一種基于深度強化學習的多機器人群集控制方法及系統
本發明屬于多機器人控制,尤其涉及一種基于深度強化學習的多機器人群集控制方法及系統。
背景技術:
1、本部分的陳述僅僅是提供了與本發明相關的背景技術信息,不必然構成在先技術。
2、多機器人群集已被廣泛研究并應用于多機器人系統的各個領域。這對于確保安全和合作的航行至關重要,其遵循凝聚、對齊和分離的基本原則,由于環境的非平穩性和部分可觀測性,在復雜條件下制定合作群集策略仍然是一項艱巨的挑戰。
3、目前多機器人群集控制通常基于人工勢場(apf)和模型預測控制(mpc)等傳統方法。然而,傳統的方法通常需要對環境和智能體進行精確的建模,這大大降低了它們在具有復雜約束的環境中的適用性。
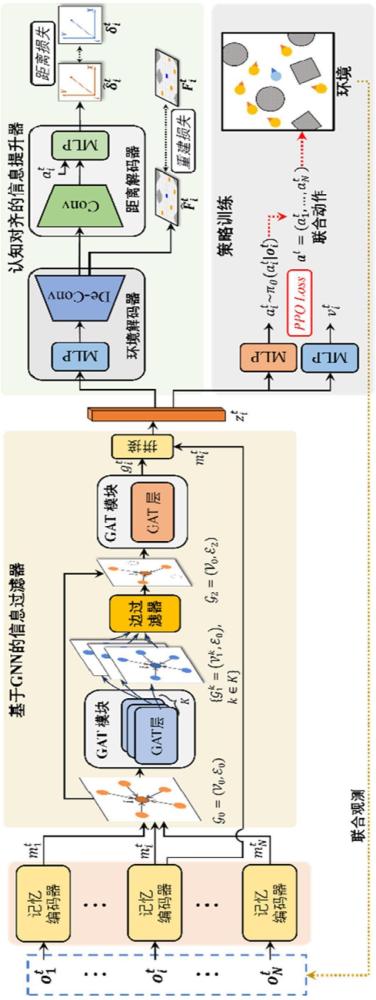
4、強化學習(rl)因其決策能力而受到關注,已成為群集任務的一種有前途的替代方案。通過利用單智能體rl(sarl),策略,成功地啟用了具有避免碰撞的群集行為。然而,基于sarl的框架的一個關鍵限制是智能體將其他智能體僅僅視為環境元素,使得策略容易受到環境非平穩性的影響。
5、因此,各種基于多智能體rl(marl)的群集方法被開發出來。這些策略通常包括機器人之間的通信,以減輕由于有限的可觀察性而導致的不協調。通過學習傳遞和解釋相關信息,智能體能夠更深入地了解環境和他人的行為。然而,復雜環境中的通信經常引發嚴重的探索挑戰,削弱了機器人通信能力的潛在優勢。首先,密集交互造成的冗余通信可能導致信息過載甚至混亂。其次,有限的可觀察性限制了分散信息的表達能力,使機器人難以識別關鍵的決策信息。因此,這些問題導致的無效溝通加劇了marl中的高方差問題,從而損害了模型學習。
技術實現思路
1、為克服上述現有技術的不足,本發明提供了一種基于深度強化學習的多機器人群集控制方法及系統。
2、為實現上述目的,本發明的一個或多個實施例提供了如下技術方案:
3、本發明第一方面提供了一種基于深度強化學習的多機器人群集控制方法,包括:
4、獲取跟隨者-領導者機器人拓撲架構下,跟隨者的單步觀測信息;
5、將獲取的單步觀測信息輸入至訓練后的決策模型中,得到跟隨者下一步的運動策略;
6、在所述決策模型中,利用基于圖神經網絡的信息過濾器對機器人的交互進行精煉實現選擇性通信;所述基于圖神經網絡的信息過濾器包括順次連接的第一圖注意力模塊、邊濾波器以及第二圖注意力模塊;
7、構建用于表征機器人之間的交互過程的拓撲圖,利用第一圖注意力模塊計算拓撲圖中節點與其鄰居節點的重要性得分,基于重要性得分聚合節點的所有鄰居節點的特征;聚合的特征再與節點本身特征拼接以形成節點新的特征,得到更新后的拓撲圖;
8、基于更新后拓撲圖,利用邊濾波器融合所有圖中鄰居節點的特征后進行邊過濾,利用第二圖注意力模塊對過濾后鄰居節點的特征進行聚合;將第二圖注意力模塊聚合的特征再與編碼后的觀測信息進行拼接后,輸入至策略網絡中生成跟隨者下一步的運動策略。
9、本發明第二方面提供了一種基于深度強化學習的多機器人群集控制系統,包括:
10、狀態信息獲取模塊,被配置為:獲取跟隨者-領導者機器人拓撲架構下,跟隨者的單步觀測信息;
11、運動策略生成模塊,被配置為:將獲取的單步觀測信息輸入至訓練后的決策模型中,得到跟隨者下一步的運動策略;
12、在所述決策模型中,利用基于圖神經網絡的信息過濾器對機器人的交互進行精煉實現選擇性通信;所述基于圖神經網絡的信息過濾器包括順次連接的第一圖注意力模塊、邊濾波器以及第二圖注意力模塊;
13、構建用于表征機器人之間的交互過程的拓撲圖,利用第一圖注意力模塊計算拓撲圖中節點與其鄰居節點的重要性得分,基于重要性得分聚合節點的所有鄰居節點的特征;聚合的特征再與節點本身特征拼接以形成節點新的特征,得到更新后的拓撲圖;
14、基于更新后拓撲圖,利用邊濾波器融合所有圖中鄰居節點的特征后進行邊過濾,利用第二圖注意力模塊對過濾后鄰居節點的特征進行聚合;將第二圖注意力模塊聚合的特征再與編碼后的觀測信息進行拼接后,輸入至策略網絡中生成跟隨者下一步的運動策略。
