面向預訓練語言模型微調的參數高效型適配器微調方法
本發明屬于預訓練語言模型微調領域,具體涉及一種面向預訓練語言模型微調的參數高效型適配器微調方法。
背景技術:
1、近年來,預訓練語言模型已席卷人工智能的各個領域,并取得了巨大成功。預訓練語言模型適應下游任務的主流范式是微調。由于大多數預訓練語言模型如t5、gpt3都有大量的參數,因此對它們進行微調通常是昂貴且耗時的,并且存儲它們會占用大量空間,并且微調過程中存在大量冗余參數。因此,有必要在不影響預訓練語言模型在下游任務中的性能的情況下,減少微調中的參數規模。
2、現有的預訓練語言模型參數高效型微調主要包括三類方法,具體為適配器微調、前綴微調和提示符微調。適配器微調是將一個小型神經網絡模塊插入預訓練語言模型的每一層或某些層中進行微調的方法,在微調過程中,只需要學習這個小模塊的參數。前綴微調和提示符微調是在輸入或隱藏層中預設了額外的可調整前綴標記,在下游任務的微調過程中僅訓練這些軟提示。但是這些的參數高效型微調依舊需要眾多的參數,參數效率仍有改進的空間。
技術實現思路
1、本發明是為了解決上述問題而進行的,目的在于提供一種面向預訓練語言模型微調的參數高效型適配器微調方法。
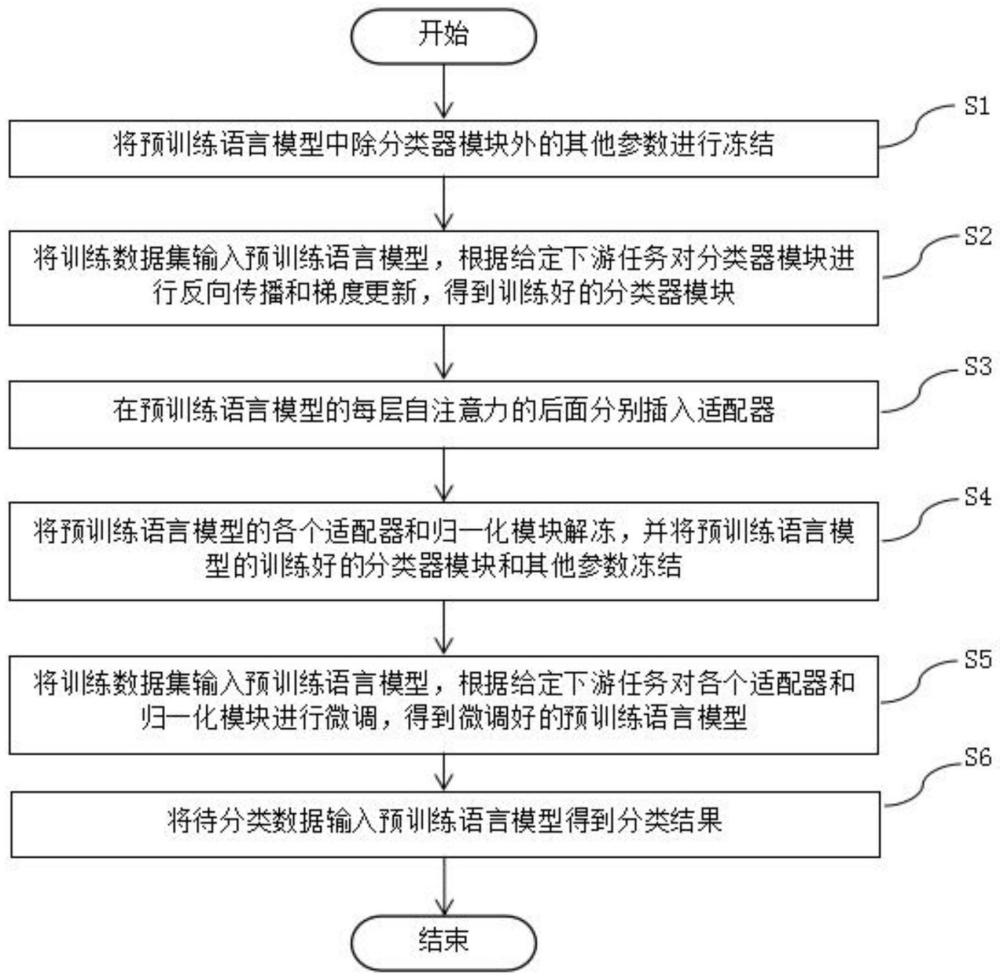
2、本發明提供了一種面向預訓練語言模型微調的參數高效型適配器微調方法,用于通過訓練數據集和適配器對給定下游任務的預訓練語言模型進行微調,將待分類數據輸入微調好的所述預訓練語言模型得到分類結果,具有這樣的特征,包括以下步驟:步驟s1,將預訓練語言模型中除分類器模塊外的其他參數進行凍結;步驟s2,將訓練數據集輸入預訓練語言模型,根據給定下游任務對分類器模塊進行反向傳播和梯度更新,得到訓練好的分類器模塊;步驟s3,在預訓練語言模型的每層自注意力的后面分別插入適配器;步驟s4,將預訓練語言模型的各個適配器和歸一化模塊解凍,并將預訓練語言模型的訓練好的分類器模塊和其他參數凍結;步驟s5,將訓練數據集輸入預訓練語言模型,根據給定下游任務對各個適配器和歸一化模塊進行微調,得到微調好的預訓練語言模型;步驟s6,將待分類數據輸入預訓練語言模型得到分類結果,其中,各個自注意力對應的適配器具有不同的參數,適配器的參數包括權重向量和偏置向量。
3、在本發明提供的面向預訓練語言模型微調的參數高效型適配器微調方法中,還可以具有這樣的特征:其中,適配器對對應的自注意力的輸出結果的處理過程為:適配器將輸入的輸出結果與權重向量按位相乘,相乘后的乘積與偏置向量按位相加,得到更新后自注意力輸出結果,適配器輸出更新后自注意力輸出結果。
