工單信息抽取方法、裝置、計算機設備和存儲介質與流程
本申請涉及計算機,特別是涉及一種問答工單信息抽取方法、裝置、計算機設備、存儲介質和計算機程序產品。
背景技術:
1、隨著計算機技術的發展,出現了自然語言處理(nature?language?processing,nlp)技術,它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。自然語言處理是一門融語言學、計算機科學、數學于一體的科學。因此,這一領域的研究將涉及自然語言,即人們日常使用的語言,所以它與語言學的研究有著密切的聯系。自然語言處理技術通常包括文本處理、語義理解、機器翻譯、機器人問答、知識圖譜等技術。目前,一般可以通過自然語言處理的技術來自動從工單信息中提取出重要信息。
2、然而,目前的nlp生成模型主要以抽象式摘要的方式,生成工單中的重要信息,然而這種方法需要逐字生成提取結果,工單信息的提取效率較低。
技術實現思路
1、基于此,有必要針對上述技術問題,提供一種能夠提高工單信息抽取效率的工單信息抽取方法、裝置、計算機設備、計算機可讀存儲介質和計算機程序產品。
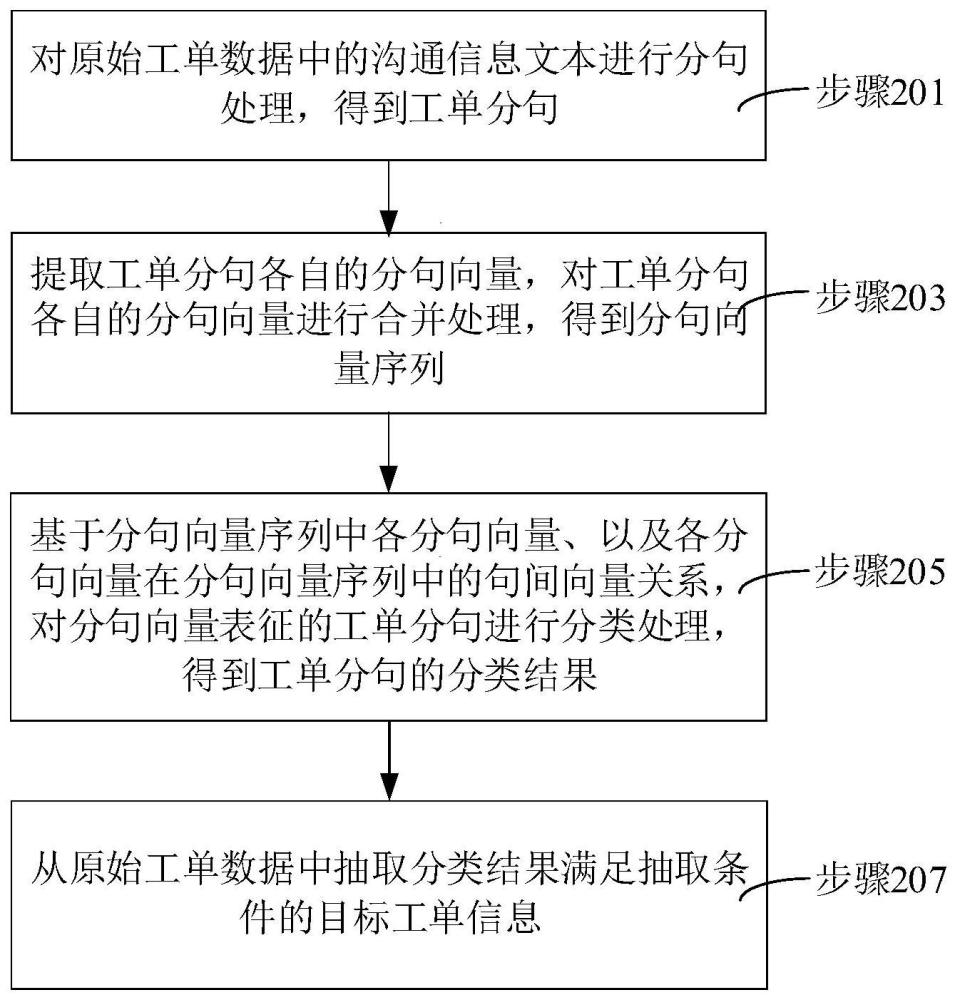
2、第一方面,本申請提供了一種工單信息抽取方法。所述方法包括:
3、對原始工單數據中的溝通信息文本進行分句處理,得到工單分句;
4、提取所述工單分句各自的分句向量,對所述工單分句各自的分句向量進行合并處理,得到分句向量序列;
5、基于所述分句向量序列中各分句向量、以及各分句向量在所述分句向量序列中的句間向量關系,對所述分句向量表征的工單分句進行分類處理,得到所述工單分句的分類結果;
6、從所述原始工單數據中抽取所述分類結果滿足抽取條件的目標工單信息,所述抽取條件包括所述分類結果為用戶問題和所述分類結果為解答方案。
7、第二方面,本申請還提供了一種工單信息抽取裝置。所述裝置包括:
8、工單分句模塊,用于對原始工單數據中的溝通信息文本進行分句處理,得到工單分句;
9、分句特征提取模塊,用于提取所述工單分句各自的分句向量,對所述工單分句各自的分句向量進行合并處理,得到分句向量序列;
10、分句分類模塊,用于基于所述分句向量序列中各分句向量、以及各分句向量在所述分句向量序列中的句間向量關系,對所述分句向量表征的工單分句進行分類處理,得到所述工單分句的分類結果;
11、信息提取模塊,用于從所述原始工單數據中抽取所述分類結果滿足抽取條件的目標工單信息,所述抽取條件包括所述分類結果為用戶問題和所述分類結果為解答方案。
12、第三方面,本申請還提供了一種計算機設備。所述計算機設備包括存儲器和處理器,所述存儲器存儲有計算機程序,所述處理器執行所述計算機程序時實現以下步驟:
13、對原始工單數據中的溝通信息文本進行分句處理,得到工單分句;
14、提取所述工單分句各自的分句向量,對所述工單分句各自的分句向量進行合并處理,得到分句向量序列;
