無線蜂窩系統中基于大語言模型應用的優化方法
本發明涉及數據處理技術,更具體的說,是涉及無線蜂窩系統中基于大語言模型應用的優化方法。
背景技術:
1、隨著芯片算力和人工智能算法的進步,手機等終端設備也用到了大語言模型(large?language?model,?簡稱為llm),用于文本、語音、圖像處理、無線信號處理等。這里的大語言模型一般指使用大量文本數據訓練的深度學習模型,可以生成自然語言文本或理解語言文本的含義。大語言模型也可簡稱為大模型,泛指參數比較多的人工智能模型。基于手機的大語言模型,其參數集可以到幾億甚至幾十億量級,可以處理一些簡單的人工智能應用。但是針對一些比較復雜的任務,例如圖像的處理或者音視頻的處理,受模型、手機硬件和其他條件的限制,需要在網絡側進行大語言模型的應用(例如推理、訓練等)。考慮到功耗、響應時延、推理的準確度等多個因素,在終端側進行大語言模型應用還是在網絡側進行大語言模型應用的用戶體驗可能不同。
2、目前,將大語言模型技術引入到終端的數據處理中,研究剛剛開始,信令機制沒有確定,存在較多的優化問題需要解決。
技術實現思路
1、有鑒于此,本發明提供如下技術方案:
2、一種無線蜂窩網絡中基于大語言模型應用的優化方法,應用于終端的數據處理,其特征在于,包括:
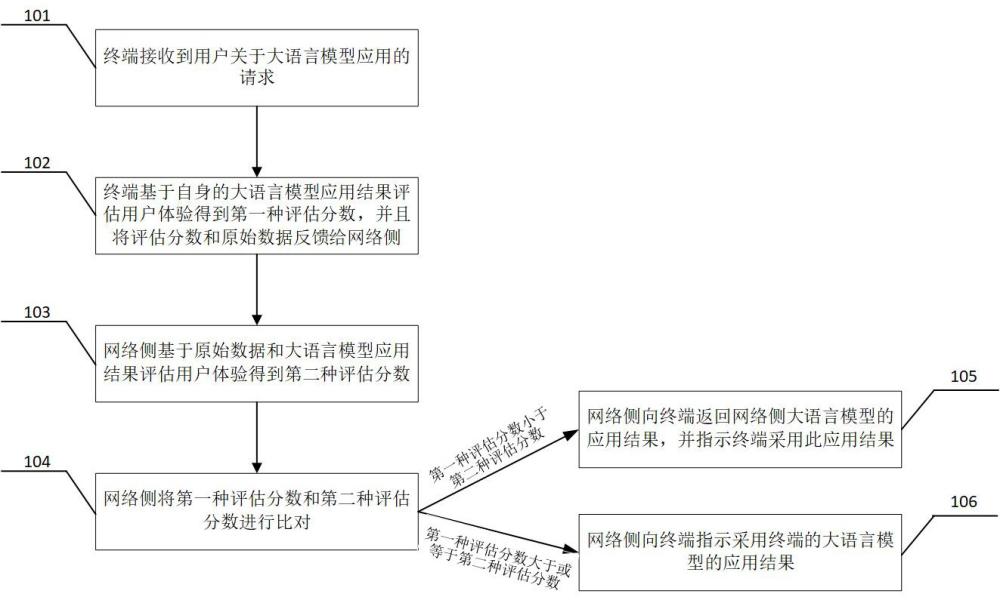
3、針對終端中一種基于大語言模型的應用,終端基于自身的大語言模型應用結果評估用戶體驗得到第一種評估分數,并且將評估分數和原始數據反饋給網絡側,網絡側基于原始數據和大語言模型應用結果評估用戶體驗得到第二種評估分數。網絡側將第一種評估分數和第二種評估分數進行比對,如果第一種評估分數小于第二種評估分數,網絡側向終端返回網絡側大語言模型的應用結果,并且指示終端采用此應用結果。如果第一種評估分數大于或者等于第二種評估分數,網絡側向終端指示采用終端大語言模型的應用結果。
4、該方法包括,基于大語言模型的應用,至少包括:用于文本總結、語言翻譯、音頻優化、視頻優化或者無線信號處理的大語言模型的訓練、學習和推理。
5、該方法進一步包括,終端基于自身的大語言模型應用結果評估用戶體驗得到第一種評估分數,至少包括:基于終端大語言模型應用中的功耗、響應時延和提供答案的準確度計算獲得第一種評估分數。
6、該方法還進一步包括,網絡側基于原始數據和大語言模型應用結果評估用戶體驗得到第二種評估分數,至少包括:基于網絡側大語言模型應用中的響應時延、所提供答案的準確度和傳輸數據的成本計算獲得第二種評估分數。
7、該方法還進一步包括,大語言模型應用中的原始數據,至少包括:用于大語言模型應用的文本、視頻、音頻或者無線信號。
