調參數的平滑度和不確定性度;
14、基于所述平滑度和所述不確定性度,確定所述當前批次的所述增量張量的重要性分數;
15、基于當前批次的所述重要性分數和上一批次的所述重要性分數,確定當前批次的所述對角張量的秩。
16、上述方案中,求取當前批次的所述微調參數的平滑度,包括:
17、基于第一權重超參數、上一批次的所述微調參數的平滑度和當前批次的損失梯度的絕對值,確定當前批次的所述微調參數的平滑度。
18、上述方案中,求取當前批次的所述微調參數的不確定性度,包括:
19、基于第二權重超參數、上一批次的所述微調參數的不確定性度、當前批次的損失梯度的絕對值和當前批次的所述微調參數的平滑度,確定當前批次的所述微調參數的不確定性度。
20、上述方案中,張量奇異值分解為采用瘦張量奇異值分解(skinny?tensor-singular?value?decomposition,skinny?t-svd)方法進行的張量分解。
21、第二方面,本申請實施例提供了一種基于參數微調的模型訓練裝置,包括:
22、第一確定模塊,用于確定待微調的目標模型的微調參數;
23、第二確定模塊,用于基于所述微調參數,確定所述目標模型的每一網絡層的增量矩陣;
24、拼接模塊,用于對每一網絡層的增量矩陣進行拼接,得到張量化的增量張量;
25、訓練模塊,用于基于設定的數據集分批次地訓練所述目標模型,直至得到訓練好的目標模型;其中,每批次的訓練基于所述增量張量的張量奇異值分解進行所述微調參數的更新學習。
26、第三方面,本申請實施例提供了一種電子設備,包括:處理器和用于存儲能夠在處理器上運行的計算機程序的存儲器,其中,所述處理器用于運行計算機程序時,執行本申請實施例第一方面所述方法的步驟。
27、第四方面,本申請實施例提供了一種計算機存儲介質,所述計算機存儲介質上存儲有計算機程序,所述計算機程序被處理器執行時,實現本申請實施例第一方面所述方法的步驟。
28、本申請實施例提供的技術方案,確定待微調的目標模型的微調參數;基于微調參數,確定目標模型的每一網絡層的增量矩陣;對每一網絡層的增量矩陣進行拼接,得到張量化的增量張量;基于設定的數據集分批次地訓練目標模型,直至得到訓練好的目標模型;其中,每批次的訓練基于增量張量的張量奇異值分解進行微調參數的更新學習。本申請實施例中,由于將每一網絡層的增量矩陣拼接后得到張量化的增量張量,并在此基礎上進行張量分解和更新學習,可以顯著減少計算量,使得目標模型的微調過程更加高效,如此,能夠在保持模型性能的同時,有效降低計算成本,進而為在資源有限的情況下實現模型優化提供了可行方案。
技術特征:
1.一種基于參數微調的模型訓練方法,其特征在于,包括:
2.根據權利要求1所述的方法,其特征在于,所述基于設定的數據集分批次地訓練所述目標模型,包括:
3.根據權利要求2所述的方法,其特征在于,所述基于所述左正交張量和所述右正交張量更新學習所述微調參數,包括:
4.根據權利要求2所述的方法,其特征在于,所述方法還包括:
5.根據權利要求4所述的方法,其特征在于,求取當前批次的所述微調參數的平滑度,包括:
6.根據權利要求4所述的方法,其特征在于,求取當前批次的所述微調參數的不確定性度,包括:
7.根據權利要求1所述的方法,其特征在于,張量奇異值分解為采用瘦張量奇異值分解skinny?t-svd方法進行的張量分解。
8.一種基于參數微調的模型訓練裝置,其特征在于,包括:
9.一種電子設備,其特征在于,包括:處理器和用于存儲能夠在處理器上運行的計算機程序的存儲器,其中,
10.一種計算機存儲介質,所述計算機存儲介質上存儲有計算機程序,其特征在于,所述計算機程序被處理器執行時,實現權利要求1至7任一項所述方法的步驟。
技術總結
本申請公開了一種基于參數微調的模型訓練方法、裝置、設備及存儲介質。該方法包括:確定待微調的目標模型的微調參數;基于微調參數,確定目標模型的每一網絡層的增量矩陣;對每一網絡層的增量矩陣進行拼接,得到張量化的增量張量;基于設定的數據集分批次地訓練目標模型,直至得到訓練好的目標模型;其中,每批次的訓練基于增量張量的張量奇異值分解進行微調參數的更新學習。由于將每一網絡層的增量矩陣拼接后得到張量化的增量張量,并在此基礎上進行張量分解和更新學習,可以顯著減少計算量,使得目標模型的微調過程更加高效,能夠在保持模型性能的同時,有效降低計算成本。
技術研發人員:楊喜鵬,陳茜,黃文輝,鄧超,馮俊蘭
受保護的技術使用者:中國移動通信有限公司研究院
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!