流式關聯分析方法及裝置、計算機存儲介質及終端與流程
本申請涉及大數據處理,尤其涉及一種流式關聯分析方法及裝置、計算機可讀存儲介質及終端。
背景技術:
1、隨著科技及社會的不斷發展,各類數據呈井噴式地增長,人們對于海量數據的處理以及數據安全也愈發重視。目前,常見的基于批處理、流處理的大數據分析技術有hadoop、stom、spark、flink等。但是,上述部分技術在流處理時,所采用的分流算法在隨著數據量的不斷增加時,無法保證數據分析的實時性。
2、需要說明的是,在上述背景技術部分公開的信息僅用于加強對本申請的背景的理解,因此可以包括不構成對本領域普通技術人員已知的現有技術的信息。
技術實現思路
1、本申請的目的在于提供一種流式關聯分析方法及裝置、計算機可讀存儲介質及設備,通過一級關聯分析引擎和二級關聯分析引擎的結合對數據進行降級處理,至少能夠在一定程度上提高對數據的吞吐量,進而提高對數據分析的實時性。
2、本申請的其他特性和優點將通過下面的詳細描述變得顯然,或部分地通過本申請的實踐而習得。
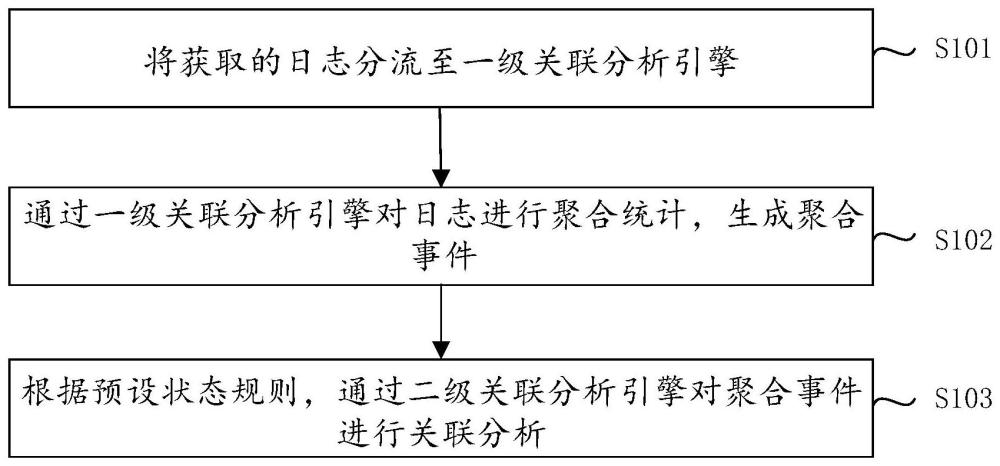
3、根據本申請的第一個方面,提供一種流式關聯分析方法,應用于關聯分析引擎,所述關聯分析引擎包括一級關聯分析引擎和二級關聯分析引擎,所述方法包括:將獲取的日志分流至所述一級關聯分析引擎;通過所述一級關聯分析引擎對所述日志進行聚合統計,生成聚合事件;根據預設狀態規則,通過所述二級關聯分析引擎對所述聚合事件進行關聯。
4、在本申請一個實施例中,上述所述通過所述一級關聯分析引擎對所述日志進行聚合統計,生成聚合事件,包括:獲取聚合策略,所述聚合策略為根據預設條件和字段配置的聚合規則;根據所述聚合策略,在預設時間窗口期內通過所述一級關聯分析引擎對所述日志進行聚合統計,生成所述聚合事件。
5、在本申請一個實施例中,上述所述通過所述一級關聯分析引擎對所述日志進行聚合統計,生成聚合事件之前,所述方法還包括:根據預設無狀態觸發類規則,通過所述一級關聯分析引擎對所述日志進行分析匹配,若匹配成功,則生成告警;若匹配失敗,則根據預設過濾規則,對分流后的所述日志進行過濾。
6、在本申請一個實施例中,上述所述根據所述聚合策略,在預設時間窗口期內通過所述一級關聯分析引擎對所述日志進行聚合統計,生成所述聚合事件,包括:根據所述聚合策略,在預設時間窗口期內通過所述一級關聯分析引擎對過濾后的所述日志進行聚合統計,生成所述聚合事件。
7、在本申請一個實施例中,上述所述根據預設狀態規則,通過所述二級關聯分析引擎對所述聚合事件進行關聯分析之后,所述方法還包括:根據預設告警規則,通過所述二級關聯分析引擎對關聯分析后的所述聚合事件進行匹配,若匹配成功,則生成告警。
8、在本申請一個實施例中,上述所述一級關聯分析引擎可橫向拓展至少兩個,所述二級關聯分析引擎可橫向拓展至少兩個。
9、在本申請一個實施例中,上述所述一級關聯分析引擎為無狀態關聯分析引擎,所述二級關聯分析引擎為有狀態關聯分析引擎。
10、根據本申請的第二個方面,提供一種流式關聯分析裝置,應用于關聯分析引擎,所述關聯分析引擎包括一級關聯分析引擎和二級關聯分析引擎,所述裝置包括:數據采集模塊,用于將獲取的日志分流至所述一級關聯分析引擎;一級關聯分析引擎模塊,用于通過所述一級關聯分析引擎對所述日志進行聚合統計,生成聚合事件;二級關聯分析引擎模塊,用于根據預設狀態規則,通過所述二級關聯分析引擎對所述聚合事件進行關聯分析。
