日志管理方法、裝置、電子設備及存儲介質與流程
本公開涉及計算機,尤其涉及一種日志管理方法、裝置、電子設備及存儲介質。
背景技術:
1、在現有技術中,常使用elk架構作為日志系統。elk是由實時全文搜索和分析引擎(elasticsearch,簡稱es)、搜集、分析和過濾日志工具(logstash)以及基于web的圖形界面(kibana)組成的核心套件架構。它的工作流程通常是將數據統一集中,然后使用logstash進行數據過濾和存儲到elasticsearch中,最終通過kibana進行展示和可視化,供運維者查看和決策。
2、然而,在實際開發中,這種架構存在以下問題。首先,logstash在數據規整和分類傳輸到elasticsearch過程中需要配置和校驗大量規則。而logstash在處理和校驗規則時主要依賴于正則表達式,由于logstash處理數據會較高的占用系統內存,會導致數據處理卡頓,數據處理不及時。
技術實現思路
1、本公開提供一種日志管理方法、裝置、電子設備及存儲介質,以解決相關技術中的問題。
2、本公開的第一方面實施例提出了一種日志管理方法,該方法包括:
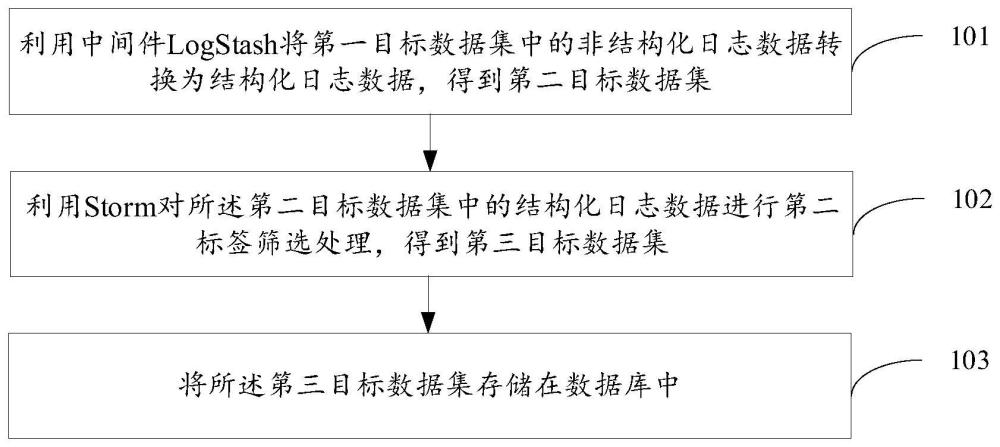
3、利用中間件logstash將第一目標數據集中的非結構化日志數據轉換為結構化日志數據,得到第二目標數據集;第二目標數據集中至少包括第二目標數據集中每條日志數據的第一標簽信息;
4、利用storm集群對第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集;第三目標數據集中至少包括第三目標數據集中每條日志數據的第二標簽信息;
5、將第三目標數據集存儲在數據庫中。
6、在本公開的一些實施例中,利用中間件logstash將第一目標數據集中的非結構化日志數據轉換為結構化日志數據之前,本公開提供的方法還包括:
7、利用kafka集群收集原始日志數據集;
8、根據業務需求,利用kafka集群對原始日志數據集進行第一標簽篩選處理,得到第一目標數據集;第一目標數據集中至少包括原始日志數據集中每條日志數據的第一標簽信息;
9、得到第二目標數據集之后,本公開提供的方法還包括:
10、將第二目標數據集發送至kafka集群。
11、在本公開的一些實施例中,利用storm集群對第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集,包括:
12、基于第二目標數據集中每條日志數據的第一標簽信息,根據storm集群的預設消費標簽,利用storm集群對第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集。
13、在本公開的一些實施例中,基于第二目標數據集中每條日志數據的第一標簽信息,根據storm集群的預設消費標簽,利用storm集群對第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集,包括:
14、從redis緩存中獲取storm集群的預設消費標簽;
15、根據storm集群的預設消費標簽包含的日志類型,利用分類算法將預設消費標簽包含的日志類型與第一標簽信息進行匹配,在第一標簽信息中篩選出與預設消費標簽包含的日志類型匹配的至少一個第二標簽信息;
16、確定第二標簽信息對應的結構化日志數據構成的集合為第三目標數據集。
17、在本公開的一些實施例中,將第三目標數據集存儲在數據庫中之后,本公開提供的方法還包括:
18、清除redis緩存。
19、在本公開的一些實施例中,將第三目標數據集存儲在數據庫中,包括:
20、將第三目標數據集存儲在es集群中。
21、在本公開的一些實施例中,將第三目標數據集存儲在es集群中之后,本公開提供的方法還包括:
22、通過kibana讀取es集群中的第三目標數據集,或/和,展示第三目標數據集。
23、本公開的第二方面實施例提出了一種日志管理裝置,該裝置包括:
