語音合成前端處理方法、裝置、設備和存儲介質與流程
本申請涉及計算機,具體涉及一種語音合成前端處理方法、裝置、設備和存儲介質。
背景技術:
1、語音合成的前端的質量將會嚴重影響之后語音合成的效果,其中,字音轉換(grapheme-to-phoneme,g2p)和韻律預測是中文語音合成前端中最重要的兩個任務,g2p決定了后續語音合成發音的正確性,而文本韻律邊界預測的結果直接影響合成語音的自然度和韻律表現。
2、傳統的合成前端采用級聯式的結構,對輸入的文本進行分詞,詞性預測,g2p轉換和韻律預測,最后得到合適的帶有韻律信息的音素串,然后再輸入聲學模型中。雖然級聯式的結構可以實現音素級別的控制,但是由于前端任務之間的直接依賴關系,使得誤差在不斷積累(產生級聯誤差積累),從而影響整個語音合成系統的效果。基于此,在資源不足情況下,韻律預測以及多音字分歧成為亟需解決的問題。
技術實現思路
1、本申請實施例提供一種語音合成前端處理方法、裝置、設備和存儲介質,用以解決在資源不足情況下的韻律預測以及多音字分歧問題。
2、第一方面,本申請實施例提供一種語音合成前端處理方法,包括:
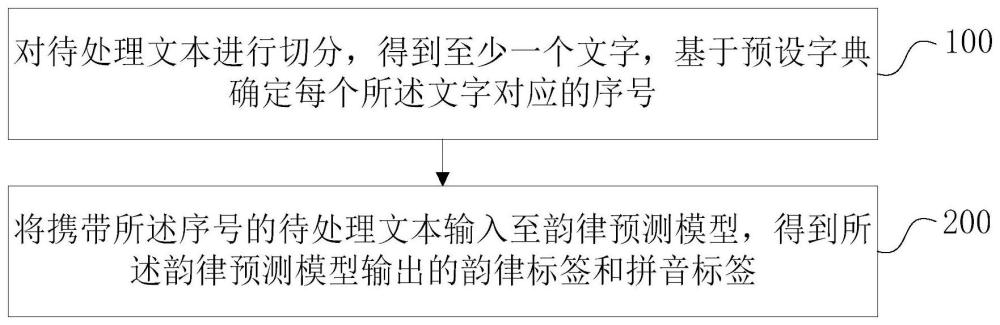
3、對待處理文本進行切分,得到至少一個文字,基于預設字典確定每個所述文字對應的序號;
4、將攜帶所述序號的待處理文本輸入至韻律預測模型,得到所述韻律預測模型輸出的韻律標簽和拼音標簽;
5、其中,所述韻律預測模型是基于包含所述韻律標簽和所述拼音標簽的文本數據集,以及所述預設字典對應的編碼向量訓練得到的;所述編碼向量是通過預訓練語言模型對所述預設字典中的多音字與其對應的釋義或示例句子的字典內容進行編碼得到的。
6、在一個實施例中,確定所述編碼向量,包括:
7、按照預設格式,對所述預設字典中的信息進行整合,得到所述多音字與其對應的釋義或示例句子的字典內容;
8、對所述字典內容進行數據清洗,以過濾句子長度不滿足設定長度以及不包含目標文字的句子;
9、將數據清洗后的字典內容輸入所述預訓練語言模型,得到所述預訓練語言模型輸出的所述編碼向量;所述編碼向量包含所述字典內容的語義信息。
10、在一個實施例中,所述韻律預測模型包括編碼層、注意力模塊和韻律邊界預測解碼層:
11、所述編碼層,用于將輸入的攜帶所述序號的待處理文本進行語義編碼,得到特征向量,并所述特征向量傳入所述注意力模塊;
12、所述注意力模塊,用于確定所述特征向量對應的字符的注意力分布,基于所述注意力分布,輸出字音轉換g2p預測結果;以及基于所述注意力分布,確定所述字符的語義隱向量,并將所述語義隱向量傳入所述韻律邊界預測解碼層;
13、所述韻律邊界預測解碼層,用于基于所述語義隱向量與所述字符的字向量的拼接向量,輸出韻律邊界預測結果。
14、在一個實施例中,所述注意力模塊,具體用于將所述字符的字向量作為查詢向量,基于所述查詢向量與所述預設字典,確定所述字符的注意力分布。
15、在一個實施例中,所述編碼層為對所述預訓練語言模型進行蒸餾后的模型。
16、在一個實施例中,所述韻律預測模型是基于以下步驟訓練得到的:
17、構建包含所述韻律標簽和所述拼音標簽的文本數據集;
18、基于所述文本數據集以及所述編碼向量進行模型訓練,得到所述韻律預測模型。
19、在一個實施例中,所述基于所述文本數據集以及所述編碼向量進行模型訓練,得到所述韻律預測模型之后,包括:
20、確定所述韻律預測模型的預測結果與樣本標簽的交叉熵損失值;
21、基于所述交叉熵損失值,確定所述韻律預測模型的模型參數的梯度;
22、基于所述梯度更新所述模型參數。
23、第二方面,本申請實施例提供一種語音合成前端處理裝置,包括:
24、文本處理模塊,用于對待處理文本進行切分,得到至少一個文字,基于預設字典確定每個所述文字對應的序號;