4、在本發明提供的面向預訓練語言模型微調的參數高效型適配器微調方法中,還可以具有這樣的特征:其中,權重向量和偏置向量均為一維向量,權重向量和偏置向量的形狀與預訓練語言模型的隱藏層大小相同。
5、在本發明提供的面向預訓練語言模型微調的參數高效型適配器微調方法中,還可以具有這樣的特征:其中,在適配器微調前,對所有適配器的權重向量和偏置向量進行初始化,初始化后相當于在每層自注意力的后面未插入適配器。
6、在本發明提供的面向預訓練語言模型微調的參數高效型適配器微調方法中,還可以具有這樣的特征:其中,權重向量初始化為1.0,偏置向量初始化為0.0。
7、發明的作用與效果
8、根據本發明所涉及的面向預訓練語言模型微調的參數高效型適配器微調方法,因為通過在多頭注意力后插入對輸出結果逐元素進行線性變換的適配器,能夠減少微調的參數數量,所以,本發明的面向預訓練語言模型微調的參數高效型適配器微調方法能夠提高預訓練語言模型微調的參數效率。
技術特征:
1.一種面向預訓練語言模型微調的參數高效型適配器微調方法,用于通過訓練數據集和適配器對分類任務的預訓練語言模型進行微調,將待分類數據輸入微調好的所述預訓練語言模型得到分類結果,其特征在于,包括以下步驟:
2.根據權利要求1所述的面向預訓練語言模型微調的參數高效型適配器微調方法,其特征在于:
3.根據權利要求1所述的面向預訓練語言模型微調的參數高效型適配器微調方法,其特征在于:
4.根據權利要求1所述的面向預訓練語言模型微調的參數高效型適配器微調方法,其特征在于:
5.根據權利要求4所述的面向預訓練語言模型微調的參數高效型適配器微調方法,其特征在于:
技術總結
本發明提供了一種面向預訓練語言模型微調的參數高效型適配器微調方法,具有這樣的特征,包括以下步驟:步驟S1,將預訓練語言模型中除分類器模塊外的其他參數進行凍結;步驟S2,根據訓練數據集和給定下游任務對分類器模塊進行反向傳播和梯度更新,得到訓練好的分類器模塊;步驟S3,在預訓練語言模型的每層自注意力的后面分別插入適配器;步驟S4,將預訓練語言模型的各個適配器和歸一化模塊解凍,并將其他參數凍結;步驟S5,根據訓練數據集對各個適配器和歸一化模塊進行微調,得到微調好的預訓練語言模型;步驟S6,將待分類數據輸入預訓練語言模型得到分類結果。總之,本方法能夠提高預訓練語言模型微調的參數效率。
技術研發人員:陳昱妍,李直旭,肖仰華,樊哿
受保護的技術使用者:復旦大學
技術研發日:
技術公布日:2024/10/21
- 還沒有人留言評論。精彩留言會獲得點贊!