基于具備音樂理解能力的大語言模型自動生成音樂描述文本的方法
本發明涉及音樂自動標注,尤其是一種基于具備音樂理解能力的大語言模型自動生成音樂描述文本的方法。
背景技術:
1、擴散模型在文本到圖像和文本到視頻生成領域展現出了卓越的生成效果,研究也表明這種模型架構可以被很好地使用在文本到音樂生成上。然而,訓練高質量的用于內容生成的擴散模型往往需要海量的標注數據集。不同于文本和圖像,構建音樂-文本數據集往往需求大量具備專業音樂知識的人員進行費時費力的手動標注,使用這樣的方法難以構建大規模的標注數據集。相較于此,使用模型進行音樂自動標注具備更高的實用性。
2、音樂自動標注任務是人工智能領域一項具備實用性和挑戰性的任務,屬于一種音樂處理任務,其目標是使用自動化方法為未標注的音樂確定其各種特性,添加標注信息。自動生成音樂描述文本是音樂自動標注任務的一種分支,不同于為音樂自動分類等為音樂添加標簽的任務,其特點在于通過自動化方法為音樂添加使用常規自然語言表述的標注,這對模型的自然語言理解力提出了更高的要求。
3、近年來研究者們設計了一些方法來提升自動化工具在生成音樂描述文本方面的性能。例如采用大語言模型來將大規模的音樂-標簽數據集中的標簽信息擴展為描述文本。這一方案充分利用了大語言模型強大的自然語言理解能力和音樂-標簽數據集的龐大規模,具備很好的效果。然而,由于大語言模型的輸入模態限制,其生成過程缺乏音樂本身信息的參與,可能導致生成的描述文本不夠準確。
技術實現思路
1、本發明的目的是針對現有音樂-文本數據集規模不足,現有自動標注方法標注過程中缺乏音樂本身信息而提出一種基于具備音樂理解能力的大語言模型自動生成音樂描述文本的方法,該方法使用成熟大語言模型的數據增強方法,在不改變現有數據集的準確性的前提下對數據集進行擴充,由此訓練多個模型進行聯合標注,減少在小規模數據集下單一模型存在的偏見問題,以此獲得更加準確的音樂描述文本。
2、實現本發明目的的具體技術方案是:
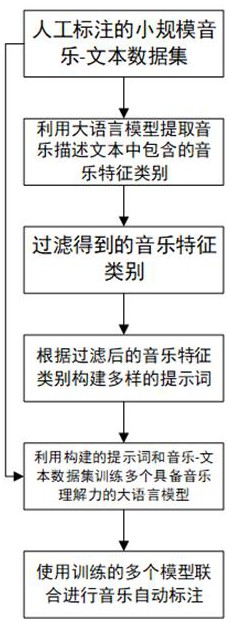
3、一種基于具備音樂理解能力的大語言模型自動生成音樂描述文本的方法,該方法包括以下步驟:
4、1)?選擇一個現有的具備音樂-描述文本-音樂標簽的小規模人工標注音樂數據集作為基礎數據集,使用大語言模型提取該數據集中音樂描述文本包含的音樂特征類別;
5、2)?設置閾值線對提取的音樂特征類別進行過濾;
6、3)?構建多種不同的基本提示詞和提示詞模板,將步驟1的數據集中的音樂標簽及經過濾的音樂特征類別填入提示詞模板中,結合構建的基本提示詞,得到多種不同的訓練用提示詞;
7、4)?利用所得的多種不同的訓練用提示詞分別訓練多個具備音樂理解能力的大語言模型;
8、5)?選擇一個現有的具備音樂-音樂標簽的數據集,將該數據集中的音樂標簽填入步驟3)中構建的提示詞模板中,結合步驟3)中構建的基本提示詞,得到多種不同的標注用提示詞;
9、6)?利用所得的多種不同的標注用提示詞分別輸入對應的訓練所得的具備音樂理解能力的大語言模型聯合進行音樂自動標注,生成音樂描述文本。
10、進一步,所述步驟1)具體包括:
11、1.1:選擇具備音樂-描述文本-音樂標簽的現有音樂數據集,構建特征提取提示詞;
12、1.2:將特征提取提示詞輸入大語言模型,得到描述文本中包含的音樂特征類別。
13、進一步,步驟3)所述多種不同的基本提示詞和提示詞模板,包括:常規提示詞、特征提示詞模板和任務提示詞模板。
14、進一步,所述步驟4)具體包括:
