用于聲音事件定位和檢測的方法和系統與流程
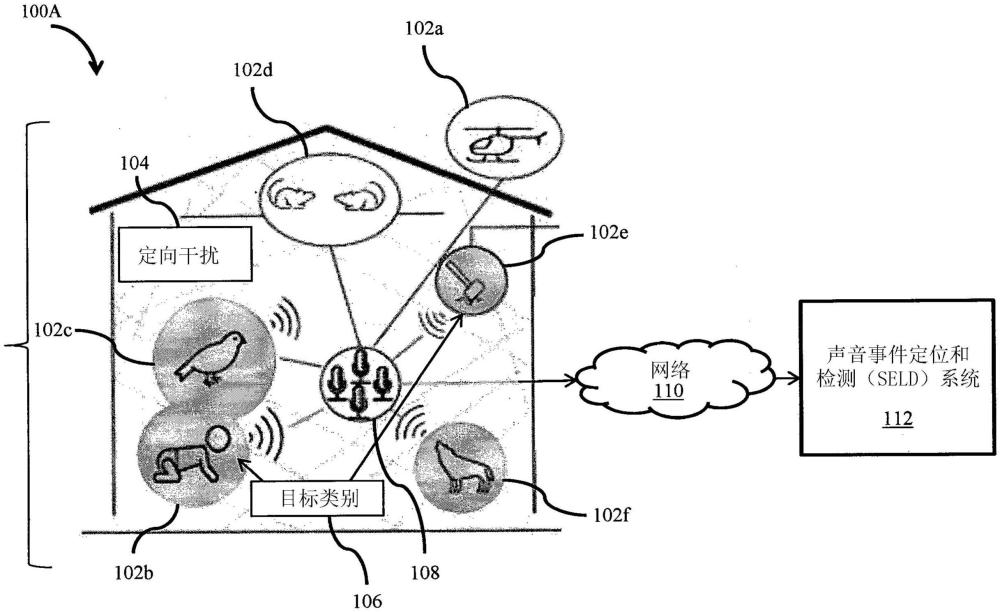
本公開總體上涉及聲音事件定位和檢測(sound?event?localization,seld),更具體地,涉及用于估計聲音事件到達方向的聲音事件定位和檢測系統。
背景技術:
1、現有的用于seld的系統通常通過在每個時刻估計針對所有類別的源位置來運行。然而,seld仍然具有挑戰性,因為聲源可以移動、停止產生聲音、使其位置被室內混響掩蓋、并且經常與干擾聲音混合。此外,許多聲音事件很容易混淆,這進一步使seld任務復雜化。
2、一般認為,估計聲音的定位信息,特別是聲音的到達方向(doa),以及對聲音的起源處發生的事件類型進行分類,是監控和機器人應用中使用的前端處理的重要類型。一些現有的seld系統遵循兩個主要階段的流水線(pipeline)。第一階段從麥克風陣列提取接收的聲音的頻譜和空間特征。在第二階段,使用深度神經網絡(dnn)學習從多通道輸入特征到以下兩個輸出目標的映射:(1)指示在每個時刻每個類別的存在的類別概率矢量;(2)包含針對每個類別的位置信息的doa矢量。在這種情況下,dnn訓練是具有挑戰性的,因為兩個輸出分支的貢獻必須平衡。
3、包括基于活動耦合笛卡爾到達方向(accdoa)表示的seld系統的一些現有的seld系統通常假設一個小的、固定的聲音事件類別集來進行檢測和定位。在實踐中,如果存在12個類別,則這意味著dnn將在每個時刻輸出12個accdoa表示。對于大量的類別,這種方法可能變得不切實際,并且在某些情況下,可能不需要始終對所有類別進行定位。
4、為此,訓練類別特定的系統以僅定位來自單個類別的聲音事件,將允許專注于特定類別。然而,訓練類別特定的模型可能很困難,因為可能沒有足夠的可用于每個感興趣的類別的數據來正確訓練各個和每個模型。
5、因此,需要一種克服上述缺陷的seld系統。
6、為此,需要一種克服上述挑戰的技術方案。更具體地,需要在存在定向干擾的情況下優于傳統的聲音事件檢測和定位的這種seld系統。
技術實現思路
1、本公開提供一種用于聲音事件定位的類別約束的seld系統。如前所述,現有的seld系統通常通過在每個時刻估計針對所有類別的源位置來運行。然而,seld仍然具有挑戰性,因為聲源可以移動、停止產生聲音、使其位置被室內混響掩蓋、并且經常與干擾聲音混合。此外,許多聲音事件很容易混淆,這使seld任務更加復雜。
2、一些實施方式基于這樣一種認識,即,在本seld系統中,在每個時刻只有一個單accdoa矢量輸出,并且由該輸出表示的類別是基于描述需要定位的聲音事件類型的輸入來確定的。現有的seld系統,包括基于accdoa表示的系統的seld系統,通常假設一個小的、固定的聲音事件類別集來進行檢測和定位。例如,12個類別將在每個時刻輸出12個accdoa表示。
3、一些實施方式基于這樣一種認識,即,對于大量的類別,針對每個類別輸出一個accdoa表示可能變得不切實際,并且在某些情況下,可能不需要始終定位所有類別。為此,訓練類別特定的系統以僅定位來自單個類別的聲音事件,將允許專注于特定類別。然而,訓練類別特定的模型可能很困難,這是因為為了適當地訓練各個和每個模型,對每個感興趣的類別具有極大的訓練數據需求。
4、為此,本文提供的各種實施方式提供了一種方法和系統來定位來自單個目標類別的聲音事件并基于所定位的聲音事件來識別目標源。