8、一種無線蜂窩網絡中基于大語言模型應用的處理裝置,應用于終端的數據處理,其特征在于,包括:針對終端中一種基于大語言模型的應用,終端基于自身的大語言模型應用結果評估用戶體驗得到第一種評估分數,并且將評估分數和原始數據反饋給網絡側,網絡側基于原始數據和大語言模型應用結果評估用戶體驗得到第二種評估分數。網絡側將第一種評估分數和第二種評估分數進行比對,如果第一種評估分數小于第二種評估分數,網絡側向終端返回網絡側大語言模型的應用結果,并且指示終端采用此應用結果。如果第一種評估分數大于或者等于第二種評估分數,網絡側向終端指示采用終端大語言模型的應用結果。
9、經由上述的技術方案可知,與現有技術相比,本發明實施例公開了一種無線蜂窩網絡中基于大語言模型應用的優化方法,方法包括:針對終端中一種基于大語言模型的應用,終端基于自身的大語言模型應用結果評估用戶體驗得到第一種評估分數,并且將評估分數和原始數據反饋給網絡側,網絡側基于原始數據和大語言模型應用結果評估用戶體驗得到第二種評估分數。網絡側將第一種評估分數和第二種評估分數進行比對,如果第一種評估分數小于第二種評估分數,網絡側向終端返回網絡側大語言模型的應用結果,并且指示終端采用此應用結果。如果第一種評估分數大于或者等于第二種評估分數,網絡側向終端指示采用終端大語言模型的應用結果。
技術特征:
1.一種無線蜂窩網絡中基于大語言模型應用的優化方法,應用于終端的數據處理,其特征在于,包括:
2.根據權利要求1所述的一種無線蜂窩網絡中基于大語言模型應用的優化方法,其特征在于,所述的基于大語言模型的應用,至少包括:
3.根據權利要求1所述的一種無線蜂窩網絡中基于大語言模型應用的優化方法,其特征在于,所述的終端基于自身的大語言模型應用結果評估用戶體驗得到第一種評估分數,至少包括:
4.根據權利要求1所述的一種無線蜂窩網絡中基于大語言模型應用的優化方法,其特征在于,所述的網絡側基于原始數據和大語言模型應用結果評估用戶體驗得到第二種評估分數,至少包括:
5.根據權利要求1所述的一種無線蜂窩網絡中基于大語言模型應用的優化方法,其特征在于,所述的原始數據,至少包括:
6.一種無線蜂窩網絡中基于大語言模型應用的處理裝置,應用于終端的數據處理,其特征在于,包括:
技術總結
本申請公開了一種無線蜂窩網絡中基于大語言模型應用的優化方法,方法包括:針對終端中一種基于大語言模型的應用,終端基于自身的大語言模型應用結果評估用戶體驗得到第一種評估分數,并且將評估分數和原始數據反饋給網絡側,在網絡側基于原始數據和大語言模型應用結果評估用戶體驗得到第二種評估分數。網絡側將第一種評估分數和第二種評估分數進行比對,如果第一種評估分數小于第二種評估分數,網絡側向終端返回網絡側大語言模型的應用結果,并且指示終端采用此應用結果。如果第一種評估分數大于或者等于第二種評估分數,網絡側向終端指示采用終端的大語言模型的應用結果。
技術研發人員:韓麗華
受保護的技術使用者:北京物資學院
技術研發日:
技術公布日:2024/10/14
- 還沒有人留言評論。精彩留言會獲得點贊!