15、基于所述分句向量序列中各分句向量、以及各分句向量在所述分句向量序列中的句間向量關系,對所述分句向量表征的工單分句進行分類處理,得到所述工單分句的分類結果;
16、從所述原始工單數據中抽取所述分類結果滿足抽取條件的目標工單信息,所述抽取條件包括所述分類結果為用戶問題和所述分類結果為解答方案。
17、第四方面,本申請還提供了一種計算機可讀存儲介質。所述計算機可讀存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現以下步驟:
18、對原始工單數據中的溝通信息文本進行分句處理,得到工單分句;
19、提取所述工單分句各自的分句向量,對所述工單分句各自的分句向量進行合并處理,得到分句向量序列;
20、基于所述分句向量序列中各分句向量、以及各分句向量在所述分句向量序列中的句間向量關系,對所述分句向量表征的工單分句進行分類處理,得到所述工單分句的分類結果;
21、從所述原始工單數據中抽取所述分類結果滿足抽取條件的目標工單信息,所述抽取條件包括所述分類結果為用戶問題和所述分類結果為解答方案。
22、第五方面,本申請還提供了一種計算機程序產品。所述計算機程序產品,包括計算機程序,該計算機程序被處理器執行時實現以下步驟:
23、對原始工單數據中的溝通信息文本進行分句處理,得到工單分句;
24、提取所述工單分句各自的分句向量,對所述工單分句各自的分句向量進行合并處理,得到分句向量序列;
25、基于所述分句向量序列中各分句向量、以及各分句向量在所述分句向量序列中的句間向量關系,對所述分句向量表征的工單分句進行分類處理,得到所述工單分句的分類結果;
26、從原始工單數據中抽取分類結果滿足抽取條件的目標工單信息,所述抽取條件包括所述分類結果為用戶問題和所述分類結果為解答方案。
27、上述工單信息抽取方法、裝置、計算機設備、存儲介質和計算機程序產品,通過先對原始工單數據中的溝通信息文本進行分句處理,得到工單中文本內容相應的各個工單分句,而后再提取工單分句各自的語義特征,得到分句向量,并對工單分句各自的分句向量進行合并處理,構建由原始工單數據中所有文本的分句組成的分句向量序列,而后基于分句向量序列中各分句向量、以及各分句向量在分句向量序列中的句間向量關系,通過分句的上下文關系來直接對分句向量表征的工單分句進行分類處理,得到工單分句的分類結果,從而從原始工單數據中抽取分類結果滿足抽取條件的目標工單信息。本申請通過先對原始工單數據進行分句,而后提取出分句各自的特征向量,并基于各分句向量的句間關系,來實現對工單分句的分類,并基于工單分句的分類結果識別出需要抽取的目標部分,完成對原始工單數據的數據抽取,通過分句分類處理的方式來替代生成式模型生成的方式來進行工單信息的數據抽取,可以有效提高工單數據抽取的效率。
技術特征:
1.一種工單信息抽取方法,其特征在于,所述方法包括:
