文檔相似度檢測方法、裝置、電子設備及存儲介質與流程
本發明涉及文檔識別,尤其涉及一種文檔相似度檢測方法、裝置、電子設備及存儲介質。
背景技術:
1、自動化的文本相似度檢測方法可以實現多維度的文本相似度檢測能力,代替人工審查,對上臺、訂購等流程實現自動化的篩查,發現隱患并且進行警示。為了適應對句式、短語、詞語的近似改寫來減少重復發現,借助ai能力對文本的理解能力,實現更準確的相似度檢測能力。
2、目前的文本相似度檢測方法通常為:基于相似矩陣的文本相似度檢測或基于word2vec詞向量模型的文本相似度檢測,上述方式中存在計算量較大,語義學習能力有限的問題,均為造成文檔的檢測準確率低、效率低的問題。
技術實現思路
1、本發明提供一種文檔相似度檢測方法、裝置、電子設備及存儲介質。
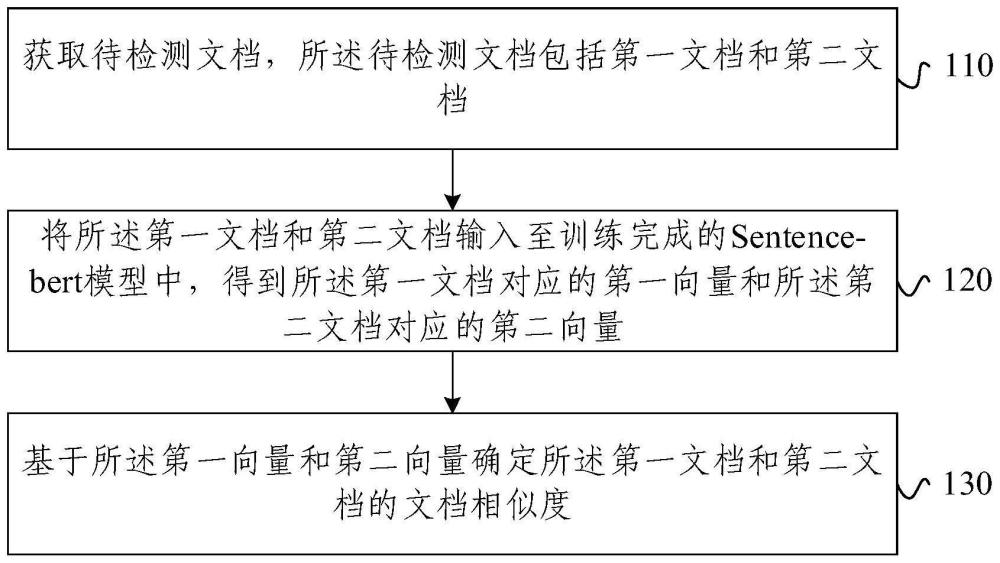
2、第一方面,本發明提供一種文檔相似度檢測方法,包括:
3、獲取待檢測文檔,所述待檢測文檔包括第一文檔和第二文檔;
4、將所述第一文檔和第二文檔輸入至訓練完成的sentence-bert模型中,得到所述第一文檔對應的第一向量和所述第二文檔對應的第二向量;
5、基于所述第一向量和第二向量確定所述第一文檔和第二文檔的文檔相似度;
6、其中,所述訓練完成的sentence-bert模型是對文檔數據集進行預處理,得到文檔樣本訓練集,并基于所述文檔樣本訓練集以及所述文檔樣本訓練集對應的樣本句向量生成結果進行訓練得到的。
7、根據本發明提供的一種文檔相似度檢測方法,所述訓練完成的sentence-bert模型的訓練方法包括:
8、獲取文檔數據集,對所述文檔數據集進行預處理,確定所述文檔樣本訓練集,所述文檔樣本訓練集包括第一文檔樣本和第二文檔樣本;
9、將所述第一文檔樣本和第二文檔樣本輸入至初始的sentence-bert模型中,得到第一句向量樣本和第二句向量樣本;
10、基于目標損失函數獲取模型迭代過程中的損失值,基于所述損失值對迭代過程的sentence-bert模型進行參數調整,直至模型收斂得到所述訓練完成的sentence-bert模型。
11、根據本發明提供的一種文檔相似度檢測方法,所述sentence-bert模型包括第一卷積網絡和第二卷積網絡,所述第一卷積神經網絡和第二神經網絡為孿生網絡;
12、所述將所述第一文檔樣本和第二文檔樣本輸入至初始的sentence-bert模型中,得到第一句向量樣本和第二句向量樣本,包括:
13、從所述文檔樣本訓練集中選取文檔序列,將所述文檔序列分割為第一文檔樣本和第二文檔樣本;
14、將所述第一文檔樣本輸入至所述第一卷積網絡中,得到所述第一句向量樣本,將所述第二文檔樣本輸入至所述第二卷積網絡中,得到所述第二句向量樣本。
15、根據本發明提供的一種文檔相似度檢測方法,將所述第一文檔樣本輸入至所述第一卷積網絡中,得到所述第一句向量樣本,將所述第二文檔樣本輸入至所述第二卷積網絡中,得到所述第二句向量樣本,包括:
16、將所述第一文檔樣本輸入至第一卷積網絡中,基于所述第一卷積網絡對所述第一文檔樣本進行字符編碼、句子編碼以及位置編碼,得到所述第一文檔樣本的各詞匯對應的詞向量,基于所述第一文檔樣本的分類標記和分隔標記,將所述詞向量進行組合得到所述第一句向量樣本;
17、將所述第二文檔樣本輸入至第二卷積網絡中,基于所述第二卷積網絡對所述第二文檔樣本進行字符編碼、句子編碼以及位置編碼,得到所述第二文檔樣本的各詞匯對應的詞向量,基于所述第二文檔樣本的分類標記和分隔標記,將所述詞向量進行組合得到所述第二句向量樣本。
18、根據本發明提供的一種文檔相似度檢測方法,所述對所述文檔數據集進行預處理,確定所述文檔樣本訓練集,包括:
19、去除所述文檔數據集中的無效數據,得到有效數據集;
20、對所述有效數據集的文檔實體進行抽取,得到實體數據集;
21、將所述實體數據拆分為句子集合,對所述句子集合中的完整句子進行標簽標注,得到每個所述完整句子對應的數據標簽;
22、基于目標比例對所述完整句子以及所述完整句子對應的數據標簽進行劃分,得到訓練數據集。
23、根據本發明提供的一種文檔相似度檢測方法,還包括:
24、確定所述句子集合中的數據樣本分布不均衡,基于數據增強方式對所述句子集合進行均衡擴充。
25、根據本發明提供的一種文檔相似度檢測方法,所述目標損失函數為focalloss損失函數;