24、轉換單元,用于利用中間件logstash將第一目標數據集中的非結構化日志數據轉換為結構化日志數據,得到第二目標數據集;第二目標數據集中至少包括第二目標數據集中每條日志數據的第一標簽信息;
25、第二標簽篩選處理單元,用于利用storm集群對第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集;第三目標數據集中至少包括第三目標數據集中每條日志數據的第二標簽信息;
26、存儲單元,用于將第三目標數據集存儲在數據庫中。
27、本公開的第三方面實施例提出了一種電子設備,包括:
28、至少一個處理器;以及與至少一個處理器通信連接的存儲器;其中,存儲器存儲有可被至少一個處理器執行的指令,指令被至少一個處理器執行,以使至少一個處理器能夠執行本公開第一方面實施例中描述的方法。
29、本公開的第四方面實施例提出了一種存儲有計算機指令的非瞬時計算機可讀存儲介質,其中,計算機指令用于使計算機執行本公開第一方面實施例中描述的方法。
30、綜上,本公開提出了一種日志管理方法、裝置、電子設備及存儲介質,該方法包括:利用中間件logstash將第一目標數據集中的非結構化日志數據轉換為結構化日志數據,得到第二目標數據集;第二目標數據集中至少包括第二目標數據集中每條日志數據的第一標簽信息;利用storm集群對第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集;第三目標數據集中至少包括第三目標數據集中每條日志數據的第二標簽信息;將第三目標數據集存儲在數據庫中。
31、通過本公開提供的方案,將處理器利用logstash對數據的運算更改為利用storm集群對數據進行運算,降低logstash的數據處理壓力,負載,防止數據卡頓,提高數據處理效率。
32、應當理解的是,以上的一般描述和后文的細節描述僅是示例性和解釋性的,并不能限制本公開。
技術特征:
1.一種日志管理方法,其特征在于,包括:
2.根據權利要求1所述的方法,其特征在于,所述利用中間件logstash將第一目標數據集中的非結構化日志數據轉換為結構化日志數據之前,所述的方法還包括:
3.根據權利要求2所述的方法,其特征在于,所述利用storm集群對所述第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集,包括:
4.根據權利要求3所述的方法,其特征在于,所述基于所述第二目標數據集中每條日志數據的第一標簽信息,根據所述storm集群的預設消費標簽,利用storm集群對所述第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集,包括:
5.根據權利要求4所述的方法,其特征在于,所述將所述第三目標數據集存儲在數據庫中之后,所述的方法還包括:
6.根據權利要求1至5中任一項所述的方法,其特征在于,所述將所述第三目標數據集存儲在數據庫中,包括:
7.根據權利要求6所述的方法,其特征在于,所述將所述第三目標數據集存儲在es集群中之后,所述的方法還包括:
8.一種日志管理裝置,其特征在于,包括:
9.一種電子設備,其特征在于,包括:
10.一種存儲有計算機指令的非瞬時計算機可讀存儲介質,其特征在于,所述計算機指令用于使所述計算機執行權利要求1至7中任一項所述的方法。
技術總結
本公開提出了一種日志管理方法、裝置、電子設備及存儲介質。所述的方法包括:利用中間件LogStash將第一目標數據集中的非結構化日志數據轉換為結構化日志數據,得到第二目標數據集;所述第二目標數據集中至少包括所述第二目標數據集中每條日志數據的第一標簽信息;利用Storm集群對所述第二目標數據集中的結構化日志數據進行第二標簽篩選處理,得到第三目標數據集;所述第三目標數據集中至少包括所述第三目標數據集中每條日志數據的第二標簽信息;將所述第三目標數據集存儲在數據庫中。
技術研發人員:王光波,劉曉斌,任云靜
受保護的技術使用者:中國移動通信集團貴州有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!