2.根據權利要求1所述的方法,其特征在于,所述對原始工單數據中的溝通文本內容進進行分句處理,得到工單分句包括:
3.根據權利要求1所述的方法,其特征在于,所述提取所述工單分句各自的分句向量,對所述工單分句各自的分句向量進行合并處理,得到分句向量序列包括:
4.根據權利要求3所述的方法,其特征在于,所述確定所述工單分句各自的詞向量列表包括:
5.根據權利要求3所述的方法,其特征在于,所述對各所述詞向量列表進行特征提取處理,得到工單分句各自的分句向量包括:
6.根據權利要求1所述的方法,其特征在于,所述基于所述分句向量序列中各分句向量、以及各分句向量在所述分句向量序列中的句間向量關系,對所述分句向量表征的工單分句進行分類處理,得到所述工單分句的分類結果包括:
7.根據權利要求1所述的方法,其特征在于,所述方法還包括:
8.根據權利要求7所述的方法,其特征在于,所述通過工單文本分類模型提取所述工單分句各自的分句向量,對所述工單分句各自的分句向量進行合并處理,得到分句向量序列之前,還包括:
9.根據權利要求1所述的方法,其特征在于,所述基于所述分句向量序列中各分句向量、以及各分句向量在所述分句向量序列中的句間向量關系,對所述分句向量表征的工單分句進行分類處理,得到所述工單分句的分類結果包括:
10.根據權利要求1至9任意一項所述的方法,其特征在于,所述方法還包括:
11.根據權利要求1至9任意一項所述的方法,其特征在于,所述分類結果包括分類標簽,所述從所述原始工單數據中抽取所述分類結果滿足抽取條件的目標工單信息包括:
12.一種工單信息抽取裝置,其特征在于,所述裝置包括:
13.一種計算機設備,包括存儲器和處理器,所述存儲器存儲有計算機程序,其特征在于,所述處理器執行所述計算機程序時實現權利要求1至11中任一項所述的方法的步驟。
14.一種計算機可讀存儲介質,其上存儲有計算機程序,其特征在于,所述計算機程序被處理器執行時實現權利要求1至11中任一項所述的方法的步驟。
15.一種計算機程序產品,包括計算機程序,其特征在于,所述計算機程序被處理器執行時實現權利要求1至11中任一項所述的方法的步驟。
技術總結
本申請涉及一種工單信息抽取方法、裝置、計算機設備、存儲介質和計算機程序產品。所述方法包括:對原始工單數據中的溝通信息文本進行分句處理,得到工單分句;提取工單分句各自的分句向量,對工單分句各自的分句向量進行合并處理,得到分句向量序列;基于分句向量序列中各分句向量、以及各分句向量在分句向量序列中的句間向量關系,對分句向量表征的工單分句進行分類處理,得到工單分句的分類結果;從原始工單數據中抽取分類結果滿足抽取條件的目標工單信息。本申請通過分句分類處理的方式來替代生成式模型生成的方式來進行工單信息的數據抽取,可以有效提高工單數據抽取的效率。
技術研發人員:智緒達,吳熙,趙九州
受保護的技術使用者:騰訊科技(深圳)有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!