26、所述基于目標損失函數獲取模型迭代過程中的損失值,包括:
27、確定所述focalloss損失函數的焦點因子,并獲取模型對正確類別的預測概率;
28、建立目標損失函數,并基于所述預測概率和交點因子確定所述損失值。
29、第二方面,本發明還提供一種文檔相似度檢測裝置,包括:
30、獲取模塊,用于獲取待檢測文檔,所述待檢測文檔包括第一文檔和第二文檔;
31、向量生成模塊,用于將所述第一文檔和第二文檔輸入至訓練完成的sentence-bert模型中,得到所述第一文檔對應的第一向量和所述第二文檔對應的第二向量;
32、相似度檢測模塊,用于基于所述第一向量和第二向量確定所述第一文檔和第二文檔的文檔相似度;
33、其中,所述訓練完成的sentence-bert模型是對文檔數據集進行預處理,得到文檔樣本訓練集,并基于所述文檔樣本訓練集以及所述文檔樣本訓練集對應的樣本句向量生成結果進行訓練得到的。
34、第三方面,本發明還提供一種電子設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的計算機程序,所述處理器執行所述程序時實現如上述任一種所述文檔相似度檢測方法。
35、第四方面,本發明還提供一種非暫態計算機可讀存儲介質,其上存儲有計算機程序,該計算機程序被處理器執行時實現如上述任一種所述文檔相似度檢測方法。
36、第五方面,本發明還提供一種計算機程序產品,包括計算機程序,所述計算機程序被處理器執行時實現如上述任一種所述文檔相似度檢測方法。
37、本發明提供的文檔相似度檢測方法、裝置、電子設備及存儲介質,通過將第一文檔和第二文檔輸入到訓練完成的sentence-bert模型進行句子-向量轉換,并根據生成的向量進行文檔相似度計算,從而得到第一文檔和第二文檔的文檔相似度,本實施例利用sentence-bert模型的孿生網絡的結構,對不同的輸入文檔進行編碼和向量轉換,對文檔比對中的特征進行交互融合學習,進一步提升語義理解能力,解決了相似度計算量較大且過程復雜,以及長文本中上下文聯系不緊密,語義學習理解能力不足的問題,提高了文檔檢測的準確度和效率。
技術特征:
1.一種文檔相似度檢測方法,其特征在于,包括:
2.根據權利要求1所述的文檔相似度檢測方法,其特征在于,所述訓練完成的sentence-bert模型的訓練方法包括:
3.根據權利要求2所述的文檔相似度檢測方法,其特征在于,所述sentence-bert模型包括第一卷積網絡和第二卷積網絡,所述第一卷積神經網絡和第二神經網絡為孿生網絡;
4.根據權利要求3所述的文檔相似度檢測方法,其特征在于,將所述第一文檔樣本輸入至所述第一卷積網絡中,得到所述第一句向量樣本,將所述第二文檔樣本輸入至所述第二卷積網絡中,得到所述第二句向量樣本,包括:
5.根據權利要求2所述的文檔相似度檢測方法,其特征在于,所述對所述文檔數據集進行預處理,確定所述文檔樣本訓練集,包括:
6.根據權利要求5所述的文檔相似度檢測方法,其特征在于,還包括:
7.根據權利要求5所述的文檔相似度檢測方法,其特征在于,所述目標損失函數為focalloss損失函數;
8.一種文檔相似度檢測裝置,其特征在于,包括:
9.一種電子設備,包括存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的計算機程序,其特征在于,所述處理器執行所述程序時實現如權利要求1至7任一項所述文檔相似度檢測方法。
10.一種非暫態計算機可讀存儲介質,其上存儲有計算機程序,其特征在于,所述計算機程序被處理器執行時實現如權利要求1至7任一項所述文檔相似度檢測方法。
技術總結
本發明提供一種文檔相似度檢測方法、裝置、電子設備及存儲介質,方法包括:獲取待檢測文檔,所述待檢測文檔包括第一文檔和第二文檔;將所述第一文檔和第二文檔輸入至訓練完成的Sentence?bert模型中,得到所述第一文檔對應的第一向量和所述第二文檔對應的第二向量;基于所述第一向量和第二向量確定所述第一文檔和第二文檔的文檔相似度,本發明解決了相似度計算量較大且過程復雜,以及長文本中上下文聯系不緊密,語義學習理解能力不足的問題,提高了文檔檢測的準確度和效率。
技術研發人員:馬愷琳
受保護的技術使用者:中國移動通信集團浙江有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!