15、4.1:使用步驟3中得到的多種訓練用提示詞、步驟1數據集中的音樂片段和音樂描述文本作為多個不同的提示詞-音樂-文本的輸入對,所述輸入對擁有相同的音樂和文本,但提示詞不同;
16、4.2:使用具備音樂理解能力的大語言模型、相同的訓練參數和4.1中構建的多個不同輸入對分別訓練多個不同的具備音樂理解能力的大語言模型。
17、進一步,所述步驟5)具體包括:
18、5.1:選擇一個具備音樂標簽和音樂的數據集作為待標注數據集;
19、5.2:將待標注數據集中的音樂標簽和步驟2所得的特征類別結果填入步驟3中構建的提示詞模板,結合步驟3中構建的基本提示詞,得到多種不同的標注用提示詞。
20、進一步,所述步驟6)具體包括:
21、6.1:使用步驟5中得到的多種標注用提示詞和步驟5的待標注數據集中的音樂片段作為多個不同的提示詞-音樂的輸入對,所述輸入對擁有相同的音樂,但提示詞不同;
22、6.2:將步驟6.1中得到的多個不同的輸入對分別輸入步驟4中所訓練的多個具備音樂理解力的大語言模型,其中構建用于訓練的提示詞和用于標注的提示詞所使用的提示詞模板一一對應;
23、6.3:將多個具備音樂理解力的大語言模型的每一輪經過softmax函數后的結果進行加權平均作為當前輪次的最終輸出結果,并接入輸入部分中進行下一輪預測,直到句子結尾標識符出現,生成音樂描述文本。
24、有益效果
25、本發明提出采用具備音樂理解能力的大語言模型優化標注過程中缺乏音樂本身信息的問題。同時,由于向大語言模型添加音樂理解功能要求對現有大語言模型進行微調,但公開的音樂-文本數據集規模較小,在小規模數據集下進行訓練導致單一模型存在較大的偏見,并不足以使得模型獲得很好的微調結果。因此本發明提出了使用成熟大語言模型的數據增強方法,在不改變現有數據集的準確性的前提下對數據集進行擴充,由此訓練多個模型進行聯合標注,減少在小規模數據集下單一模型存在的偏見問題,以此獲得更加準確的音樂描述文本。
技術特征:
1.一種基于具備音樂理解能力的大語言模型自動生成音樂描述文本的方法,其特征在于,該方法包括以下步驟:
2.根據權利要求1所述的自動生成音樂描述文本的方法,其特征在于,所述步驟1)具體包括:
3.根據權利要求1所述的自動生成音樂描述文本的方法,其特征在于,步驟3)所述多種不同的基本提示詞和提示詞模板,包括:常規提示詞、特征提示詞模板和任務提示詞模板。
4.根據權利要求1所述的自動生成音樂描述文本的方法,其特征在于,所述步驟4)具體包括:
5.根據權利要求1所述的自動生成音樂描述文本的方法,其特征在于,所述步驟5)具體包括:
6.根據權利要求1所述的自動生成音樂描述文本的方法,其特征在于,所述步驟6)具體包括:
技術總結
本發明公開了一種基于具備音樂理解能力的大語言模型自動生成音樂描述文本的方法,包括:a)使用大語言模型對現有的具備音樂?描述文本?音樂標簽的小規模人工標注音樂數據集進行數據增強,得到多種不同的訓練用提示詞并訓練多個具備音樂理解能力的大語言模型;b)利用現有的具備音樂?音樂標簽的數據集中的音樂標簽構建多種不同的標注用提示詞,將數據集中的音樂信息和多種標注用提示詞分別輸入訓練后的模型中聯合進行音樂自動標注,生成音樂描述文本。本發明使用成熟大語言模型的數據增強方式,在不改變現有數據集的準確性的前提下對數據集進行擴充,由此訓練多個模型進行聯合標注,獲得更為準確的音樂描述文本。
技術研發人員:張恒瑜,梅嘉豪,劉凱源,董道國,吳興蛟,賀樑
受保護的技術使用者:華東師范大學
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!