5、一些實施方式基于下述認識,即,seld系統可被訓練為類別特定的系統,以定位來自單個類別的聲音事件并基于所定位的聲音事件來識別目標聲音事件。seld系統進一步用于估計目標聲音事件的doa以及目標聲音事件的起源與聲源之間的距離。為此,seld系統收集由聲學傳感器感測的聲學混合物的第一數字表示。所述聲學混合物與多個聲音事件相關聯。seld系統進一步接收與所述目標聲音事件相對應的聲音的第二數字表示。所述第二數字表示用于從所述多個聲音事件中識別目標聲音事件。所述第一數字表示和所述第二數字表示由神經網絡處理。所述神經網絡被訓練為產生指示相對于所述聲學傳感器的位置的所述目標聲音事件的起源的位置的定位信息。通過這種方式,所述神經網絡識別出所述聲學混合物中的與其他聲音相干擾的目標聲音事件。
6、一些實施方式基于這樣的認識,即,本公開的seld系統被配置為確定doa以及所述目標聲音事件的起源與所述聲學傳感器之間的距離。通過用dnn處理所述第一數字表示和所述第二數字表示來確定所述doa和所述距離。dnn被訓練為將所述多個聲音事件中的除所識別的目標聲音事件以外的聲音事件視為定向干擾。所述seld系統進一步輸出所識別的目標聲音事件的doa和距離。
7、為此,所述第一數字表示對應于所述聲學混合物的空間特征和頻譜特征的表示。所述第二數字表示包括指示所述目標聲音事件的空間特性、頻譜特性或類別信息中的一個或組合的一個或更多個范例波形表示。此外,所述第二數字表示對應于指示預定的聲音事件類型的集合中的目標聲音事件的聲音事件類型的獨熱矢量。此外,所述第二數字表示包括指示所述目標聲音事件的空間特性、頻譜特性或類別信息中的一個或組合的一個或更多個范例波形表示。
8、所述seld系統進一步被配置為將指示多個類別中的目標類別的獨熱矢量分配給所識別的目標聲音事件。此外,所述seld系統利用類別約束的seld網絡來確定所識別的目標聲音事件的doa和距離。所述類別約束的seld網絡包括定向到一個或更多個卷積塊的至少一個film塊。所述至少一個film塊和所述一個或更多個卷積塊被訓練為識別所述目標聲音事件并估計所識別的目標聲音事件的doa和距源的距離。
9、因此,一個實施方式公開了一種由計算機實現的用于定位目標聲音事件的方法。所述方法包括收集由所述聲學傳感器感測到的多個聲音事件的聲音的聲學混合物的第一數字表示。所述方法還包括接收與所述目標聲音事件相對應的聲音的第二數字表示。利用神經網絡處理所述第一數字表示和所述第二數字表示,神經網絡被訓練為產生指示相對于聲學傳感器的位置的目標聲音事件的起源的位置的定位信息。所述神經網絡識別出所述聲學混合物中的與其他聲音相干擾的目標聲音事件。然后輸出所述目標聲音事件的起源的定位信息。所述定位信息包括所述目標聲音事件從其起源指向所述聲學傳感器的doa以及所述目標聲音事件的起源與聲音的聲學傳感器之間的距離。
10、本文公開的各種實施方式提供了一種seld系統,即使在沒有足夠的訓練數據時,該seld系統也可以更準確、更高效地并在更短的時間內確定與所述目標聲音事件相關聯的定位信息。
11、當與附圖結合時,從以下詳細描述中可以更容易地看出其他特征和優點。
技術特征:
1.一種聲音事件定位與檢測seld系統,所述seld系統用于一個或更多個目標聲音事件的定位,所述seld系統包括:至少一個處理器;以及存儲器,在所述存儲器上存儲有指令,當由所述至少一個處理器執行時,所述指令使所述seld系統:
2.根據權利要求1所述的seld系統,其中,所述神經網絡通過將所述目標聲音事件的所述第二數字表示與所述神經網絡的處理所述聲學混合物的所述第一數字表示的至少一些層的至少一些中間輸出相結合來識別所述目標聲音事件。
3.根據權利要求1所述的seld系統,其中,所述定位信息包括所述目標聲音事件從所述目標聲音事件的起源指向所述聲學傳感器的到達方向以及所述目標聲音事件的所述起源與所述聲學傳感器之間的距離中的一個或組合。