11、根據本申請的第三個方面,提供一種終端,包括:存儲器、處理器以及存儲在上述存儲器中并可在上述處理器上運行的計算機程序,上述處理器執行上述計算機程序時實現上述第一個方面所述的流式關聯分析方法。
12、根據本申請的第四個方面,提供一種計算機可讀存儲介質,其上存儲有計算機程序,上述計算機程序被處理器執行時實現上述第一個方面所述的流式關聯分析方法。
13、本申請的實施例所提供的流式關聯分析方法及裝置、計算機存儲介質及終端,具備以下技術效果:將獲取的日志分流至一級關聯分析引擎;通過一級關聯分析引擎對日志進行聚合統計,生成聚合事件;根據預設狀態規則,通過二級關聯分析引擎對聚合事件進行關聯分析。通過一級關聯分析引擎和二級關聯分析引擎的結合對數據進行降級處理,至少能夠在一定程度上提高對數據的吞吐量,進而提高對數據分析的實時性。
14、應當理解的是,以上的一般描述和后文的細節描述僅是示例性和解釋性的,并不能限制本申請。
技術特征:
1.一種流式關聯分析方法,其特征在于,應用于關聯分析引擎,所述關聯分析引擎包括一級關聯分析引擎和二級關聯分析引擎,所述方法包括:
2.根據權利要求1所述的方法,其特征在于,所述通過所述一級關聯分析引擎對所述日志進行聚合統計,生成聚合事件,包括:
3.根據權利要求2所述的方法,其特征在于,所述通過所述一級關聯分析引擎對所述日志進行聚合統計,生成聚合事件之前,所述方法還包括:
4.根據權利要求3所述的方法,其特征在于,所述根據所述聚合策略,在預設時間窗口期內通過所述一級關聯分析引擎對所述日志進行聚合統計,生成所述聚合事件,包括:
5.根據權利要求1所述的方法,其特征在于,所述根據預設狀態規則,通過所述二級關聯分析引擎對所述聚合事件進行關聯分析之后,所述方法還包括:
6.根據權利要求1至5中任一項所述的方法,其特征在于,所述一級關聯分析引擎可橫向拓展至少兩個,所述二級關聯分析引擎可橫向拓展至少兩個。
7.根據權利要求1至6中任一項所述的方法,其特征在于,所述一級關聯分析引擎為無狀態關聯分析引擎,所述二級關聯分析引擎為有狀態關聯分析引擎。
8.一種流式關聯分析裝置,其特征在于,應用于關聯分析引擎,所述關聯分析引擎包括一級關聯分析引擎和二級關聯分析引擎,所述裝置包括:
9.一種終端,包括存儲器、處理器以及存儲在所述存儲器中并可在所述處理器上運行的計算機程序,其特征在于,所述處理器執行所述計算機程序時實現如權利要求1至7中任一項所述的流式關聯分析方法。
10.一種計算機可讀存儲介質,其上存儲有計算機程序,其特征在于,所述計算機程序被處理器執行時實現如權利要求1至7中任一項所述的流式關聯分析方法。
技術總結
本申請實施例提供了一種流式關聯分析方法及裝置、介質及終端,涉及大數據處理技術領域。應用于關聯分析引擎,關聯分析引擎包括一級關聯分析引擎和二級關聯分析引擎,方法包括:將獲取的日志分流至一級關聯分析引擎;通過一級關聯分析引擎對日志進行聚合統計,生成聚合事件;根據預設狀態規則,通過二級關聯分析引擎對聚合事件進行關聯分析。根據本申請實施例的技術方案,通過一級關聯分析引擎和二級關聯分析引擎的結合對數據進行降級處理,至少能夠在一定程度上提高對數據的吞吐量,進而提高對數據分析的實時性。
技術研發人員:孟玉靜,劉亞雄,宋倚天,楊祥瑞
受保護的技術使用者:三六零數字安全科技集團有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!