15、本發明第三方面提供了計算機可讀存儲介質,其上存儲有程序,該程序被處理器執行時實現如本發明第一方面所述的一種基于深度強化學習的多機器人群集控制方法中的步驟。
16、本發明第四方面提供了電子設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的程序,所述處理器執行所述程序時實現如本發明第一方面所述的一種基于深度強化學習的多機器人群集控制方法中的步驟。
17、以上一個或多個技術方案存在以下有益效果:
18、(1)密集的互動過程中,過載可能會導致錯誤的數據,從而降低溝通的有效性。因此本發明提出了基于圖神經網絡的信息過濾器進行信息精煉,使機器人能夠自適應地選擇鄰居進行交互,通過對信息的精煉和增強,顯著提高了通信效率。
19、(2)在決策模型的訓練過程中,本發明提出了一種基于級聯解碼器的信息增強器,利用與領導者相關的特權知識來幫助信息表示,鼓勵分散的跟隨者之間的認知一致性,通過認知對齊來提高信息表達能力,從而有利于一致的群集行為。
20、本發明附加方面的優點將在下面的描述中部分給出,部分將從下面的描述中變得明顯,或通過本發明的實踐了解到。
技術特征:
1.一種基于深度強化學習的多機器人群集控制方法,其特征在于,包括:
2.如權利要求1所述的一種基于深度強化學習的多機器人群集控制方法,其特征在于,所述跟隨者的單步觀測信息包括跟隨者的速度信息、領導者的位置和速度信息以及跟隨者視野內的與其他物體之間的距離信息。
3.如權利要求1所述的一種基于深度強化學習的多機器人群集控制方法,其特征在于,所述決策模型包括順次連接的記憶編碼器、基于圖神經網絡的信息過濾器以及策略網絡;
4.如權利要求3所述的一種基于深度強化學習的多機器人群集控制方法,其特征在于,所述記憶編碼器包括多個單觀測編碼器以及一個基于transformer的編碼器;所述單觀測編碼器用于對跟隨者的某一時刻的單步觀測信息進行編碼,所述基于transformer的編碼器用于對多個單觀測編碼器的輸出按照時間順序進行嵌入。
5.如權利要求1所述的一種基于深度強化學習的多機器人群集控制方法,其特征在于,使用近端策略優化算法訓練所述決策模型,在訓練過程中計算近端策略優化損失;
6.如權利要求5所述的一種基于深度強化學習的多機器人群集控制方法,其特征在于,所述基于級聯解碼器結構的信息增強器,包括順次連接的環境解碼器和距離解碼器;
7.如權利要求1所述的一種基于深度強化學習的多機器人群集控制方法,其特征在于,所述基于更新后拓撲圖,利用邊濾波器融合所有圖中鄰居節點的特征后進行邊過濾,包括:
8.一種基于深度強化學習的多機器人群集控制系統,其特征在于,包括:
9.計算機可讀存儲介質,其上存儲有程序,其特征在于,該程序被處理器執行時實現如權利要求1-7任一項所述的一種基于深度強化學習的多機器人群集控制方法中的步驟。
10.電子設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的程序,其特征在于,所述處理器執行所述程序時實現如權利要求1-7任一項所述的一種基于深度強化學習的多機器人群集控制方法中的步驟。
技術總結
本發明屬于多機器人控制技術領域,尤其涉及一種基于深度強化學習的多機器人群集控制方法及系統,方法包括:將單步觀測信息輸入至決策模型中得到跟隨者下一步的運動策略;在決策模型中,利用基于圖神經網絡的信息過濾器對機器人的交互進行精煉實現選擇性通信;其包括第一圖注意力模塊、邊濾波器以及第二圖注意力模塊;利用第一圖注意力模塊從不同的角度計算拓撲圖中所有鄰居節點的特征,得到多個更新后的拓撲圖;利用邊濾波器對更新后拓撲圖中的鄰居節點進行特征融合及邊過濾,利用第二圖注意力模塊聚合過濾后的鄰居節點的特征。本發明提出基于圖神經網絡的信息過濾器進行信息精煉,使機器人能夠自適應地選擇鄰居進行交互,顯著提高了通信效率。
技術研發人員:宋勇,賈云杰,龐豹,許慶陽,袁憲鋒,劉萍萍,劉冰,李貽斌
受保護的技術使用者:山東大學
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!