4.根據權利要求1所述的seld系統,其中,所述第二數字表示識別多個目標聲音事件,并且其中,所述神經網絡是多頭神經網絡,所述多頭神經網絡利用置換不變訓練而被訓練為將不同目標聲音事件的不同定位信息輸出到所述多頭神經網絡的不同頭部。
5.根據權利要求1所述的seld系統,其中,所述神經網絡通過將所述目標聲音事件的所述第二數字表示的編碼與所述神經網絡的處理所述聲學混合物的所述第一數字表示的至少一些層的至少一些中間輸出相結合來識別與所述聲學混合物中的其他聲音相干擾的所述目標聲學事件。
6.根據權利要求1所述的seld系統,其中,所述神經網絡利用將所述第一數字表示置于所述第二數字表示的嵌入的上下文中的注意力來處理所述第一數字表示。
7.根據權利要求1所述的seld系統,其中,所述處理器被配置為:
8.根據權利要求7所述的seld系統,其中,所述神經網絡包括用于確定所述定位信息的類別約束的seld網絡,其中,所述類別約束的seld網絡包括定向到一個或更多個卷積塊的至少一個film塊,其中,所述至少一個film塊和所述一個或更多個卷積塊被訓練為識別所述目標聲音事件并估計所述定位信息。
9.根據權利要求8所述的seld系統,其中,所述film塊中的每一個包括嵌入層、線性層、丟棄層、平鋪層和輸出層。
10.根據權利要求8所述的seld系統,其中,所述一個或更多個卷積塊中的每一個包括二維卷積層、批歸一化層、整流線性激活函數relu、最大池化層和丟棄層。
11.根據權利要求8所述的seld系統,其中,所述神經網絡是卷積循環神經網絡。
12.根據權利要求1所述的seld系統,其中,所述第二數字表示包括指示預定的聲音事件類型的集合中的所述目標聲音事件的聲音事件類型的獨熱矢量。
13.根據權利要求1所述的seld系統,其中,所述第二數字表示包括指示所述目標聲音事件的空間特性、頻譜特性或類別信息中的一個或組合的一個或更多個范例波形表示。
14.根據權利要求13所述的seld系統,其中,所述神經網絡將獨熱矢量轉換為嵌入矢量,并對所述嵌入矢量與所述聲學混合物的所述第一數字表示進行聯合處理以產生所述定位信息。
15.根據權利要求14所述的seld系統,其中,所述神經網絡使用一個或多個特征不變線性調制film塊對所述嵌入矢量與所述聲學混合物的所述第一數字表示進行聯合處理。
16.根據權利要求1所述的seld系統,其中,所述第一數字表示包括所述聲學混合物的空間特征和頻譜特征的波形表示。
17.根據權利要求1所述的seld系統,其中,所述聲學傳感器包括通過有線通信信道或無線通信信道在操作上連接到所述seld的以預定模式布置的多個麥克風。
18.一種用于定位目標聲音事件的方法,所述方法包括以下步驟:
19.根據權利要求18所述的方法,其中,所述神經網絡通過將所述目標聲音事件的所述第二數字表示與所述神經網絡的處理所述聲學混合物的所述第一數字表示的至少一些層的至少一些中間輸出相結合來識別所述目標聲音事件。
20.根據權利要求18所述的方法,其中,所述第二數字表示包括指示所述目標聲音事件的空間特性、頻譜特性或類別信息中的一個或組合的一個或更多個范例波形表示。
技術總結
本公開的實施方式公開了用于定位目標聲音事件的系統和方法。所述系統通過使用聲學傳感器收集多個聲音事件的聲音的聲學混合物的第一數字表示。所述系統接收與所述目標聲音事件相對應的聲音的第二數字表示。此外,所述第一數字表示和所述第二數字表示通過神經網絡進行處理,以產生指示相對于所述聲學傳感器的位置的所述目標聲音事件的起源的位置的定位信息。
技術研發人員:G·維切恩,O·斯利佐夫斯卡婭,J·勒魯克斯
受保護的技術使用者:三菱電機株式會社
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!