用于機器學習模型的引導源收集的制作方法
背景技術:
1、無論是為了訓練機器學習模型還是為了在未標記的數據上執行已訓練的機器學習模型,機器學習(ml)應用都要處理大量的輸入數據。這種輸入數據能夠通過多種方法來獲得,這些方法通常涉及手動操縱,諸如手動標記和過濾。
2、web爬蟲系統性地瀏覽萬維網上的數據,從html頁面和其他web內容(統稱為“內容”)收集龐大的數據集,并且將這些數據集組織成web索引,以便為服務(諸如搜索引擎)提供高效的數據訪問。然而,此類web爬蟲通常采用瀏覽整個web的暴力方法來收集用于一般web搜索的輸入數據并且將其編索引。因此,來自現有web爬蟲的輸入數據可能會包括與特定ml應用無關的數據,并且還缺少關于各個頁面和內容之間的關系的上下文信息。
技術實現思路
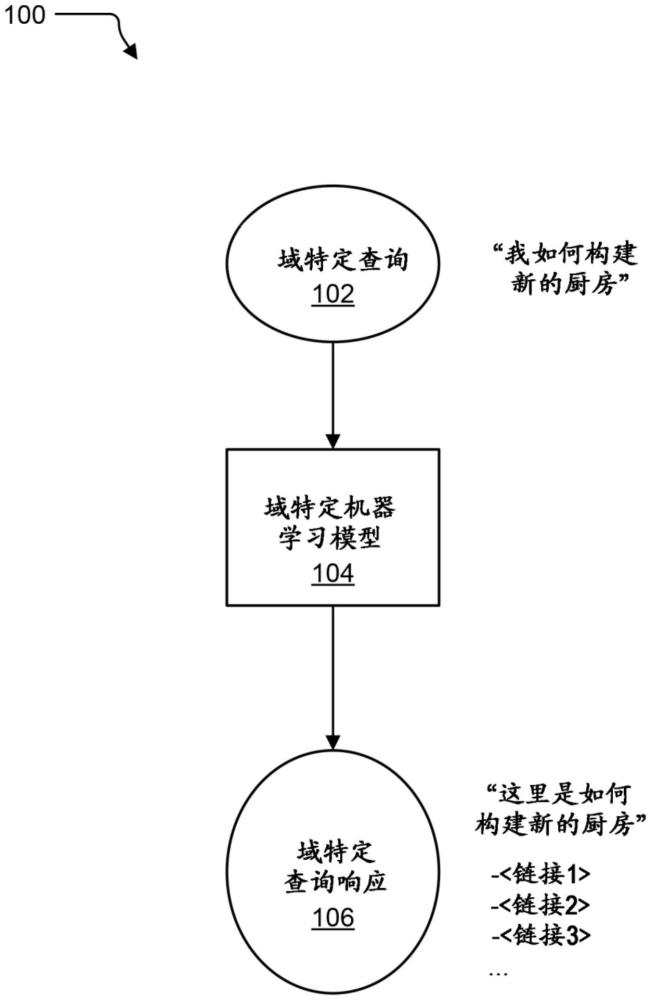
1、所描述的技術提供從網絡圖收集數據,其中所收集的數據對于在查詢域上訓練機器學習模型有用。與查詢域對應的域特定模板被接收,域特定模板定義一個或多個分類器以引導從網絡圖收集與查詢域相關的內容。收集起點是基于域特定模板的一個或多個分類器來分析的,以標識內容的一個或多個相關實例。內容的所標識的一個或多個相關實例被添加至上下文協議包。內容的每個所標識的相關實例是基于域特定模板的一個或多個分類器來分析的,以標識內容的一個或多個附加相關實例。內容的所標識的一個或多個附加相關實例被添加至上下文協議包。
2、提供本
技術實現要素:
是為了以簡化形式介紹對在以下具體實施方式中進一步描述的構思的選擇。本發明內容既不旨在標識所要求的主題的關鍵特征或必要特征,也不旨在用于限制所要求的主題的范圍。
3、本文還描述和列舉了其他實施方式。
技術特征:
1.一種從網絡圖收集數據的方法,其中所收集的所述數據對于在查詢域上訓練機器學習模型有用,所述方法包括:
2.根據權利要求1所述的方法,其中分析所述收集起點的所述操作包括:
3.根據權利要求1所述的方法,其中分析所述內容的每個所標識的相關實例的所述操作包括:
4.根據權利要求1所述的方法,還包括:
5.根據權利要求1所述的方法,還包括:
6.根據權利要求1所述的方法,還包括:
7.根據權利要求1所述的方法,還包括:
8.一種用于從網絡圖收集數據的系統,其中所收集的所述數據對于在查詢域上訓練機器學習模型有用,所述系統包括:
9.根據權利要求8所述的系統,其中所述收集器被配置為基于所述域特定模板的所述一個或多個分類器來分析所述收集起點,以標識所述內容的一個或多個實例,并且針對一個或多個相關性條件評估所述內容的每個所標識的實例,以標識所述內容的所述一個或多個相關實例。
10.根據權利要求8所述的系統,其中所述收集器被配置為基于所述域特定模板的所述一個或多個分類器來分析所述內容的每個所標識的相關實例,以標識所述內容的一個或多個附加實例,并且針對一個或多個相關性條件評估所述內容的每個所標識的附加實例,以標識所述內容的所述一個或多個附加相關實例。
11.根據權利要求8所述的系統,其中所述收集器還被配置為針對所述內容的一個或多個附加實例的多個分析和添加階段進行迭代,以標識所述內容的一個或多個附加相關實例的附加集合,并且將它們添加至所述上下文協議包,并且基于確定在分析和添加階段標識的所述內容的所述一個或多個附加實例未能滿足一個或多個相關性條件來終止所述迭代。
12.根據權利要求8所述的系統,還包括:
13.根據權利要求8所述的系統,還包括:
14.根據權利要求8所述的系統,還包括:
15.一種或多種體現有指令的有形處理器可讀存儲介質,所述指令用于在計算設備的一個或多個處理器和電路上執行用于從網絡圖收集數據的過程,其中所收集的所述數據對于在查詢域上訓練機器學習模型有用,所述過程包括:
技術總結
從網絡圖收集數據,其中所收集的數據對于在查詢域上訓練機器學習模型有用。與查詢域對應的域特定模板被接收,域特定模板定義一個或多個分類器以引導從網絡圖收集與查詢域相關的內容。收集起點是基于域特定模板的一個或多個分類器來分析的,以標識內容的一個或多個相關實例。內容的所標識的一個或多個相關實例被添加至上下文協議包。內容的每個所標識的相關實例是基于域特定模板的一個或多個分類器來分析的,以標識內容的一個或多個附加相關實例。內容的所標識的一個或多個附加相關實例被添加至上下文協議包。
技術研發人員:張羽,P·沙瑪,M·舒克拉,G·A·奧爾洛夫
受保護的技術使用者:微軟技術許可有限責任公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!