25、模型處理模塊,用于將攜帶所述序號的待處理文本輸入至韻律預測模型,得到所述韻律預測模型輸出的韻律標簽和拼音標簽;
26、其中,所述韻律預測模型是基于包含所述韻律標簽和所述拼音標簽的文本數據集,以及所述預設字典對應的編碼向量訓練得到的;所述編碼向量是通過預訓練語言模型對所述預設字典中的多音字與其對應的釋義或示例句子的字典內容進行編碼得到的。
27、第三方面,本申請實施例提供一種電子設備,包括處理器和存儲有計算機程序的存儲器,所述處理器執行所述程序時實現第一方面所述的語音合成前端處理方法的步驟。
28、第四方面,本申請實施例提供一種非暫態計算機可讀存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現第一方面所述的語音合成前端處理方法的步驟。
29、本申請實施例提供的語音合成前端處理方法、裝置、設備和存儲介質,通過對待處理文本進行切分,得到至少一個文字,基于預設字典確定每個文字對應的序號;將攜帶序號的待處理文本輸入至韻律預測模型,得到韻律預測模型輸出的韻律標簽和拼音標簽;其中,韻律預測模型是基于攜帶韻律標簽和拼音標簽的文本數據集,以及預設字典對應的編碼向量訓練得到的。本申請通過預訓練編碼,從預設字典中提取有關發音和韻律的編碼信息,并引入模型中,從而提高模型對多音字消歧任務的預測準確率;同時,通過韻律預測模型預測韻律標簽和拼音標簽,降低了推理復雜度,并提高了前端任務的準確率。
技術特征:
1.一種語音合成前端處理方法,其特征在于,包括:
2.根據權利要求1所述的語音合成前端處理方法,其特征在于,確定所述編碼向量,包括:
3.根據權利要求2所述的語音合成前端處理方法,其特征在于,所述韻律預測模型包括編碼層、注意力模塊和韻律邊界預測解碼層:
4.根據權利要求3所述的語音合成前端處理方法,其特征在于,所述注意力模塊,具體用于將所述字符的字向量作為查詢向量,基于所述查詢向量與所述預設字典,確定所述字符的注意力分布。
5.根據權利要求3所述的語音合成前端處理方法,其特征在于,所述編碼層為對所述預訓練語言模型進行蒸餾后的模型。
6.根據權利要求1所述的語音合成前端處理方法,其特征在于,所述韻律預測模型是基于以下步驟訓練得到的:
7.根據權利要求6所述的語音合成前端處理方法,其特征在于,所述基于所述文本數據集以及所述編碼向量進行模型訓練,得到所述韻律預測模型之后,包括:
8.一種語音合成前端處理裝置,其特征在于,包括:
9.一種電子設備,包括處理器和存儲有計算機程序的存儲器,其特征在于,所述處理器執行所述計算機程序時實現權利要求1至7任一項所述的語音合成前端處理方法的步驟。
10.一種非暫態計算機可讀存儲介質,其上存儲有計算機程序,其特征在于,所述計算機程序被處理器執行時實現權利要求1至7任一項所述的語音合成前端處理方法的步驟。
技術總結
本申請涉及計算機技術領域,提供一種語音合成前端處理方法、裝置、設備和存儲介質。該方法包括:對待處理文本進行切分,得到至少一個文字,基于預設字典確定每個文字對應的序號;將攜帶序號的待處理文本輸入至韻律預測模型,得到韻律預測模型輸出的韻律標簽和拼音標簽;其中,韻律預測模型是基于攜帶韻律標簽和拼音標簽的文本數據集,以及預設字典對應的編碼向量訓練得到的。本申請通過預訓練編碼,從預設字典中提取有關發音和韻律的編碼信息,并引入模型中,從而提高模型對多音字消歧任務的預測準確率;同時,通過韻律預測模型預測韻律標簽和拼音標簽,降低了推理復雜度,并提高了前端任務的準確率。
技術研發人員:柳瑞波,王帥鑫,劉壯壯,任玉玲,趙江江,李青龍
受保護的技術使用者:中移在線服務有限公司
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!